Pasé noches tratando de averiguar qué está haciendo realmente OpenLedger detrás de las escenas. Quiero decir, qué está realmente ocurriendo debajo de la interfaz y las publicaciones positivas. No la historia que le cuentan al público. La forma real en que funciona.
La mayoría de los sistemas de criptomonedas quieren hablar sobre qué tan rápido son y cuánta gente los está usando. Quieren que los usuarios se enfoquen en las recompensas que pueden obtener porque es más fácil de entender que los problemas que están tratando de resolver. OpenLedger parece ser diferente porque lo que están construyendo es realmente difícil de explicar en términos... Quizás por eso la mayoría de los proyectos ni siquiera intentan construirlo.
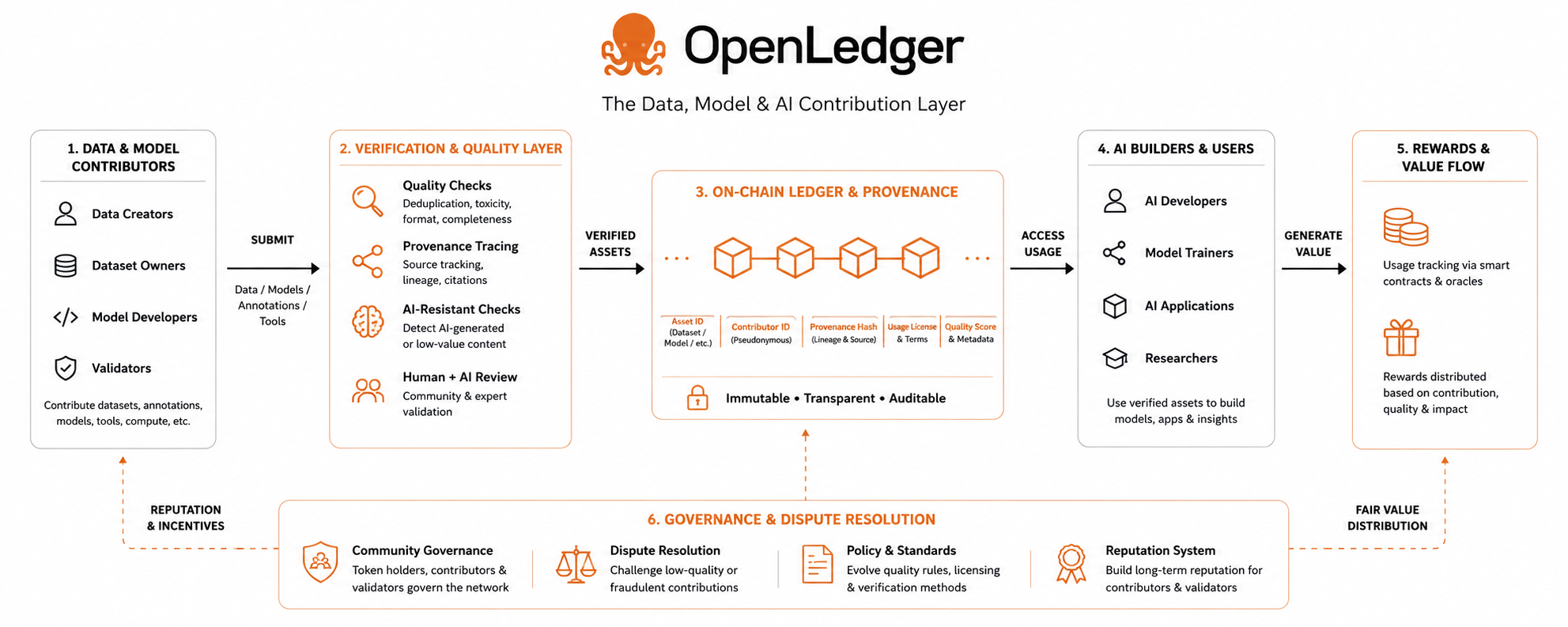
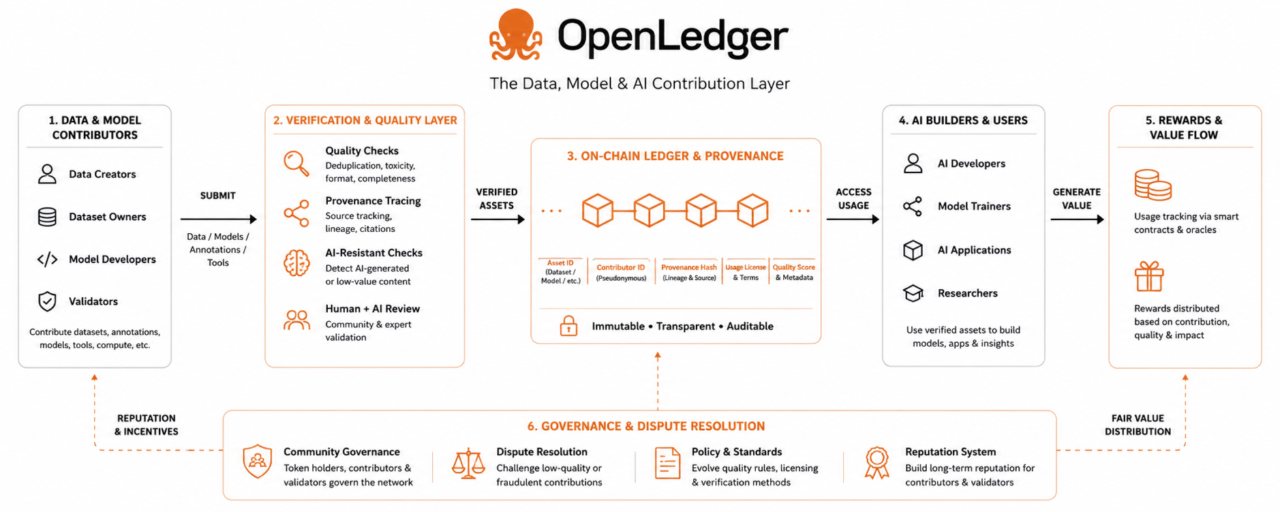
Empecé a notar esto cuando vi cómo manejan los datos que los usuarios aportan a la red. Usualmente, cuando una plataforma dice que los usuarios son dueños de sus datos, en realidad no significa nada. La plataforma aún controla quién puede verlo. Aún deciden cómo se puede usar para generar dinero. OpenLedger parece estar intentando resolver el problema de cómo llevar un registro de quién contribuyó con qué a los sistemas de inteligencia.
Eso suena simple. Cuando lo piensas, se vuelve realmente complicado. ¿Quién realmente creó algo? ¿Quién entrenó la inteligencia? ¿Qué conjunto de datos se utilizó para enseñarlo? ¿Cómo deberían distribuirse las recompensas a lo largo del tiempo? ¿Cómo podemos asegurarnos de que las personas estén usando el sistema honestamente sin revelar información?
La mayoría de los proyectos ni siquiera intentan responder estas preguntas porque son realmente difíciles de resolver. Lo comparé con cómo funcionan los sistemas de inteligencia artificial. Alguien sube información y luego el sistema la utiliza... Después de eso, la conexión entre la persona que lo creó y el valor que tiene se pierde.
Nadie lleva un registro de lo que le sucede después porque es demasiado complicado. Requeriría mucho trabajo construir un sistema que pueda hacer eso. También significaría ser responsable de lo que le suceda a los datos. OpenLedger parece estar asumiendo ese desafío.
Eso es lo que llamó mi atención. No porque crea que definitivamente tendrán éxito, sino porque están intentando resolver un problema que la mayoría de la gente evita. Noté otra cosa sobre cómo funciona su sistema. Parece estar más enfocado en verificar que los datos sean reales y útiles que en simplemente recopilar la mayor cantidad de datos posible.
Eso cambia la forma en que las personas son recompensadas por contribuir. Muchos proyectos de inteligencia artificial solo quieren obtener tantos datos como puedan, pero OpenLedger parece preocuparse más por asegurarse de que los datos sean buenos y utilizables. Al menos eso es lo que parece hasta ahora.
En teoría suena genial... En la práctica es mucho más complicado. Los sistemas que intentan verificar todo siempre suenan bien hasta que tienen que manejar a muchos usuarios. Entonces la gente comienza a encontrar formas de hacer trampa en el sistema. Se vuelve político.
Hay ejemplos de sistemas de criptomonedas que parecían justos al principio, pero luego fueron manipulados. Ese riesgo sigue presente con OpenLedger. No creo que haya suficientes personas hablando de eso honestamente. Cuando hay dinero de por medio, la gente deja de comportarse y comienza a intentar obtener tantas recompensas como pueda, incluso si eso significa contribuir con algo que no es realmente útil.
Seguí preguntándome cómo manejará OpenLedger eso a largo plazo. Especialmente cuando la inteligencia artificial comience a crear sus propios datos y se vuelva más difícil distinguir qué es real y qué no. Eso ya es un problema. Va a empeorar.
Si los sistemas de inteligencia artificial comienzan a entrenarse con datos que fueron creados por sistemas de inteligencia artificial, entonces la calidad de los datos empeorará cada vez más. Algunos investigadores ya están hablando sobre este problema. No está recibiendo suficiente atención.
Así que otra pregunta es, ¿cómo asegurará OpenLedger que los datos sean originales y valiosos sin volverse demasiado restrictivos? No creo que haya una respuesta para eso... Al menos parecen ser conscientes del problema y están tratando de resolverlo.
La mayoría de los sistemas hoy en día simplemente asumen que todos los datos son iguales y eso no es cierto. También noté que OpenLedger no pasa mucho tiempo hablando sobre cuán descentralizados son. Eso fue refrescante porque muchos proyectos de blockchain hacen que suene como si ser descentralizado los hiciera confiables.
La realidad es más complicada que eso. Solo porque un sistema sea descentralizado no significa que sea justo o confiable. OpenLedger parece estar más enfocado en asegurarse de que su sistema sea auditado que en solo hablar de descentralización.
Eso es importante porque si las economías de inteligencia artificial se vuelven tan grandes como la gente piensa, entonces alguien necesitará llevar un registro de dónde proviene el valor y hacia dónde va. Sin eso, todo el sistema se basará en extraer valor de los contribuyentes sin darles nada a cambio.
Quizás OpenLedger lo logre. Quizás no... Al menos están tratando de resolver un problema real en lugar de solo crear un producto blockchain inútil. Sin embargo, había algunas cosas que no me gustaban del sistema.
Algunas partes de ello aún estaban sin terminar. Era difícil entender cómo funcionaba sin leer muchas explicaciones. Eso dificulta que nuevos usuarios se unan porque tienen que aprender mucho antes de poder incluso comenzar a usarlo.
Honestamente, ese podría ser su mayor desafío. No la tecnología, sino la comunicación. Porque lo que están construyendo es algo que es difícil de explicar y se encuentra entre la inteligencia artificial, los mercados de datos y los sistemas de contabilidad blockchain.
Eso no es fácil de explicar en una sola frase a las personas que no están familiarizadas con la terminología de criptomonedas. Seguí pensando en cómo los productos de criptomonedas exitosos simplificaron las cosas, incluso si la tecnología detrás de ellos era complicada.
OpenLedger aún se siente como un sistema más complicado de lo que debería ser. Quizás eso mejore más adelante. Tal vez siempre será un problema. Una cosa que me gusta, sin embargo, es que el proyecto sigue enfocándose en la capa de sistemas de inteligencia artificial.
No es lo elegante. La demo, pero la economía subyacente. Quién contribuye, quién verifica, quién recibe recompensas y quién pierde propiedad con el tiempo. Esa es la parte que es difícil de observar porque cuando comienzas a examinarla de cerca, la mayoría de los sistemas de inteligencia artificial actuales comienzan a parecer incompletos.
Quizás por eso no muchos equipos están trabajando en ese problema. Porque el trabajo duro que necesita hacerse por debajo de la superficie no recibe tanta atención como el producto pulido que está encima.
\u003cm-44/\u003e\u003cc-45/\u003e\u003ct-46/\u003e