Los proyectos de IA hablan sobre el entrenamiento.
Pocos hablan sobre lo que sucede después de que termina el entrenamiento.
Esa brecha ha estado en mi mente mientras veo OpenLedger.
Honestamente, el entrenamiento es ahora la parte clave.
* Los datos se recopilan en todas partes.
* Los modelos se entrenan en todas partes.
* La gente alquila GPUs y ajusta modelos.
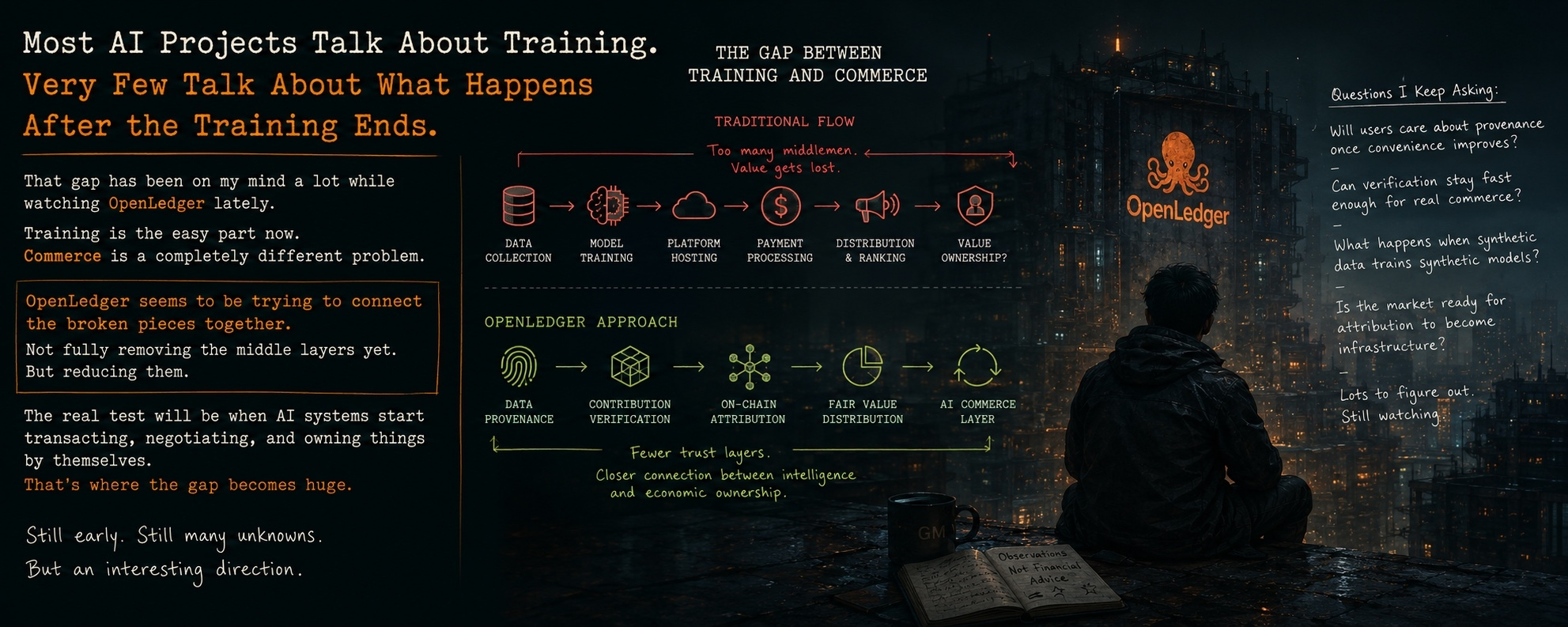
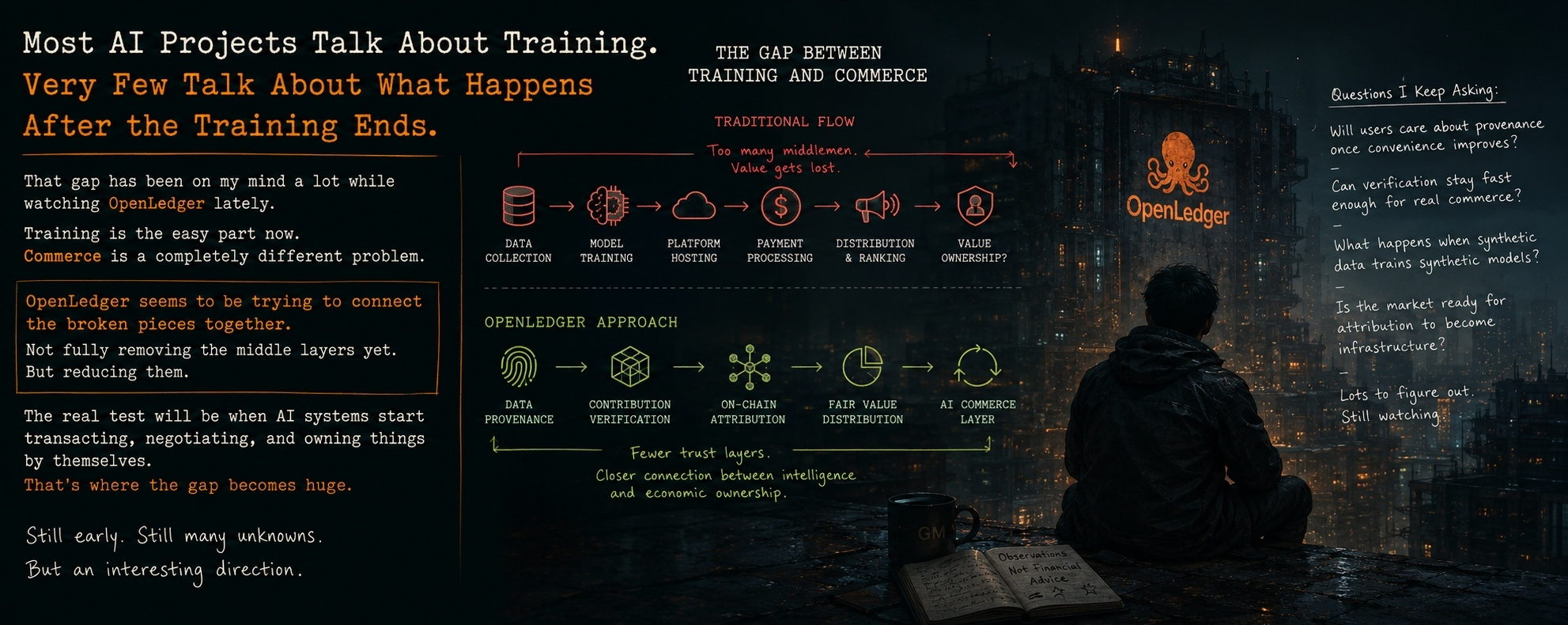
Todos dicen que están construyendo "infraestructura de IA”.
El comercio es un problema diferente.
OpenLedger entiende mejor que la mayoría de los proyectos.
Me doy cuenta de que OpenLedger no se centra en el modelo en sí.
Se enfoca en demostrar de dónde provienen las salidas.
Mira quién contribuyó valor.
Verifica cómo se mueven las recompensas a través del sistema después de que la IA comienza a operar.
Eso suena simple.
En realidad se vuelve rápido.
La mayoría de los sistemas de IA dependen de la confianza oculta en algún lugar.
* Alguien posee el canal de datos.
* Alguien controla la verificación.
* Alguien decide qué es útil.
OpenLedger intenta reducir esa dependencia.
No lo elimina por completo.
Lo reduce.
Esa diferencia importa.
Si el comercio de IA se convierte en máquina a máquina.
Pienso en cómo funcionan los sistemas de IA.
Un modelo de IA genera algo.
Otra plataforma lo alberga.
Otra empresa procesa pagos.
Otro sistema clasifica la visibilidad.
Otro grupo verifica la calidad.
Nadie sabe quién creó valor.
La capa comercial está desconectada de la capa de entrenamiento.
Eso crea incentivos.
* Los contribuyentes de datos se sienten mal pagados.
* Los constructores de modelos persiguen la escala, no la precisión.
OpenLedger intenta conectar esos pedazos rotos.
Prueba si la atribución puede convertirse en infraestructura.
Ese es un problema.
La atribución suena fácil hasta que los sistemas de IA remixean salidas.
Entonces las preguntas se vuelven incómodas.
* ¿Quién merece valor si un modelo aprendió de las contribuciones?
* ¿Quién verifica si los datos fueron útiles o ruido?
OpenLedger parece diseñado en torno a este problema.
Cuestiono algunas cosas.
¿A los usuarios les importa de dónde vienen los sistemas?
La historia muestra que la gente elige velocidad y productos baratos.
La mayoría de las personas no inspeccionan sistemas a menos que algo se rompa.
Así que me pregunto si OpenLedger está construyendo para un mercado.
Ese riesgo se siente real.
Los costos de verificación son otra cosa.
Agregar capas de atribución hace que los sistemas sean más pesados.
El comercio de IA quiere velocidad.
Los sistemas de confianza ralentizan las cosas.
Equilibrar esas presiones es complicado.
Muchos sistemas descentralizados fallan aquí.
No porque la visión esté equivocada.
La fricción operativa se vuelve insoportable.
OpenLedger aún se siente temprano.
Ves experimentación, no madurez.
Partes de la red descubren lo que los usuarios quieren.
Prefiero eso.
Me recuerda a proyectos de infraestructura.
La sensación de inconcluso te dice más que la marca.
Lo que observo es si sistemas como OpenLedger conectan la producción de inteligencia con la propiedad.
Si la IA se vuelve autónoma.
Luego la brecha entre entrenamiento y comercio se convierte en un problema de infraestructura.
La mayoría de las personas hablan como si la IA terminara en chatbots.
No creo que lo haga.
La industria puede no estar preparada para lo que sucede después.