He estado revisando la documentación de openledger, las notas de los validadores y algunos hilos de arquitectura últimamente, principalmente tratando de entender qué capa están realmente construyendo. La mayoría de la gente parece tratarlo como otra historia de token de ai + crypto, pero honestamente eso se siente demasiado superficial. Cuanto más lo miro, más parece que openledger está intentando construir un sistema de coordinación en torno a los datos de ai mismos — quién los contribuye, quién los verifica y quién recibe pagos cuando los modelos los utilizan más tarde.
Ese es un problema mucho más complicado que simplemente ejecutar inferencias en la cadena o activar computación descentralizada.
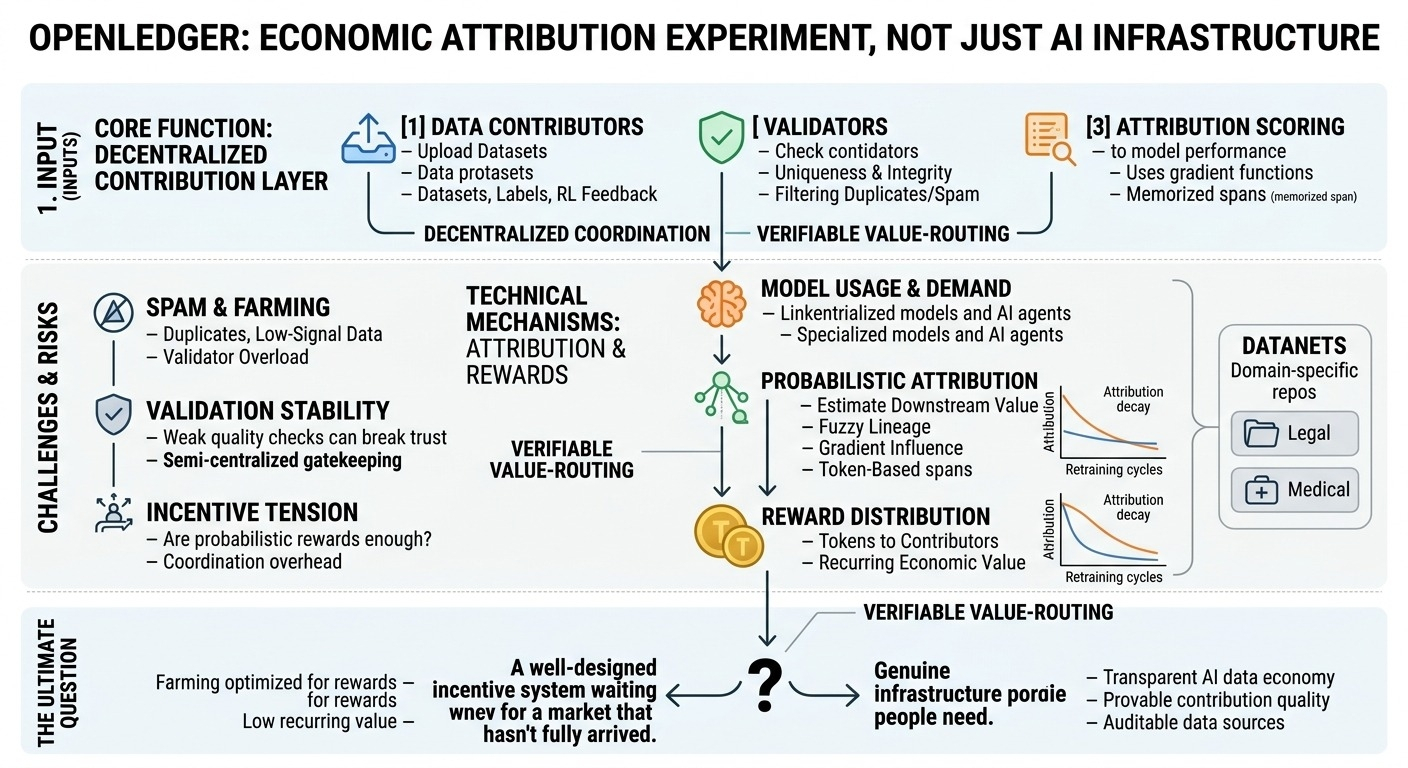
lo que me llamó la atención primero fue la capa de contribución descentralizada. los contribuyentes pueden enviar conjuntos de datos, etiquetas, conocimientos estructurados de dominio, tal vez incluso retroalimentación de refuerzo vinculada a las salidas del modelo. el protocolo luego intenta conectar esas contribuciones al rendimiento del modelo y a las recompensas económicas.
en teoría, esto crea una cadena de suministro de IA más abierta. en lugar de una plataforma cerrada que absorbe interacciones de usuarios y se reentrena en privado, obtienes una red donde los contribuyentes son participantes visibles en el bucle de valor.
pero luego la pregunta obvia aparece inmediatamente: ¿cómo demuestras la calidad de la contribución de una manera que la gente realmente confíe?
y esta es la parte en la que sigo pensando porque la atribución en los sistemas de IA no es clara. una vez que los conjuntos de datos se fusionan en pipelines de entrenamiento, se ajustan repetidamente o se mezclan con aumentaciones sintéticas, la línea de procedencia se vuelve difusa. tal vez no sea imposible de estimar, pero definitivamente es más difícil que la contabilidad al estilo blockchain donde cada transferencia es explícita.
openledger parece abordar esto a través de validadores y sistemas de puntuación de atribución vinculados al uso del modelo. si un conjunto de datos mejora significativamente las salidas, los contribuyentes reciben recompensas. conceptualmente tiene sentido. prácticamente, no estoy seguro de cuán estable se mantiene eso a gran escala.
supongamos que los contribuyentes suben resúmenes de casos legales que mejoran un modelo de cumplimiento especializado utilizado por empresas. tal vez esos resúmenes mejoren materialmente la precisión en casos jurisdiccionales oscuros. está bien. pero con el tiempo, después de múltiples ciclos de reentrenamiento y modelos derivados, ¿cómo continúa la red atribuyendo valor de manera justa? especialmente si la mejora es indirecta o distribuida entre miles de contribuyentes?
la arquitectura probablemente depende de la atribución probabilística en lugar de la trazabilidad perfecta. honestamente, eso puede ser inevitable. pero los sistemas de recompensa probabilística crean tensión de incentivos porque los contribuyentes necesitan creer que el proceso de puntuación es lo suficientemente legítimo como para seguir participando.
la capa del mercado también dice mucho sobre las suposiciones detrás del protocolo. openledger parece asumir que eventualmente habrá una demanda significativa por economías de datos de IA transparentes y atribuibles. tal vez tengan razón. las empresas que enfrentan presión regulatoria en torno a datos de entrenamiento con derechos de autor o no verificables pueden preferir fuentes de datos auditables eventualmente.
aún así, ese futuro no está garantizado.
los sistemas centralizados siguen siendo operativamente más simples en muchos aspectos. computación integrada, distribución, bucles de retroalimentación internos: todo más fácil de optimizar cuando una entidad controla la pila. los sistemas descentralizados generalmente compiten a través de la apertura y la alineación de incentivos, pero esas ventajas solo importan si suficientes participantes realmente se preocupan por la procedencia y la propiedad compartida.
el diseño del token es donde me vuelvo más cauteloso.
la red claramente necesita incentivos desde el principio. de lo contrario, los contribuyentes no proporcionarán conjuntos de datos de alto valor antes de que exista la demanda del mercado. pero las emisiones de tokens también pueden distorsionar el comportamiento rápidamente. si las recompensas superan la calidad de verificación, el sistema comienza a atraer contribuciones de bajo nivel optimizadas para la agricultura en lugar de la utilidad.
el spam parece ser un riesgo estructural real aquí. conjuntos de datos duplicados, basura sintética, datos públicos ligeramente modificados: todo económicamente racional si la validación es débil. entonces, los validadores se vuelven más importantes, lo que aumenta la carga de coordinación y tal vez incluso empuje a la red hacia un control semi-centralizado.
y, honestamente, todavía no tengo claro quién captura la mayor parte del valor si openledger tiene éxito. ¿contribuyentes? ¿validadores? ¿operadores de modelos? ¿proveedores de infraestructura? los sistemas de coordinación abierta tienden a sonar igualitarios al principio, pero la concentración económica generalmente aparece en algún lugar de la pila.
aún así, comparado con mucha infraestructura cripto relacionada con la IA, esto se siente direccionalmente más fundamentado. al menos el protocolo está apuntando a un problema legítimo de coordinación en torno a la atribución y la ruta de incentivos en lugar de asumir que la descentralización por sí sola crea valor.
observando:
- si la demanda real del modelo crece independientemente de los incentivos del token
- precisión en la atribución a medida que los conjuntos de datos y los modelos se vuelven más composicionales
- efectividad de los validadores contra spam o envíos de baja calidad
- cuánto valor económico recurrente realmente llega a los contribuyentes
supongo que la pregunta abierta es si openledger se convierte en una infraestructura que la gente realmente necesita, o si permanece como un sistema de incentivos bien diseñado esperando una estructura de mercado que aún no ha llegado completamente.