
Veo a OpenLedger (OPEN) como un protocolo que intenta situarse en la intersección de la infraestructura de IA y la coordinación basada en blockchain de datos, modelos y agentes autónomos. En mi evaluación de OpenLedger (OPEN), la tesis central parece ser que las entradas de IA valiosas—datasets, modelos entrenados y outputs de agentes—permanecen estructuralmente submonetizadas en sistemas centralizados, y que un libro mayor descentralizado podría teóricamente revalorizar y redistribuir ese valor. Soy escéptico sobre si OpenLedger (OPEN) está abordando una limitación técnica genuinamente no resuelta o si en cambio está reformulando un espacio problemático ya competitivo que incluye mercados de datos, sistemas de almacenamiento descentralizados y redes de computación de IA. La existencia de OpenLedger (OPEN) tiene sentido conceptual en un mundo donde la procedencia y la atribución importan, pero noto que la demanda real de licencias de datos en la cadena a gran escala sigue sin probarse fuera de ecosistemas de nicho.
Cuando analizo OpenLedger (OPEN) desde una perspectiva económica, veo un sistema que probablemente depende de fuertes incentivos en las etapas iniciales para fomentar la participación. En OpenLedger (OPEN), los "faucets" parecen ser recompensas impulsadas por emisiones para contribuyentes de datos, incentivos de liquidez para poseedores de tokens y subvenciones del ecosistema destinadas a atraer creadores y adoptantes tempranos. Estos faucets son típicos en protocolos emergentes, pero en OpenLedger (OPEN) generan preocupaciones sobre la expansión de la oferta que no se ve inmediatamente compensada por la generación orgánica de tarifas. Los "sinks" en OpenLedger (OPEN), como los requisitos de staking, tarifas por uso del protocolo o pagos por acceso a modelos, tendrían que ser fuertes y recurrentes para compensar la inflación, sin embargo, no veo evidencia clara de que estos sinks sean estructuralmente dominantes en lugar de aspiracionales. Esto crea un posible desbalance en OpenLedger (OPEN), donde la velocidad del token está más influenciada por la emisión que por la demanda sostenida, lo que a su vez arriesga debilitar la estabilidad económica a largo plazo.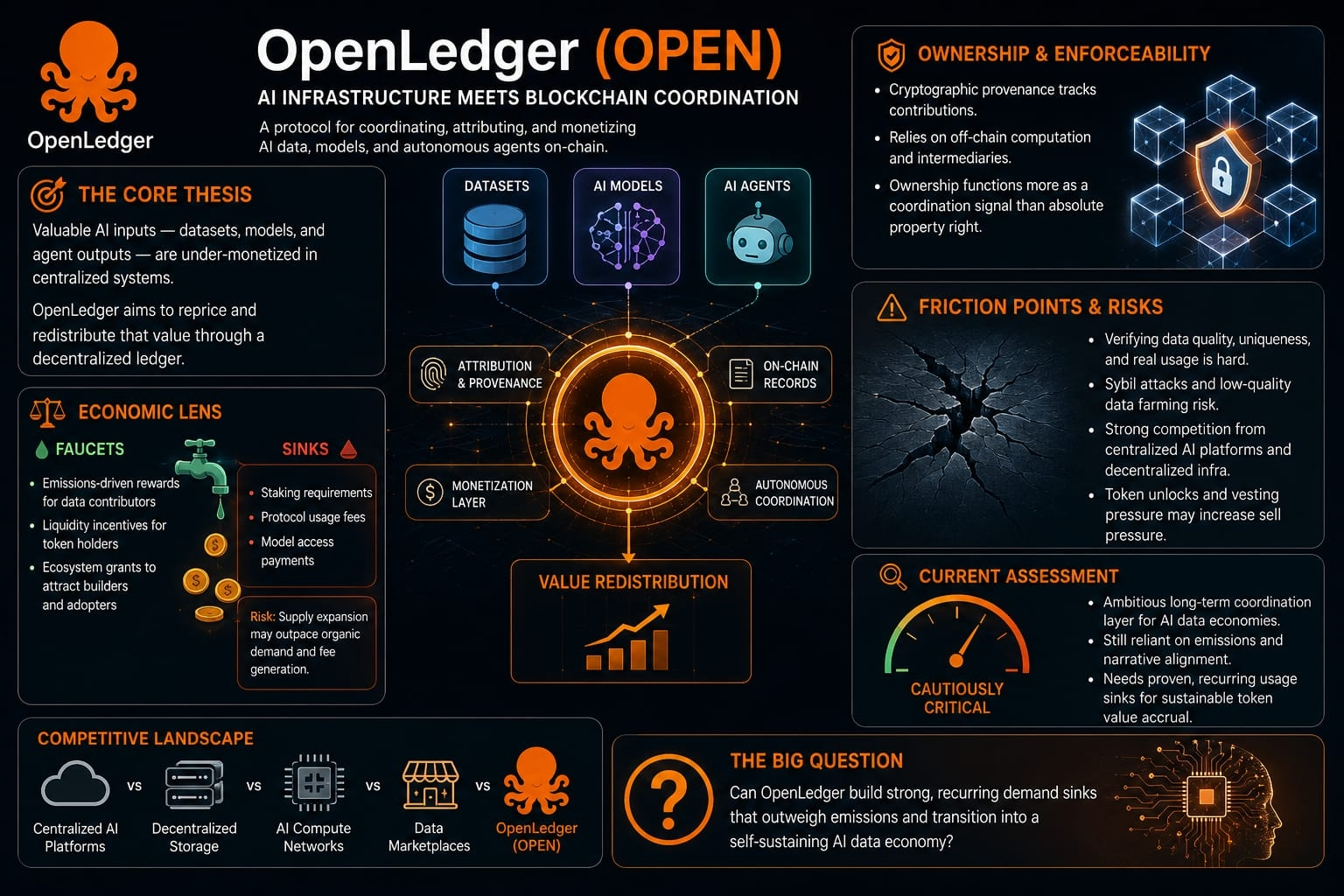
Desde una perspectiva de coordinación y propiedad, OpenLedger (OPEN) presenta una narrativa ambiciosa sobre la soberanía del usuario sobre los datos, modelos y outputs derivados de agentes. En la práctica, sin embargo, noto que OpenLedger (OPEN) debe depender de sistemas de verificación en capas, computación fuera de la cadena y intermediarios para hacer que la atribución sea significativa y exigible. Esto introduce una brecha entre el concepto de propiedad y su real exigibilidad dentro de OpenLedger (OPEN), especialmente cuando los datos son transformados, agregados o usados en pipelines de aprendizaje automático donde la línea de origen se vuelve probabilística en lugar de absoluta. Incluso si OpenLedger (OPEN) implementa seguimiento criptográfico de la procedencia, sigo siendo escéptico de que esto por sí solo se traduzca en derechos económicos exigibles sin depender de marcos de arbitraje legales externos o centralizados. Como resultado, la propiedad en OpenLedger (OPEN) corre el riesgo de funcionar más como una señal de coordinación que como un régimen de propiedad completamente realizado.
También veo varios puntos de fricción y riesgos estructurales en OpenLedger (OPEN) que podrían afectar la viabilidad a largo plazo. Un problema importante es la verificación: OpenLedger (OPEN) debe determinar si los datos contribuidos son únicos, de alta calidad y realmente utilizados en procesos de IA posteriores, lo cual es inherentemente difícil de validar sin introducir intermediarios de confianza. Esto crea una posible superficie de ataque para el comportamiento Sybil o la agricultura de datos de baja calidad, especialmente si los incentivos permanecen fuertes en OpenLedger (OPEN) mientras que los costos de verificación siguen siendo bajos. También observo que OpenLedger (OPEN) opera en un entorno macro altamente competitivo donde las plataformas de IA centralizadas ya controlan la distribución, y las alternativas descentralizadas están compitiendo por las capas de computación y datos. Sin una clara dominancia en ningún nicho, OpenLedger (OPEN) corre el riesgo de ser aplastado entre competidores pesados en infraestructura y sistemas de IA en la capa de aplicación. También sigo siendo cauteloso sobre la dinámica de desbloqueo de tokens en OpenLedger (OPEN), ya que cualquier presión significativa futura de vesting sin sinks de demanda que coincidan podría introducir una presión de venta sostenida.
Mi evaluación final de OpenLedger (OPEN) es cautelosamente crítica en lugar de despectiva. Reconozco que OpenLedger (OPEN) está intentando construir una capa de coordinación a largo plazo para las economías de datos de IA, que es un objetivo de diseño legítimo y visionario. Sin embargo, aún no veo evidencia sólida de que OpenLedger (OPEN) haya resuelto la tensión económica fundamental entre el crecimiento impulsado por incentivos y la generación de demanda sostenible. El sistema aún parece depender en gran medida de emisiones tempranas y alineación narrativa en lugar de sinks de uso probados y recurrentes que justificarían la acumulación de valor duradero de tokens. Por esa razón, actualmente veo a OpenLedger (OPEN) como un sistema de coordinación experimental temprano con una ambición conceptual significativa, pero que aún necesita demostrar que sus bucles económicos pueden sobrevivir más allá de los incentivos de arranque y transitar hacia una demanda de mercado autosostenible.