
OpenLoRA: La Brecha Entre la Educación en IA y la Implementación Práctica
La industria de la IA frecuentemente se concentra en desarrollar modelos más grandes e inteligentes, pero la implementación es otro asunto que afecta si la IA puede escalar en escenarios del mundo real. Si servir a un modelo potente requiere infraestructura costosa, alta latencia y recursos de GPU dedicados para cada tarea especializada, es de poco uso.
Aquí es donde OpenLoRA de OpenLedger marca la diferencia.
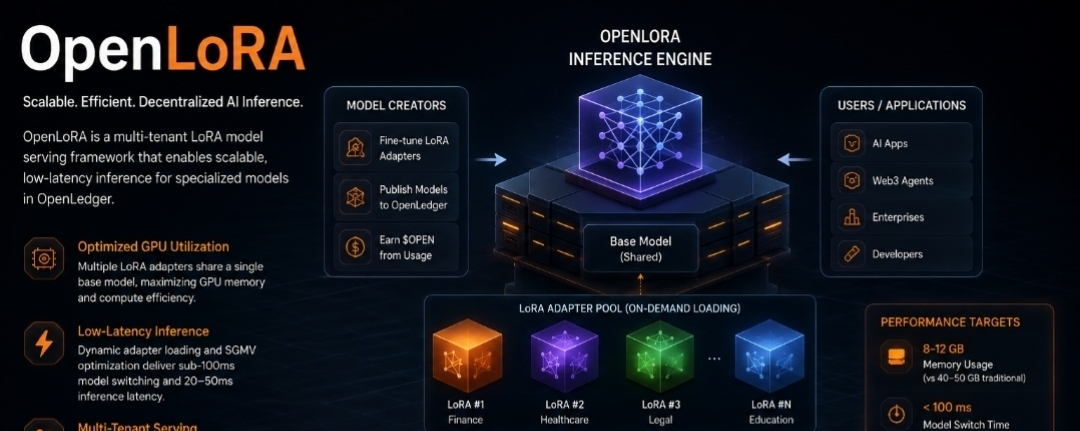
Se creó un marco de servicio de modelo LoRA multi-inquilino llamado OpenLoRA para proporcionar inferencia escalable y de baja latencia para modelos de IA especializados. OpenLoRA permite que miles de modelos especializados compartan un modelo base común mientras cargan dinámicamente solo los adaptadores necesarios, eliminando la necesidad de implementar instancias de GPU separadas para cada modelo refinado. Esto reduce los costos operativos y aumenta significativamente la eficiencia.
El uso de IA tradicional frecuentemente resulta en ineficiencias significativas:
• Diferentes modelos utilizan diferentes cantidades de memoria GPU.
• El costo de la infraestructura aumenta con la escala.
• Hay retrasos al cambiar entre modelos especializados.
• Los recursos de GPU todavía están subutilizados.
OpenLoRA utiliza varias innovaciones significativas para abordar estos problemas:
Infraestructura GPU para Múltiples Inquilinos
En lugar de cargar repetidamente modelos completos, múltiples modelos LoRA comparten un único modelo base preentrenado. Esto aumenta la eficiencia computacional mientras reduce la sobrecarga de memoria de la GPU.
Carga Dinámica de Adaptadores
Solo cuando es necesario se cargan adaptadores, y una vez que se termina la inferencia, se descargan. Se reducen los retrasos de inicio en frío y se hace posible un cambio rápido de modelos al mantener el modelo base en memoria.
Optimización de SGMV
Para cargas de trabajo de inferencia, la Multiplicación Segmentada de Matrices-Vectores mantiene patrones óptimos de acceso a la memoria mientras facilita una ejecución efectiva por lotes.
Programación de GPU con Inteligencia
Para maximizar el rendimiento y mantener cargas de trabajo equilibradas entre recursos, las solicitudes se asignan dinámicamente según la memoria disponible y los requisitos por lote.
Los objetivos de rendimiento son notables:
• Uso de memoria: 8–12 GB en lugar de 40–50 GB en métodos de implementación convencionales
• Cambiar entre modelos toma menos de 100 ms.
• Rendimiento: más de 2000 tokens por segundo
• Latencia: aproximadamente 20–50 ms
El hecho de que OpenLoRA sea más que solo un marco de inferencia lo hace particularmente intrigante para la IA descentralizada. Crea un sistema donde los contribuyentes pueden ser compensados según el uso del modelo y la influencia al integrarse con el ecosistema más amplio de OpenLedger, que incluye Datanets y Prueba de Atribución. La pregunta "¿Quién tiene el modelo más grande?" puede dar paso a "¿Quién puede desplegar inteligencia eficientemente a gran escala?" a medida que la IA evoluciona. Según OpenLoRA, una ejecución más inteligente puede ser tan importante para el futuro de la IA como modelos más inteligentes.