
He pasado las últimas semanas profundizando en OpenLedger, no a través de clips de hype o hilos reciclados de Twitter, sino leyendo sus Datanets, la arquitectura de Prueba de Atribución, y la forma en que el protocolo piensa sobre la propiedad a lo largo de la pila de IA. Cuanto más tiempo pasaba con ello, más me di cuenta de algo importante:
OpenLedger no está tratando de competir en la carrera habitual de IA.
Está intentando rediseñar la estructura económica subyacente.
La mayoría de las conversaciones sobre IA hoy en día giran en torno a las mismas métricas superficiales:
modelos más grandes.
inferencia más rápida.
más computación.
más automatización.
Pero debajo de todo eso hay una pregunta mucho más silenciosa de la que casi nadie habla en serio:
¿Quién posee realmente la inteligencia que se está creando?
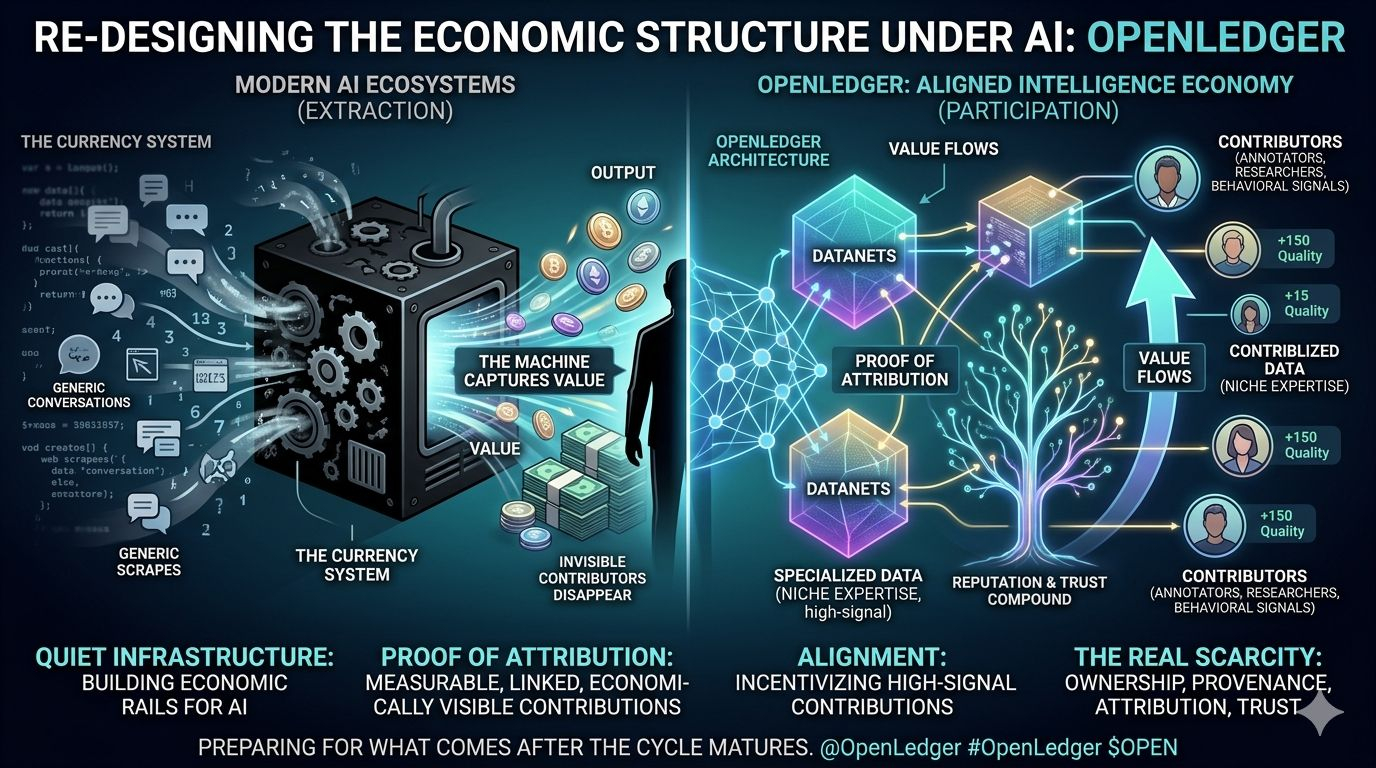
Esa pregunta se vuelve incómoda una vez que te das cuenta de cómo funcionan los sistemas de IA modernos. Los modelos se entrenan con enormes cantidades de contribuciones humanas: conjuntos de datos, anotaciones, investigación, experiencia en el dominio, señales de comportamiento, conversaciones, sin embargo, las personas que suministran ese valor suelen ser invisibles una vez que el modelo comienza a generar salida.
La máquina captura el valor.
Los contribuyentes desaparecen detrás de eso.
Esa es la parte que OpenLedger parece obsesionarse en arreglar.
Lo que me llamó la atención primero fue la idea de la Prueba de Atribución. En lugar de tratar las salidas de la IA como magia de caja negra, el sistema intenta rastrear qué conjuntos de datos y contribuyentes influyeron en el comportamiento del modelo y la generación de inferencias. Cada contribución se vuelve medible, vinculada y visiblemente económica.
A primera vista, eso podría sonar como un detalle técnico.
No creo que lo sea.
Creo que cambia fundamentalmente los incentivos.
Si los contribuyentes saben que la calidad de sus datos afecta directamente la atribución y las recompensas, el comportamiento cambia con el tiempo. Las personas se vuelven más cuidadosas con la curación. Los conjuntos de datos especializados se vuelven más valiosos. La reputación comienza a importar. El spam de baja calidad se vuelve económicamente más débil mientras que las contribuciones de alta señal se acumulan en valor.
Eso crea algo que la mayoría de los ecosistemas de IA actualmente carecen:
alineación.
Y la alineación importa más de lo que la gente piensa.
La mayoría de las plataformas hoy en día optimizan para la extracción. OpenLedger parece estar optimizando para la participación. Hay una diferencia entre usar a las personas para mejorar modelos y diseñar estructuralmente un sistema donde los contribuyentes permanezcan conectados al valor que su inteligencia crea.
Esa distinción se siente pequeña inicialmente.
Con el tiempo, se vuelve enorme.
Lo otro que me llamó la atención es cuánto énfasis pone OpenLedger en datos especializados en lugar de una escala genérica. La arquitectura alrededor de Datanets apunta hacia un ecosistema donde la experiencia de nicho se vuelve económicamente importante en lugar de ahogarse dentro de enormes modelos generalizados.
Creo que el mercado todavía subestima este cambio.
El futuro de la IA probablemente no pertenezca solo a los modelos más grandes.
Pertenece a las capas de inteligencia más confiables y especializadas.
Y la confianza se vuelve difícil sin atribución.
Por eso OpenLedger se siente menos como una startup de IA tradicional y más como infraestructura. La infraestructura silenciosa suele parecer poco impresionante al principio porque no depende del espectáculo. Pero la infraestructura a menudo es lo que sobrevive después de que los ciclos de hype colapsan.
Ese patrón se repite constantemente en la tecnología.
Las plataformas más ruidosas atraen atención primero.
Las capas de coordinación más profundas capturan valor más tarde.
Lo que hace esto aún más interesante es que OpenLedger no solo está construyendo herramientas, sino que está construyendo rieles económicos para la IA misma. Conjuntos de datos, modelos, inferencias, contribuyentes, agentes... todo comienza a formar parte de un sistema rastreable donde los flujos de valor pueden realmente ser auditados en lugar de adivinados.
Eso cambia cómo pienso sobre la IA a largo plazo.
Porque eventualmente la economía de la IA chocará con una pared donde la inteligencia por sí sola ya no es suficiente. Una vez que la IA se vuelva abundante, la propiedad, la procedencia, la atribución y la confianza se convertirán en la verdadera escasez.
Y los proyectos posicionados alrededor de esas capas pueden terminar importando mucho más de lo que la gente espera actualmente.
Cuando me detengo a observar, OpenLedger no parece estar persiguiendo el ciclo de la IA.
Se siente como si se estuviera preparando para lo que viene después de que el ciclo madure.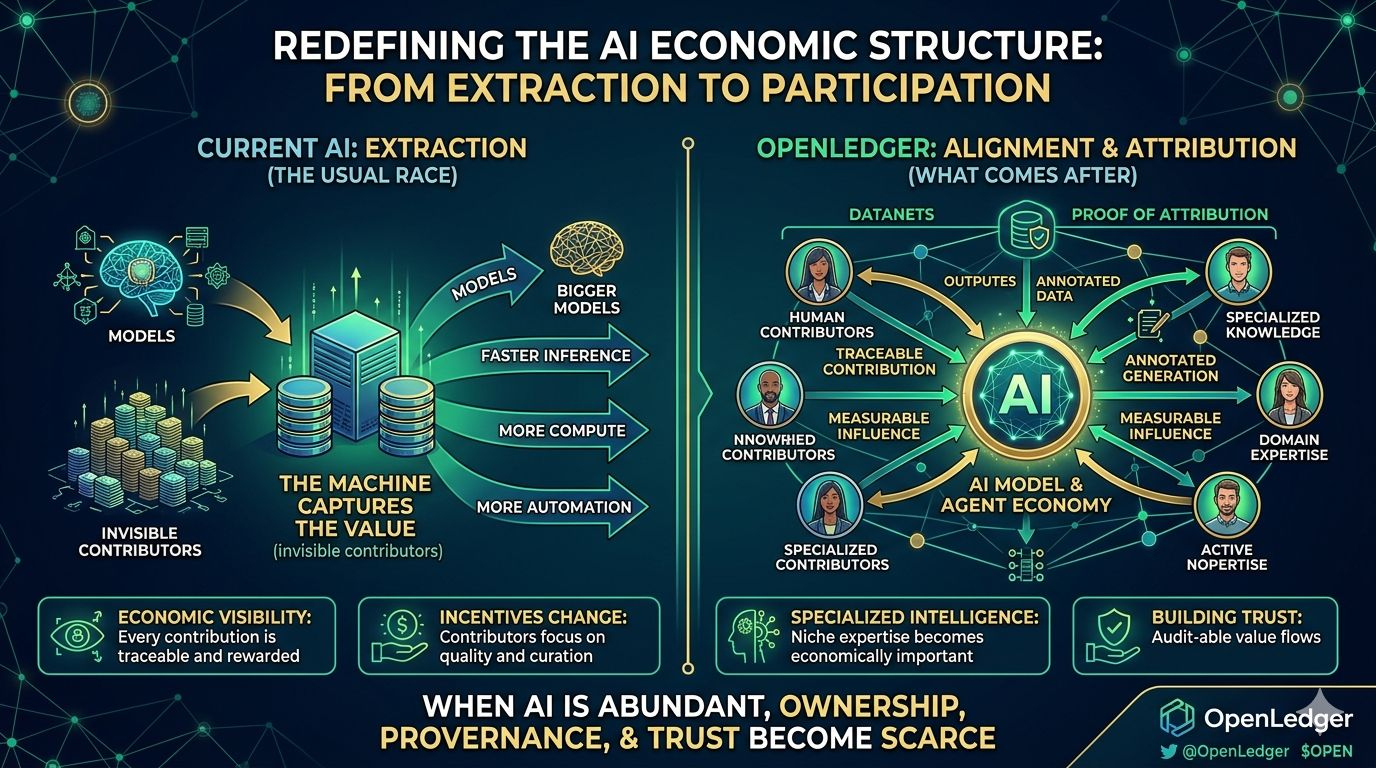
Por eso sigo prestándole atención.
No porque sea ruidosa.
Pero porque la arquitectura en silencio tiene sentido una vez que te sientas con ella el tiempo suficiente.
