
Hace unos años, "infraestructura de IA" significaba una cosa: más GPUs, clusters más grandes, tokens más rápidos. Todos perseguían la potencia bruta como si fuera el único cuello de botella que importaba. Yo también caí en esa historia — hasta que empecé a observar cómo se toman decisiones reales con la IA.
Porque aquí está la verdad incómoda: en el momento en que la IA deja de escribir poemas y comienza a influir en préstamos, señalando problemas de cumplimiento, verificando identidades o ayudando a mover capital, nadie pregunta qué tan rápido funcionó. Hacen una pregunta mucho más incómoda:
 ¿Quién demonios es responsable si esto sale mal?
¿Quién demonios es responsable si esto sale mal?
Esa pregunta está extrañamente ausente en la mayoría de las conversaciones sobre IA en cripto. Los proyectos se hypean con narrativas sobre computación, acceso a modelos o "inteligencia descentralizada." OpenLedger se agrupa en el mismo saco — "infraestructura de IA" — y técnicamente eso es correcto. Pero creo que se pierde el ángulo más interesante.
OpenLedger está construyendo algo más parecido a un mapa de responsabilidades que solo otra máquina de recompensas.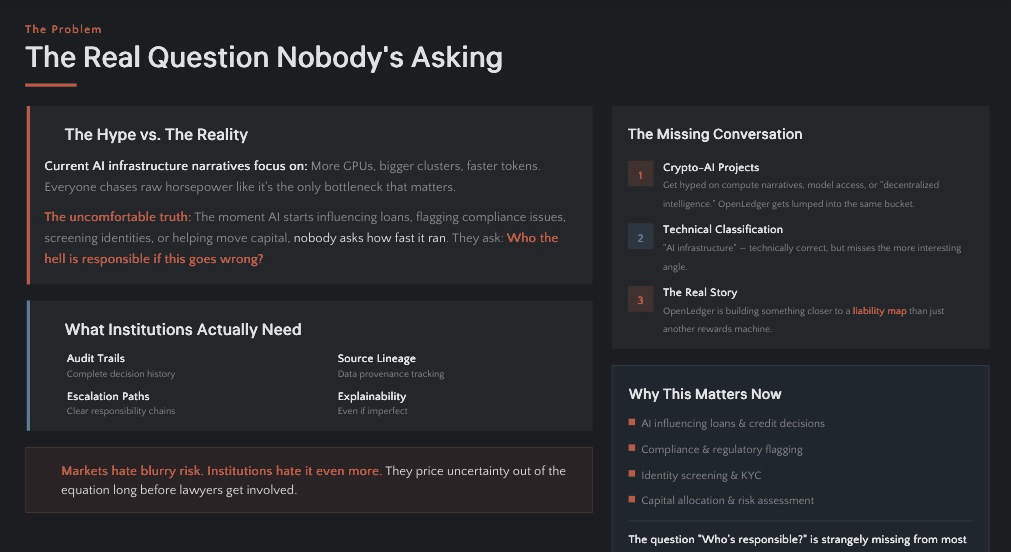
El Verdadero Cambio: De la Inteligencia a la Gestión de Consecuencias
El software tradicional era desordenado pero claro: una empresa enviaba el código y la responsabilidad (aunque imperfecta) tenía un hogar visible. La IA es diferente. Los datos vienen de un lugar, el ajuste fino de otro, el alojamiento de inferencias de otro más, capas de orquestación encima y sistemas de recuperación inyectando contexto a medio proceso. Para cuando una salida llega al usuario, la responsabilidad está difusa entre una docena de actores.
A los mercados no les gusta el riesgo borroso. A las instituciones les gusta aún menos.
Los bancos, aseguradoras y empresas reguladas no compran "vibras." Quieren rastros de auditoría, linaje de fuente, caminos de escalación y alguna forma de explicabilidad — incluso si es imperfecta. Ellos eliminan la incertidumbre de la ecuación mucho antes de que los abogados intervengan.
Ahí es donde el Proof of Attribution (PoA) de OpenLedger se vuelve silenciosamente poderoso. En lugar de tratar la atribución como una linda característica de marketing de "pagar a los contribuyentes", está construyendo linaje verificable dentro del sistema mismo — registros en cadena de qué datos influyeron en qué salidas. Convierte "quién contribuyó" en algo más cercano a "quién moldeó esta decisión," que es exactamente lo que las empresas necesitan para operacionalizar la IA sin perder la cabeza en una revisión de cumplimiento.
El Enfoque Económico que la Mayoría de la Gente Pierde
En este momento $OPEN tiene una capitalización de mercado alrededor de $45-60M (dependiendo del día), suministro circulante aproximadamente 220M de un máximo de 1B. Nada loco, pero el token no está valorado solo por hype — es el gas, el mecanismo de recompensa y la capa de coordinación para toda esta economía de atribución.
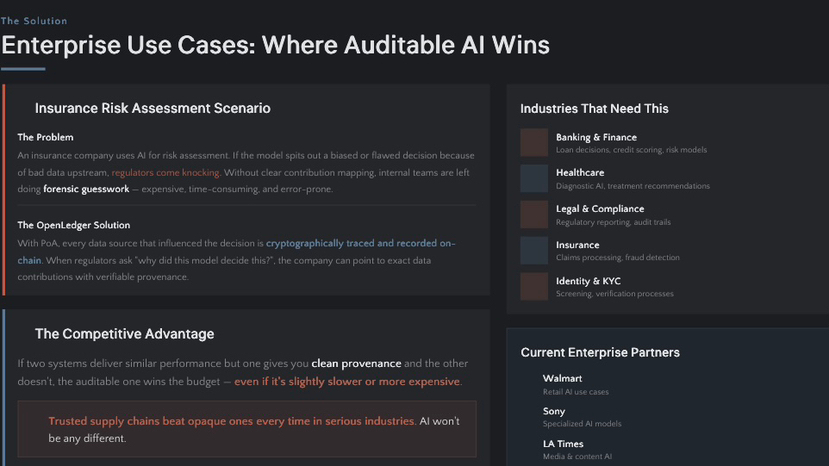
Piénsalo de manera práctica. Imagina una compañía de seguros usando IA para la evaluación de riesgos. Si el modelo produce una decisión sesgada o defectuosa debido a malos datos upstream, los reguladores llegan. Sin un mapeo claro de contribuciones, los equipos internos se quedan haciendo conjeturas forenses. Eso es caro.
Si dos sistemas ofrecen un rendimiento similar pero uno te da un linaje limpio y el otro no, el que se puede auditar gana el presupuesto — incluso si es un poco más lento o más caro. Las cadenas de suministro confiables superan a las opacas cada vez en industrias serias. La IA no será diferente.
Esto no es un lenguaje glamoroso de "misión lunar." Es un lenguaje aburrido de infraestructura — el tipo que realmente dura.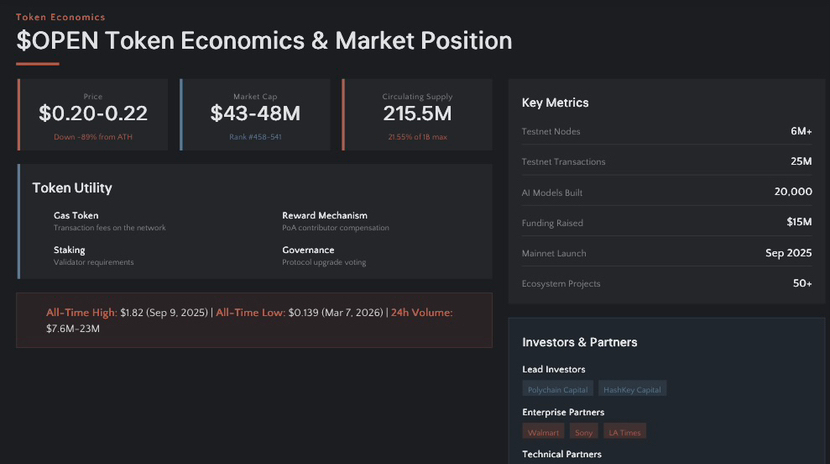
La Parte Escéptica (Porque Cripto)
Nada de esto es fácil. La atribución en IA es genuinamente difícil — los efectos de entrenamiento son difusos, la mezcla de señales es desordenada y el rastreo perfecto probablemente sea imposible a gran escala. La "responsabilidad" mal implementada puede ser peor que la opacidad honesta.
Los incentivos cripto hacen que sea aún más complicado. Adjunta dinero real a la atribución y de inmediato obtienes conjuntos de datos spam, contribuciones fabricadas, ataques sybil y manipulaciones de reputación. El sistema tiene que sobrevivir al comportamiento adversarial, no solo a demostraciones amistosas.
Y hay una pregunta cultural más profunda: ¿quieren las empresas realmente una responsabilidad descentralizada? Algunas podrían preferir un proveedor centralizado con un contrato y una garganta que ahorcar. La responsabilidad distribuida puede sentirse como un caos burocrático si la UX no es excelente.
El verdadero desafío de OpenLedger no es técnico — es hacer que la atribución distribuida se sienta útil operativamente para las personas que dirigen negocios reales, no solo para nativos de cripto.
 La Gran Imagen
La Gran Imagen
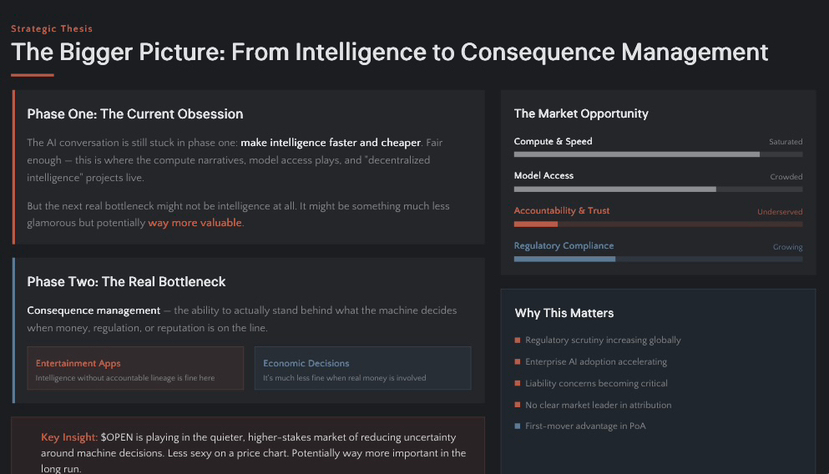
La conversación sobre IA aún está atrapada en la fase uno: hacer la inteligencia más rápida y barata. Justo. Pero el siguiente verdadero cuello de botella podría no ser la inteligencia en absoluto. Podría ser la gestión de consecuencias — la capacidad de respaldar realmente lo que la máquina decide cuando el dinero, la regulación o la reputación están en juego.
La inteligencia sin linaje responsable está bien para aplicaciones de entretenimiento.
Es mucho menos aceptable cuando se involucran decisiones económicas reales.
Por eso veo $OPEN diferente de la mayoría del mercado. No está compitiendo puramente en la categoría de computación o acceso a modelos. Está jugando en el mercado más silencioso y de mayores riesgos de reducir la incertidumbre en torno a las decisiones de las máquinas.
Menos atractivo en un gráfico de precios.
Potencialmente mucho más importante a largo plazo.
¿Qué piensas — el mercado sigue demasiado enfocado en la inteligencia cruda, o finalmente estamos comenzando a valorar la confianza y la gobernabilidad como deberíamos?
Me encantaría conocer tu opinión.
