He estado revisando la arquitectura de openledger últimamente, principalmente indagando en cómo manejan la atribución de datos y cómo planean conectar modelos de IA fuera de la cadena con la coordinación económica en la cadena. Honestamente, los diagramas técnicos me dejan con tantas preguntas como respuestas en este momento.
La mayoría de la gente piensa que openledger es solo otro token de IA + cripto donde subes un conjunto de datos, el token sube, y de alguna manera reemplazamos a los corredores de datos centralizados. Pero esa narrativa simplificada oculta el verdadero problema de ingeniería, que es ridículamente difícil: construir un pipeline verificable desde datos en bruto hasta salidas de modelos sin requerir que todos confíen en un servidor central.
hay algunos componentes que estoy tratando de entender.
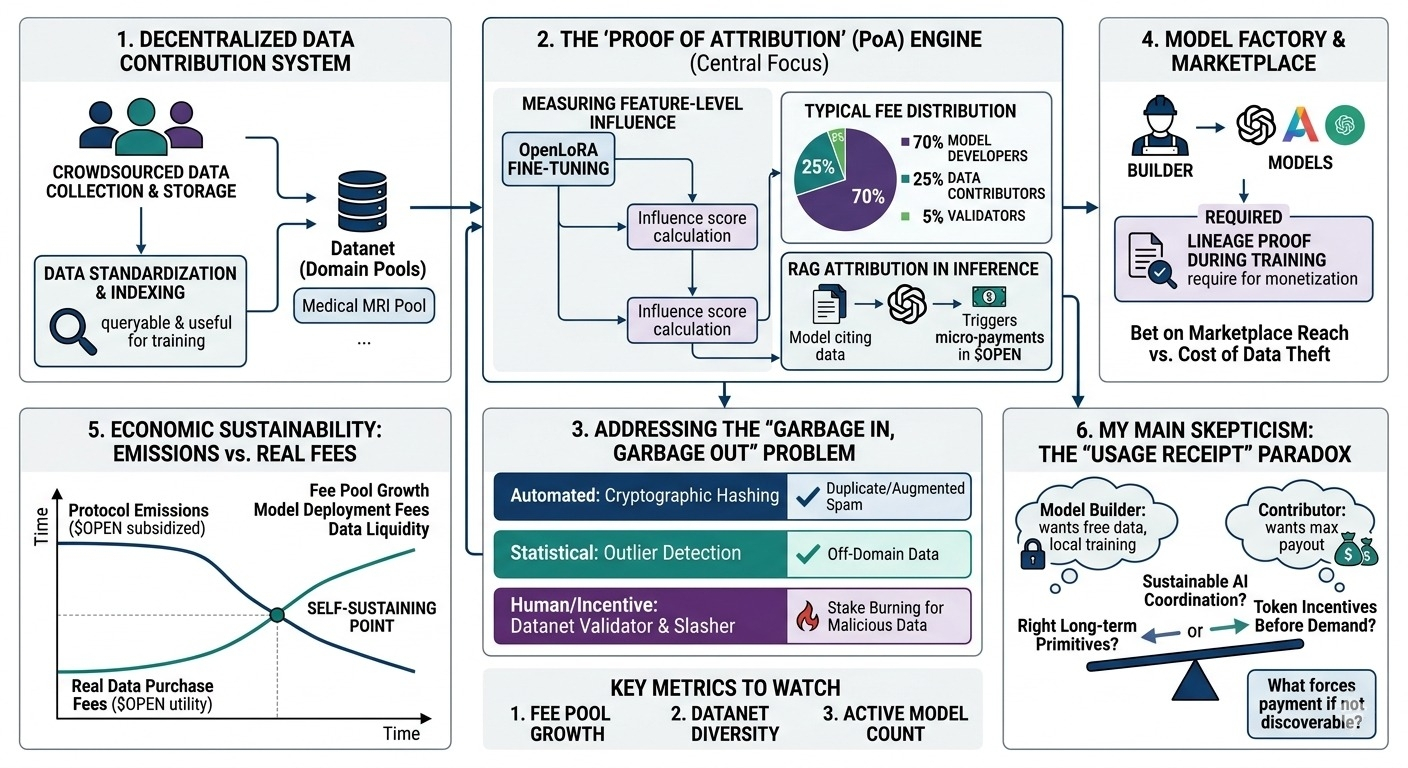
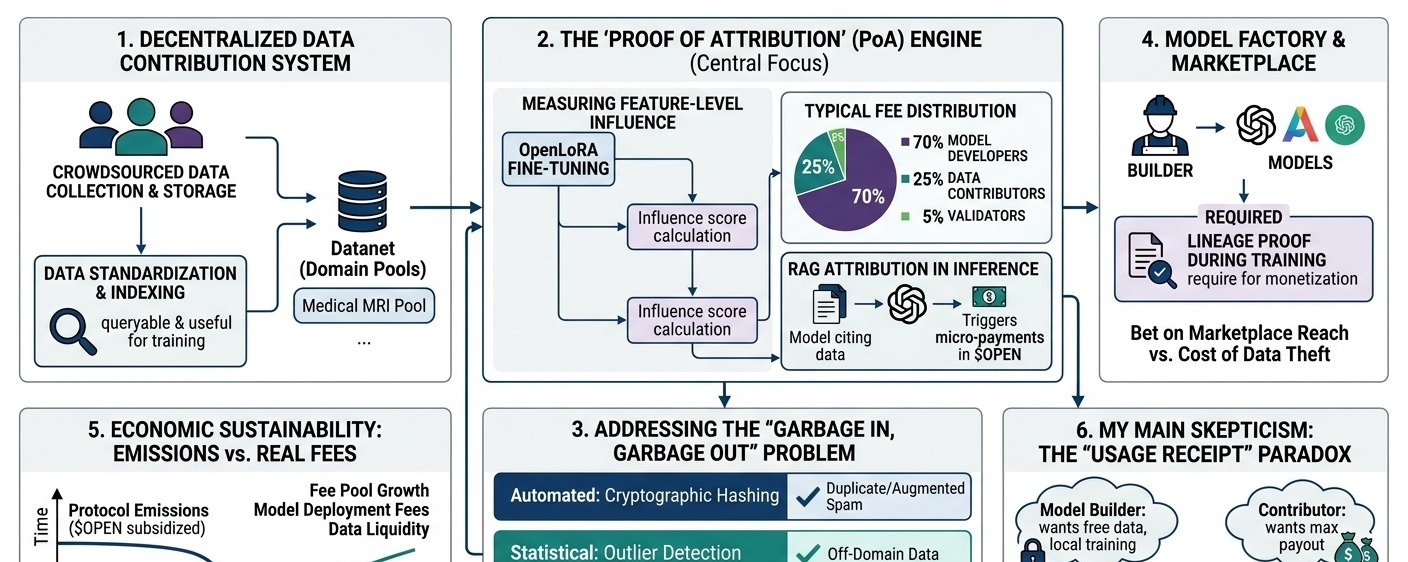
primero, el sistema de contribución de datos descentralizado. están construyendo infraestructura para la recolección y almacenamiento de datos a través de crowdsourcing. lo que llamó mi atención es que no solo están vertiendo archivos en bruto en almacenamiento descentralizado; están tratando de estandarizarlo para que sea consultable y útil para el entrenamiento.
entonces está el mecanismo de atribución + recompensa. y esta es la parte en la que sigo pensando... ¿cómo se le atribuye realmente valor a una pieza específica de datos una vez que una red neuronal ha digerido millones de ellos?
también están las dinámicas del mercado de modelos/datos, donde los creadores necesitan datos y el protocolo se encuentra en el medio. y finalmente, los incentivos del token y la capa de verificación. la cadena maneja la contabilidad, pero verificar que un modelo realmente utilizó los datos a gran escala requiere un gran esfuerzo criptográfico o hardware confiable que no estoy seguro de que esté completamente desarrollado todavía.
entonces, ¿quién realmente crea valor en este sistema? los contribuyentes proporcionan la materia prima, pero el valor solo se realiza si un constructor de IA paga para entrenar sobre ello. el protocolo asume que los creadores querrán comprar datos a trozos de una red descentralizada en lugar de simplemente licenciar enormes corpus pre-limpiados de plataformas centralizadas.
mi principal escepticismo es si esta atribución sigue siendo confiable. imagina un ejemplo realista: un equipo está entrenando un modelo de diagnóstico médico especializado. necesitan miles de escaneos de MRI altamente específicos y anotados. openledger podría teóricamente coordinar este crowdsourcing. pero si los incentivos de token están ligados a la carga, ¿cómo evitas una inundación de datos de spam de baja calidad o ligeramente aumentados? necesitas curadores o cortadores automáticos, lo que introduce fricción y cuellos de botella centralizados.
digamos que un constructor de modelos saca ese conjunto de datos de MRI de la red, entrena su modelo localmente y lo envía. ¿cómo hace openledger para hacer cumplir realmente el recibo de uso? si dependen de la auto-información, hay una enorme desalineación de incentivos. los creadores quieren datos gratis, los contribuyentes quieren el máximo pago.
esto lleva a la clásica tensión del token: emisiones vs utilidad real. al principio, las emisiones del protocolo subsidiarán las recompensas. los contribuyentes recibirán pagos en tokens incluso si nadie está comprando los datos. ¿pueden estos incentivos mantenerse sostenibles a lo largo del tiempo una vez que las emisiones se agoten? si la demanda real no se materializa, todo se colapsa en un disco duro descentralizado de conjuntos de datos no utilizados.
no tengo una conclusión perfecta aquí. quiero creer que es posible una capa de coordinación de IA sostenible, pero es difícil saber si openledger está construyendo los elementos primarios adecuados a largo plazo o simplemente adjuntando incentivos de token a la infraestructura de IA antes de que exista la demanda real.
observando:
- la proporción de emisiones del protocolo a las tarifas reales de compra de datos (¿cuándo se convierte la red realmente en autosostenible?)
- tasas de rechazo y disputa de conjuntos de datos (esto señalará cuántos spam están llegando a la capa de contribución)
- presencia de compradores de datos recurrentes (no solo pilotos subsidiados por tokens de una sola vez)
si resuelven el problema de atribución sin hacer que la red sea locamente lenta o cara, es realmente interesante. pero hasta entonces, ¿qué realmente obliga a un constructor de modelos a jugar según las reglas y pagar una vez que tiene los datos?