La Prueba de Atribución resuelve un problema que la IA cripto necesitaba urgentemente solucionar.
Esa parte es obvia.
Durante demasiado tiempo, las salidas de los modelos han funcionado como trucos de magia. Respuesta útil aparece. Se activa la acción. Se establece el precio de la decisión. Se genera el ingreso. Nadie sabe realmente qué contribuyó al resultado, quién moldeó el comportamiento del modelo, o si el sistema se basó silenciosamente en una infraestructura que nadie está reconociendo.
OpenLedger tiene razón al atacar eso.
La trazabilidad importa.
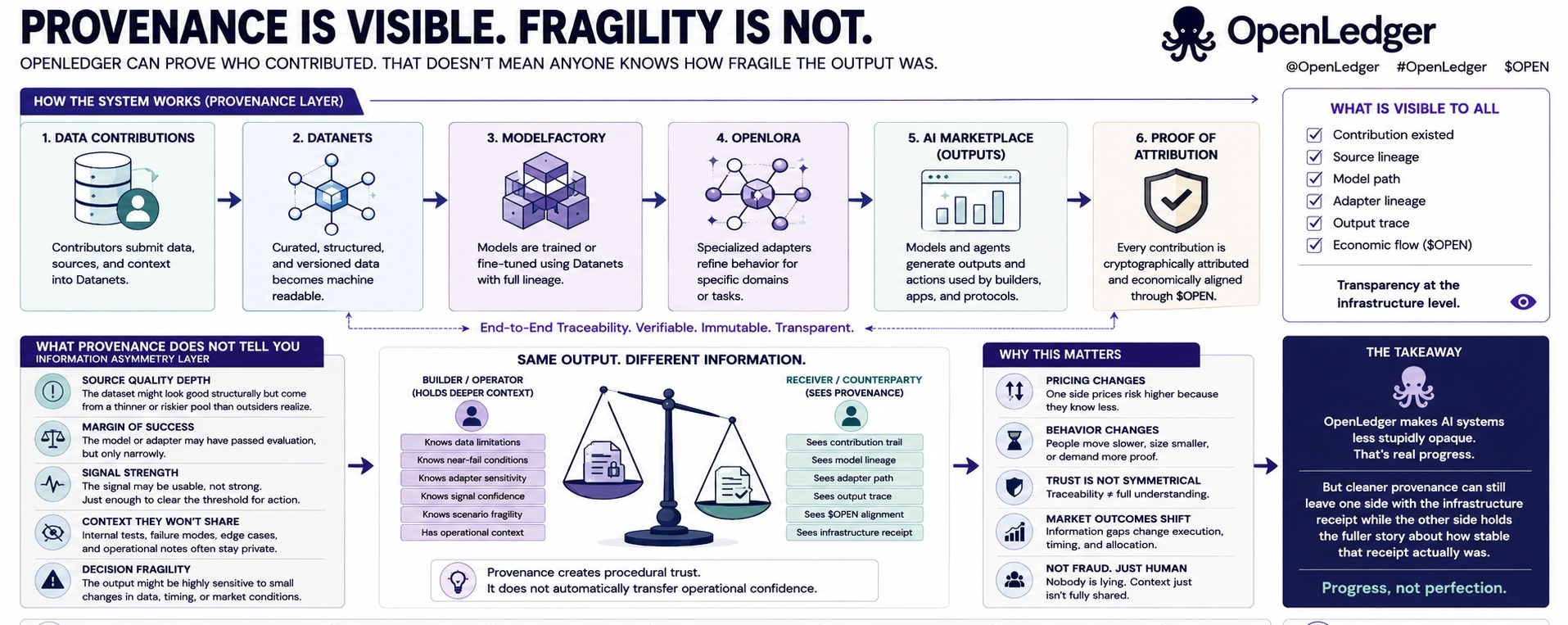
Sin embargo, la tensión más interesante comienza después de que la procedencia se vuelve visible.
Porque probar la línea no es lo mismo que distribuir la comprensión.
Esa distinción sigue molestándome.
Imagina un flujo de trabajo potenciado por OpenLedger donde algún sistema autónomo produce un resultado que realmente importa. Quizás una acción del tesoro. Quizás una decisión de un agente. Quizás algún camino de ejecución modelado a través del contexto de Datanet, la lógica de ModelFactory y una especialización estrecha de OpenLoRA.
Ahora el resultado ya no es una caja negra.
Bueno.
Hay una línea.
La contribución puede ser rastreada.
La Prueba de Atribución puede mostrar lo que dio forma al resultado.
La arquitectura cumplió su función.
Pero ahora haz la pregunta incómoda.
¿Cuánto sabe la parte que muestra el rastro que la parte receptora no sabe?
Porque la procedencia te dice de dónde vino algo.
Eso no te dice automáticamente cuán frágil fue el camino.
Quizás el Datanet parecía estructuralmente bien pero provenía de una fuente más delgada de lo que los externos se dan cuenta.
Quizás el adaptador de OpenLoRA pasó la evaluación técnicamente, pero solo de forma estrecha.
Quizás la ruta del modelo era aceptable, no fuerte.
Quizás la señal apenas superó el umbral que hacía que la acción autónoma se sintiera justificada.
Eso no es fraude.
Ni siquiera cerca.
Eso es solo asimetría informativa con una infraestructura más limpia.
Y a los mercados les importa mucho esa diferencia.
Un rastro de procedencia podría tranquilizar a una parte.
La otra parte aún podría estar sentada sobre un contexto operativo más rico.
Eso cambia el comportamiento.
El tamaño de la posición cambia.
La confianza cambia.
La confianza de la contraparte cambia.
El tiempo de ejecución cambia.
Una mesa que escucha 'trazable' no necesariamente escucha 'robusto'.
Ahí es donde OpenLedger se vuelve mucho más interesante que la narrativa de transparencia perezosa.
Porque esto no se trata solo de probar que ocurrió una contribución.
Se trata de cuánto profundidad informativa realmente transfiere la procedencia.
Y esas no son la misma cosa.
Una parte puede saber que el adaptador casi falló.
Una parte puede saber que la señal era técnicamente utilizable pero estratégicamente débil.
Una parte puede saber que la fuente parecía más superficial de lo que sugiere la historia de atribución limpia.
La otra parte obtiene la línea.
Eso es mejor que la IA de caja negra.
Absolutamente.
Aún no es simétrico.
Esa asimetría importa porque la procedencia puede crear confianza procedural sin necesariamente transferir confianza operacional.
Esas son cosas completamente diferentes.
Sigo pensando en cómo se comportan los mercados cuando una parte tiene un contexto materialmente más rico.
Nadie necesita engaños para que el comportamiento de precios cambie.
Nadie necesita una intención maliciosa.
Un usuario simplemente pide más margen.
Un socio se mueve más lento.
Una contraparte amplía las suposiciones.
Un tesoro descuenta el resultado más duro.
Porque la trazabilidad es útil.
Pero útil no es lo mismo que completo.
Esa es la categoría incómoda.
OpenLedger puede absolutamente hacer que los sistemas de IA sean menos estúpidamente opacos.
Eso es un verdadero progreso.
Pero una procedencia más limpia también puede crear una nueva versión de desequilibrio informativo donde una parte obtiene el recibo de infraestructura y la otra parte aún tiene la historia completa sobre cuán estable fue realmente ese recibo.
Ese es un problema mucho más difícil.
Porque el sistema funcionó.
El Datanet permaneció legible.
Existía una línea de modelo.
El comportamiento de OpenLoRA se mantuvo atribuible.
La Prueba de Atribución hizo lo que prometió.
$OPEN enrutamiento de valor alineado.
Todo se comportó correctamente.
Y una parte aún se fue entendiendo la fragilidad del resultado mucho mejor que la otra.
Por eso no creo que la procedencia automáticamente iguale a confianza.
A veces solo reemplaza la opacidad de la caja negra con una versión más limpia de un contexto desigual.
Eso sigue siendo progreso.
Simplemente no es el tipo simple que la gente quiere que sea.