最近看到 @OpenLedger 的时候,我第一反应也是嘴一撇:得,又是硬蹭AI概念发币的“土狗链”吧?毕竟这年头打着AI旗号讲宏大叙事的项目太多了,多到让人PTSD
但作为一个习惯性怀疑、不见兔子不撒网的老韭菜,我习惯性地去翻了白皮书,甚至直接上手去它的金融领域Datanet提交了大概200条市场分析的标注文本。一套流程跑下来,我发现自己可能看走眼了-这项目,底层的运行逻辑居然是通的,而且不是黑盒子
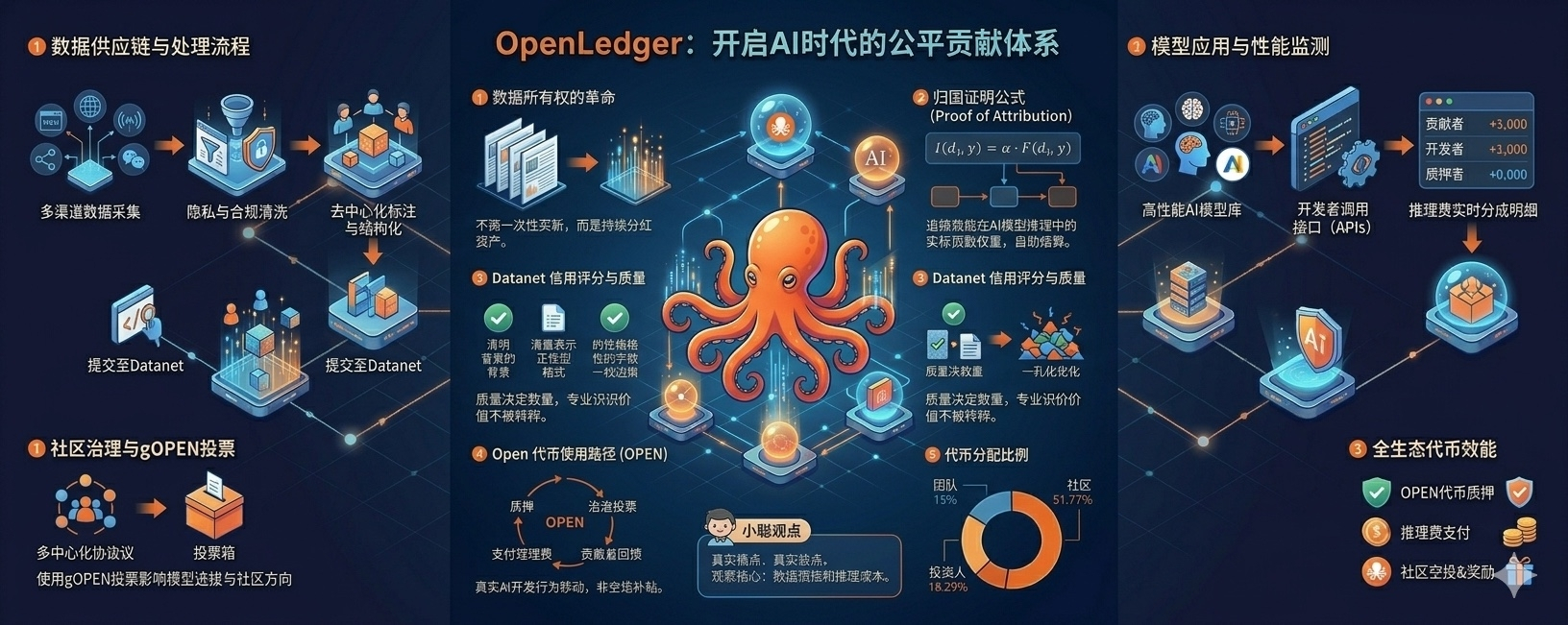
在提交界面上,链上归因和权重分配实时可见。说白了,你投了多少有价值的料,系统清清楚楚给你标出来。坐在电脑前看着那个权重区间,我突然意识到:这玩意儿要是真跑通了,革的是整个AI行业的命
1.数据这块肥肉,以前到底是谁在“白嫖”你?
在Web2的世界里,数据的底层逻辑就是“不平等条约”
以前我也给某些金融数据平台打过短工,熬夜整理了一大批行业研究报告的结构化数据。对方拍给我一笔一次性结算的辛苦钱,买卖算清了对吧?但后来的剧本是:那批数据被拿去训练了一个分析型AI,这个AI被高价卖给了好几家金融机构,赚得盆满钵满。
而这个AI后面产生的后续价值,跟我一毛钱关系都没有
这不只是我的故事,这是现在所有 AI 数据链条的默认潜规则。各大模型公司拿着全球用户的公开数据或廉价劳动力数据去训练,最后变现上万亿,但跟你这个“数据母亲”毫无瓜葛
问题出在哪里?不是模型公司道德败坏,而是传统的基础设施根本没有“追踪和溯源”能力。没有一个系统能精准地告诉你:“喂,你贡献的那 200 条数据,在AI的第8437次回答里,贡献了6.2% 的输出权重。”既然算不出来,自然就没法分钱
而OpenLedger用所谓的Proof of Attribution(归因证明) 正在干的,就是强行把这个追踪器给搭出来#OpenLedger
2.白皮书里那个公式,翻译成“人话”是什么?
很多人一看到白皮书第8页的公式 I(d_i, y) = \alpha \cdot F(d_i, y) 就直接划走了。别慌,小聪帮你翻译成最直白的逻辑:
每次有人花钱调用OpenLedger上的 AI 模型做一次推理(回答问题),系统就会在后台自动算一笔账:“这次回答能成,全靠哪些数据支撑?每条数据的实际贡献比例是多少?”
你贡献的数据越关键、质量越高,贡献权重就越大,你分到的推理费就越多。要是贡献的是垃圾水数据,不好意思,权重为零,一分没有
白皮书第10页有个特别实在的算例:
假设某次AI推理收了1.14 个 OPN代币,扣掉给平台的管理费,净收益剩下 0.64 OPN。这笔钱会雷打不动地按比例拆给三方:模型开发者、质押者、数据贡献者。如果你的数据在这场回答里贡献权重是 25%,那么这次推理你就能直接躺赚 0.032 OPN
听起来是不是觉得塞牙缝都不够?
但你想想规模效应。 这是每次推理都在自动链上结算。只要这个模型一直有用、一直有人调用,你就能源源不断地拿到分成。这根本不是传统的“打工搬砖费”,这是直接把你的知识产权变成了可以持续分红的链上资产
3.为什么“质量评分”是水军的火葬场?
OpenLedger里面有一个专门针对Datanets(数据网络)的信用评分机制(就是公式里的 C(D))。一句话总结:质量越高,权重越大;堆砌数量,直接淘汰
这个设计太戳老韭菜的痛点了。很多Web3项目最后被刷子和工作室用垃圾数据冲垮,就是因为只看数量不看质量。而在OpenLedger里,你想靠机器批量生成的垃圾话来骗补贴?系统直接反手给你判定为低质量,权重降为零
这对于真正有专业领域知识的人(比如行业分析师、硬核交易员、代码大佬)来说是绝对的红利。你的专业价值有明显的区分度,不会被低成本的垃圾信息稀释。像我在金融类Datanet提交的数据,因为来源合规、格式规范、标注逻辑一致,质量评分明显高出一截,拿到的权重自然也比随机提交的用户更具优势
4. $OPEN 代币是真有活干,还是纯空气?
判断一个币是不是空气,就看它的流动闭环是不是靠“接盘侠”撑着的。OPEN的使用路径里,有几个闭环我觉得逻辑上是踩中的:
开发提案:你想在链上提交一个新的模型提案?得质押OPEN换成gOPEN才能投票。
使用模型:别人想运行这个模型做AI推理?必须支付OPEN
数据回报:你给模型搬砖贡献高质量数据?奖励你OPEN
这套逻辑不是靠项目方疯狂发空投、画大饼维持的,而是靠真实的 AI 开发和消费行为在驱动代币循环。只要用这个模型的人变多,代币的需求就会上去,贡献者手里的分成也就更有保障
再看一眼代币分配:社区直接拿了51.71%,投资人18.29%,团队15%。超过一半的筹码放在社区和生态手里,这在如今动不动机构控盘90%的牛市大环境里,确实算少见的诚意了
💡小聪观点
作为一个在行业里摸爬滚打多年的老韭菜,小聪的习惯向来是“看它怎么做,不听它怎么吹”。
客观来说,OpenLedger现在还在非常早期。接下来它要面临的考验是一针见血的:第一,面对海量提交,数据质量管控的执行力度能不能持续高压?第二,当大规模推理发生时,链上计算权重的成本能不能真正压下来? 这些硬骨头,都需要我们持续盯盘、看链上数据反馈
但小聪之所以愿意花时间去测试它,是因为它切中的痛点是百分之百真实的。AI时代最缺的是什么?不是算力,是高质量的“干净数据”。过去提供数据的人永远被资本和模型方白嫖,这条链至少从底层架构上,试图像个账本一样把账算明白。它不是给通用链贴个“AI”标签骗散户,它是真的在搭一套生产关系工具
如果这个飞轮未来能转起来:
高质量数据进来 \rightarrow模型变得更聪明、更有行业深度 \rightarrow机构和用户付费使用量上升 \rightarrow贡献者拿到真金白银的分成 \rightarrow吸引更多高水平创作者
这是一个靠自身造血、自我强化的生态,而不是靠项目方左手倒右手发补贴硬撑的泡沫
小聪目前也持有部分OPEN并在持续参与数据贡献,是骡子是马,我们链上见。后续有更硬核的交互数据和收益反馈,我会继续在主页和大家分享
(以上内容属个人观点仅供参考)