OpenLedger y la Extraña Sensación de que la IA Finalmente Podría Estar Chocando con el Mismo Muro.
He estado en el mundo cripto el tiempo suficiente para dejar de reaccionar cada vez que un proyecto dice que está "redefiniendo" algo.
La mayoría de las veces, esas palabras son solo embalaje reciclado alrededor de los mismos incentivos de siempre. Nuevo token, nueva marca, misma realidad subyacente: unos pocos insiders capturan el valor, la multitud proporciona liquidez, y eventualmente la narrativa se mueve a otro lugar.
Probablemente por eso me he vuelto más lento para emocionarme por cualquier cosa relacionada con la IA últimamente. El espacio ya se siente saturado con promesas exageradas. Cada semana hay otro protocolo que dice que va a descentralizar la inteligencia, tokenizar agentes, reinventar la computación o reemplazar el internet mismo. Después de un tiempo, todo se mezcla en el mismo ruido de fondo.
Pero de vez en cuando algo capta mi atención, no porque de repente crea en ello, sino porque parece centrarse en un problema que realmente existe.
OpenLedger es uno de esos proyectos para mí.
No estoy diciendo que funcione. No estoy diciendo que gane. Ni siquiera estoy diciendo que el modelo sea sostenible. Honestamente, aún no lo sé.
Pero sigo notando que la pregunta subyacente que se está haciendo se siente más real que la mayoría de las narrativas de IA que flotan en el cripto en este momento.
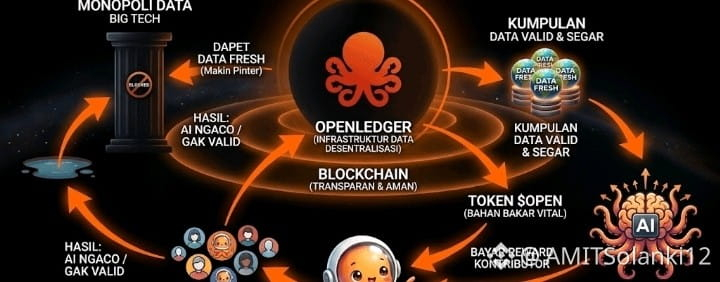
La pregunta es simple: si los modelos de IA se están convirtiendo en algunos de los sistemas más valiosos del mundo, ¿por qué casi nadie sabe de dónde proviene realmente el valor?
Eso suena obvio al principio, pero cuanto más profundizas en ello, más extraña comienza a parecer toda la economía de IA.
La mayoría de los sistemas de IA hoy en día están construidos sobre océanos de datos recopilados de personas que generalmente nunca ven compensación, propiedad o incluso reconocimiento. Escritores, artistas, investigadores, usuarios de foros, desarrolladores, comunidades de nicho, archivos aleatorios de internet — todo esto se absorbe en modelos que eventualmente se convierten en productos que valen miles de millones.
Y de alguna manera todos simplemente aceptaron que esto es normal.
Quizás porque los sistemas se volvieron demasiado grandes para cuestionar. Quizás porque las empresas que los construyen se movieron más rápido que la regulación. Quizás porque nadie podría rastrear la atribución de manera realista una vez que los modelos alcanzaron cierta escala.
Esa última parte importa.
Durante años, uno de los mayores problemas en la IA ha sido la atribución misma. Una vez que un modelo se entrena con suficientes datos, rastrear la influencia se vuelve borroso. Todo se convierte en una caja negra. A veces una caja negra útil, pero aún así una caja negra.
Esa es la parte que OpenLedger sigue rondando con esta idea de Prueba de Atribución.
El concepto suena casi demasiado ambicioso cuando lo lees por primera vez. El protocolo intenta conectar las salidas del modelo de nuevo a los datos que los influyeron, y luego recompensar a los contribuyentes proporcionalmente a través de la red.
He visto a cripto intentar cosas similares antes en diferentes formas. Regalías musicales. Economías de creadores. Incentivos de almacenamiento. Mercados de atención. Mercados de datos.
La mayoría de ellos eventualmente se estrelló contra la misma pared: medir la contribución de manera significativa es brutalmente difícil.#OpenAIToConfidentiallyFileForIPO $OPEN

#