En la mayoría de los sistemas de IA, los datos entran al modelo y desaparecen de la vista. Esa es la parte a la que sigo volviendo cuando pienso en OpenLedger. Los productos de OpenLedger.AI a menudo lucen limpias por fuera. Un usuario hace una pregunta. Un modelo da una respuesta. Tal vez la respuesta sea útil, tal vez no. Pero detrás de esa interacción simple hay una realidad mucho más desordenada: los datos tuvieron que ser recolectados, limpiados, etiquetados, refinados, organizados y probados antes de que el modelo se volviera útil.$OPEN #OpenLedger @OpenLedger
El problema es que la mayor parte de este trabajo se vuelve invisible. Un investigador legal puede proporcionar ejemplos de contratos útiles. Un experto en finanzas puede organizar datos de riesgo. Un equipo médico puede limpiar información específica del dominio. Un desarrollador puede mejorar un conjunto de datos para que un modelo responda mejor en un área específica. Pero una vez que esa entrada entra en el pipeline de IA, a menudo se absorbe en el modelo sin un registro claro de quién contribuyó con qué, cuán útil se volvió, o si creó valor más adelante.
Esa es la fricción práctica que OpenLedger está tratando de abordar. Para mí, la idea más sólida de OpenLedger no es simplemente "IA más blockchain." Esa frase es demasiado amplia y fácil de repetir. El argumento más interesante es que los datos de entrenamiento no deberían ser tratados como una entrada oculta de una sola vez. Deberían ser tratados más como un activo económico rastreable.
En términos simples, OpenLedger está haciendo una pregunta seria: Si los datos ayudan a un sistema de IA a crear valor, ¿debería esa contribución ser visible, medible y recompensable?
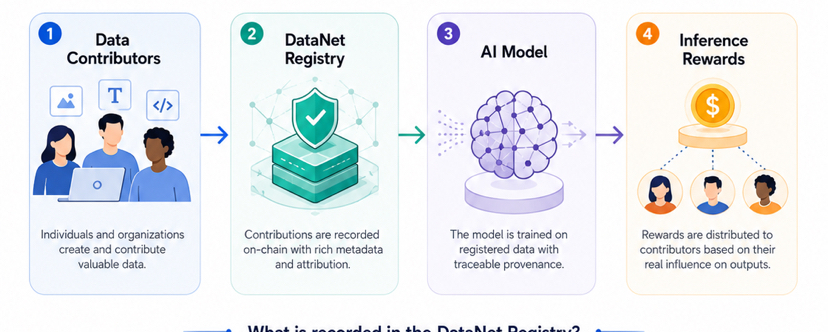
Ahí es donde los DataNets se vuelven importantes. Los DataNets están diseñados para organizar conjuntos de datos especializados alrededor de dominios o casos de uso específicos. En lugar de tratar los datos como un montón aleatorio de información, la idea es hacer que la contribución sea más estructurada. Un conjunto de datos puede tener registros sobre quién lo contribuyó, cuándo se añadió, qué términos se aplican a él y cómo se conecta al uso del modelo más tarde.
Eso suena básico al principio, pero en IA, esa capa básica a menudo falta. Aquí importan algunos puntos de prueba. Primero, el registro de DataNet le da a los conjuntos de datos un lugar más claro dentro del sistema. Esto es importante porque si los datos van a convertirse en un activo, necesita algún tipo de identidad visible. No puedes construir una capa de incentivos seria alrededor de algo que no tiene un registro claro.
En segundo lugar, la identidad del contribuyente le da al sistema una forma de conectar los datos de vuelta a las personas o equipos detrás de ellos. Esto no resuelve automáticamente todos los problemas de recompensa, pero crea un mejor punto de partida que el habitual pipeline de modelo de caja negra.
En tercer lugar, las marcas de tiempo son importantes porque ayudan a mostrar cuándo una contribución ingresó al sistema. En mercados de IA de rápido movimiento, el tiempo puede ser importante. Si un conjunto de datos mejora un modelo antes de que un caso de uso específico se vuelva valioso, esa historia no debería simplemente desaparecer.
Cuarto, los términos de licencia son importantes porque los datos no son solo técnicos. También son legales y económicos. Si los contribuyentes quieren compartir información útil, necesitan reglas más claras sobre cómo se pueden usar esos datos y qué tipo de valor podría volver a ellos.
Quinto, los registros de atribución son el verdadero corazón de la idea. OpenLedger no solo está intentando almacenar datos. Está tratando de conectar la influencia de los datos con el uso futuro del modelo, especialmente cuando el modelo produce resultados durante la inferencia.
Un ejemplo simple hace esto más fácil de entender. Imagina un grupo de investigadores legales que construyen un conjunto de datos limpio alrededor de cláusulas contractuales. Incluye ejemplos de lenguaje de riesgo, cláusulas de terminación, términos de renovación, secciones de responsabilidad y redacción específica de la jurisdicción. Este conjunto de datos no es masivo en comparación con los datos generales de internet, pero es altamente útil para una tarea específica: la revisión de contratos.
Ahora imagina que un modelo de IA para revisión de contratos usa ese conjunto de datos durante el entrenamiento o la refinación. Más tarde, las empresas usan el modelo para revisar acuerdos reales. Si el conjunto de datos legales ayudó al modelo a entender el riesgo de las cláusulas con más precisión, entonces la idea de OpenLedger es que esta contribución no debería desaparecer. El conjunto de datos debería tener un registro. El contribuyente debería tener un rastro. Y si esos datos siguen influyendo en resultados útiles, las recompensas deberían poder fluir de vuelta hacia las personas que ayudaron a crear ese valor.
Ese es el cambio económico. En los sistemas de IA normales, el modelo captura la atención. En el marco de OpenLedger, los datos detrás del modelo también se convierten en parte de la capa de valor. Esto importa para el cripto porque el cripto es mejor cuando hace que la propiedad, la coordinación y los incentivos sean más transparentes. La IA tiene un gran problema de coordinación. Muchas personas pueden mejorar un sistema, pero solo unas pocas plataformas suelen capturar el potencial. Si OpenLedger puede hacer visible la contribución y conectarla a recompensas, le da al cripto un rol más práctico en la IA que simplemente lanzar otro token alrededor de una narrativa de moda.
También importa para los usuarios y constructores. Para los usuarios, mejores incentivos de datos podrían significar sistemas de IA especializados más efectivos con el tiempo. Las personas pueden contribuir con más cuidado cuando saben que su trabajo puede ser rastreado y recompensado. Para los constructores, podría crear una razón más sólida para desarrollar conjuntos de datos nicho en lugar de solo perseguir el tamaño del modelo. Un conjunto de datos más pequeño, limpio y útil puede ser más valioso que uno grande pero desordenado.
Pero también hay un verdadero intercambio. OpenLedger tiene que separar la influencia genuina de los datos del simple volumen de datos. Eso no es fácil. Si el sistema recompensa principalmente a las personas por subir la mayor cantidad de datos posible, probablemente solo alentará el spam, cosas de baja calidad, toneladas de duplicados y contribuciones superficiales que realmente no añaden mucho valor. En ese caso, la capa de incentivos se volvería ruidosa en lugar de útil. El verdadero desafío es medir si los datos realmente mejoran el rendimiento del modelo, no solo si existen dentro del sistema.
Eso es lo que estoy observando a continuación. Quiero ver si OpenLedger puede demostrar que la atribución funciona en el uso real de IA, no solo en teoría. ¿Puede mostrar qué conjuntos de datos realmente mejoraron los resultados? ¿Pueden los contribuyentes entender por qué fueron recompensados? ¿Pueden los constructores confiar en los registros? ¿Puede el sistema manejar dominios especializados donde la calidad importa más que la escala?
Porque la mayor oportunidad aquí no es solo convertir datos en un activo. La mayor oportunidad es convertir datos útiles en un activo con un precio más justo.
Esa distinción importa. Si OpenLedger puede hacer que los datos de alta calidad sean más valiosos que los datos subidos en masa, entonces podría impulsar los incentivos de IA en una dirección más saludable. En lugar de recompensar a quien más información vierte en el sistema, el mercado podría comenzar a recompensar a las personas que proporcionan datos que realmente mejoran los modelos. Y esa es la verdadera pregunta para mí:
¿Puede OpenLedger construir una economía de IA donde los datos de calidad ganen más que el volumen de datos?$OPEN #OpenLedger @OpenLedger 
Artículo
¿Puede OpenLedger convertir los datos en un verdadero activo de IA?

--
Aviso legal: Contiene opiniones de terceros. Esto no constituye asesoramiento financiero. Es posible que incluya contenido patrocinado. Consultar Términos y condiciones.