Solía tener una carpeta de marcadores llamada 'Herramientas de IA que debería probar de nuevo'.
Suena muy organizado. En realidad, es más como un pequeño cementerio. Conservo muchas herramientas, agentes, chatbots, plugins porque cuando se lanzan, todos parecen interesantes. Demostraciones atractivas. Hilos de análisis extensos. Hay algunos que me hacen pensar: “Sí, este seguro lo usaré frecuentemente.”
Entonces no lo abriré de nuevo.
No es que estén rotos o no funcionen bien. Es mucho más simple: no son lo suficientemente necesarios para entrar en mi rutina.
Cuando leí sobre OpenLedger, esa sensación regresó de una manera más seria.
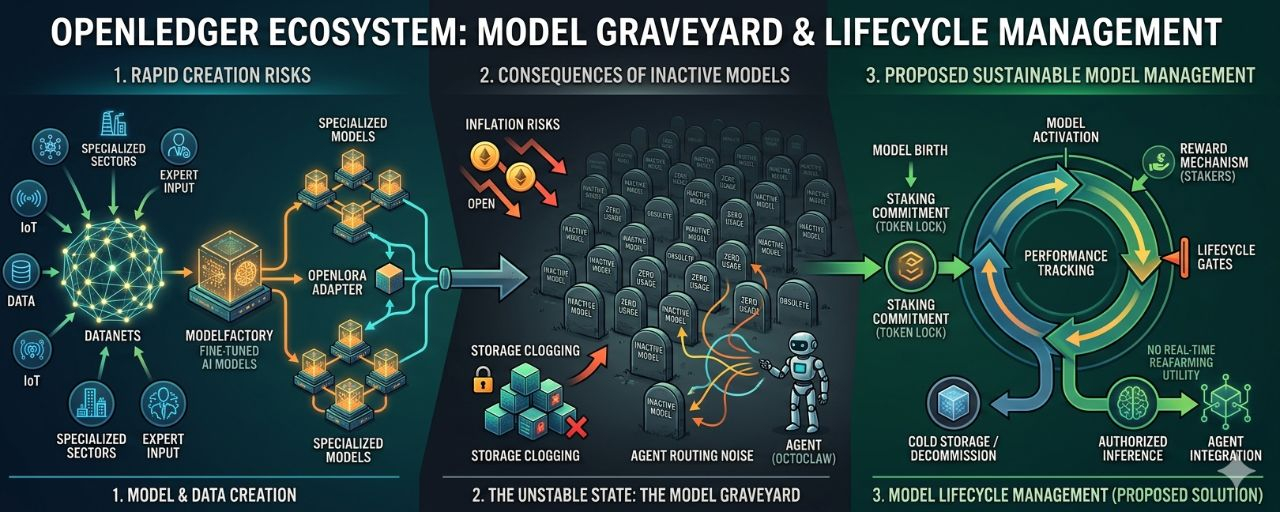
OpenLedger está construyendo un ecosistema para modelos de IA especializados: hay Datanets para recopilar datos específicos, ModelFactory para afinar, OpenLoRA para servir múltiples modelos de manera más eficiente, Proof of Attribution para registrar contribuciones, y pago de inferencias para que los modelos generen ingresos. Este es un pipeline muy lógico.
Pero precisamente porque ese pipeline es lógico, el riesgo detrás es aún más aterrador.
Si crear modelos se vuelve más fácil, si los datos se recopilan más rápido, si cada comunidad puede iniciar un modelo especializado, entonces la pregunta ya no es '¿hay suficientes modelos?'
La pregunta es: ¿cuántos de esos modelos realmente merecen existir?
Yo llamo a este problema el Cementerio de Modelos.
Un cementerio de modelos no es solo un lugar con muchos modelos que nadie usa. Si solo fuera eso, sería bastante inofensivo. Lo peor es que el dashboard se ve un poco mal, algunos proyectos son olvidados, y algunas personas pierden tiempo.
Pero en una IA blockchain como OpenLedger, los modelos muertos no se quedan quietos.
Eso deja un costo.
El primer costo es la inflación de incentivos. Si el sistema sigue dando recompensas a demasiados modelos que aún no han demostrado una demanda real, los tokens se verán arrastrados a mantener una oferta falsa. Los contribuyentes ven las recompensas, así que siguen creando más datos, más modelos, más actividad. Pero esa actividad no necesariamente genera inferencias reales. Cuando las recompensas están demasiado lejos de la demanda, los tokens dejan de ser una señal de valor. Se convierten en combustible para mantener la ilusión de que el ecosistema está creciendo.
El segundo costo es la congestión del Almacenamiento Caliente. Un modelo que nadie usa aún puede ocupar metadata, historial de versiones, adaptadores, trazas de atribución, estado de hospedaje, y capas de datos para servir inferencias. No todo debería mantenerse en estado caliente solo porque alguna vez fue lanzado. Si todos los modelos se tratan como activos vivos, el sistema pronto tendrá que pagar los costos de activos muertos.
El tercer costo es el que considero más peligroso: el ruido en el Enrutamiento de Agentes.
El futuro de OpenLedger no es solo que los usuarios seleccionen modelos manualmente. El proyecto ha introducido a OctoClaw como una capa de agente que puede construir, automatizar y ejecutar flujos de trabajo en tiempo real. Esto hace que la pregunta sobre modelos muertos sea aún más crítica. Un agente no puede operar basado en intuiciones. Debe llamar al modelo, seleccionar un adaptador, acceder a datos, invocar herramientas y decidir qué fuente es confiable en cada contexto.
Cuando el ecosistema está inundado con un cementerio de modelos, agentes como OctoClaw pueden verse arrastrados a señales erróneas: un adaptador que alguna vez fue muy rentable, un modelo que tuvo alta atribución pero su utilidad ha muerto, una fuente de datos antigua que aún se encuentra en el camino caliente porque nadie se atreve a degradarla.
En ese momento, el problema ya no es 'este modelo no lo usa nadie'.
El problema es que un modelo muerto aún puede interferir en la toma de decisiones de un agente que realmente está funcionando.
Por lo tanto, si solo se dice 'crear un modelo cuando haya suficiente demanda', sigue siendo un poco suave. OpenLedger necesita un mecanismo más fuerte para gestionar el ciclo de vida económico de los modelos.
Un modelo no debería solo tener una fecha de nacimiento. Debe tener longevidad, obligaciones de mantenimiento, señales de vida, y un mecanismo para enterrarse a sí mismo si ya no genera valor.
La forma de hacerlo podría comenzar con el staking.
Si una comunidad cree que un modelo especializado realmente tiene demanda, no solo votan o contribuyen con datos. Tienen que hacer stake $OPEN en esa tesis. El stake aquí no es solo dinero. Es un compromiso de que este modelo merece ocupar almacenamiento, atención de enrutamiento, esfuerzo de validación y presupuesto de recompensas del ecosistema.
Luego, el modelo debe demostrar que sigue vivo con datos de uso reales: inferencias pagadas, uso repetido, retención después de incentivos, finalización de tareas, validación de dominio, y la capacidad de ser seleccionado nuevamente por sistemas como OctoClaw debido a su efectividad real y no por ruido.
Si el modelo cumple, los stakers y contribuyentes son recompensados. Si no lo hace, parte del stake se somete a slashing. El modelo es relegado en prioridad en el enrutamiento, se transfiere a almacenamiento frío, o pierde el derecho a recompensas extendidas para liberar recursos para aquellos agentes y flujos de trabajo que aún generan valor real.
Dicho de manera directa: el ecosistema OpenLedger necesita una forma de que los modelos muertos paguen su propio entierro.
Por supuesto, este mecanismo no es perfecto. El staking puede perjudicar a ideas pequeñas, ya que no tienen suficiente capital para demostrar demanda temprano. El slashing puede hacer que la comunidad evite experimentar. Algunos modelos especializados con bajo uso pero alto valor también pueden ser mal evaluados si la métrica es demasiado burda.
Pero no tener gestión del ciclo de vida es aún más peligroso.
Porque en ese momento OpenLedger podría crear algo que muchos ecosistemas Web3 han enfrentado: una ciudad iluminada en la superficie, pero llena de casas abandonadas por dentro. Muchos modelos. Mucha actividad. Muchas atribuciones. Pero los agentes no saben en qué confiar, los tokens son arrastrados a mantener algo que ya no está vivo, y el almacenamiento se convierte en un archivo de recuerdos de experimentos que nadie se atreve a borrar.
Una IA en blockchain no puede solo preguntarse cómo crear más modelos.
Debe atreverse a preguntar qué modelos deben ser alimentados, cuáles deben ser degradados, y cuáles deben morir.
Si @OpenLedger quiere convertirse en la infraestructura para IA especializada de verdad, esta es una pregunta que no se puede evitar: ¿el proyecto está construyendo una economía de modelos vivos, o está financiando un cementerio de modelos que saben gastar tokens?