
Hace unos años, internet se sentía como una biblioteca interminable para la IA.
¿Necesitas conocimiento? Raspa más sitios web. Reúne más texto. Entrena modelos más grandes.
La fórmula funcionó, hasta que empezaron a aparecer las grietas.
A medida que la IA se volvió común, la web cambió lentamente. El contenido de baja calidad se multiplicó. La información generada por IA comenzó a alimentar otros sistemas de IA. El ruido aumentó. La confianza se volvió más difícil de medir.
De repente, más datos ya no significaban mejor inteligencia.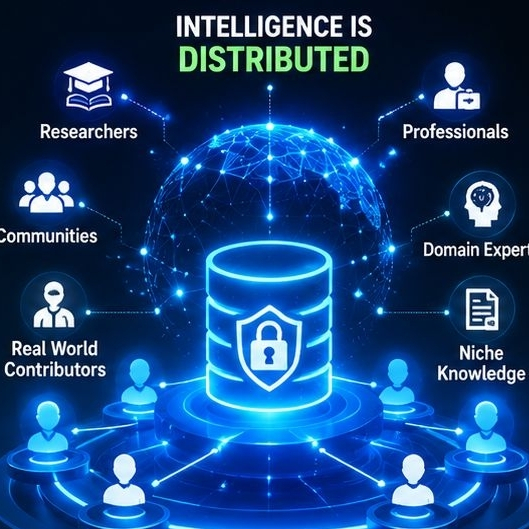
Ahí es donde comienza la conversación sobre los datos de IA descentralizada.
No porque la descentralización suene emocionante, sino porque la inteligencia depende cada vez más de conocimientos humanos especializados y confiables.
El modelo antiguo asume que unas pocas plataformas centralizadas pueden reunir y controlar la mayoría de los datos útiles. Pero la experiencia no vive en un solo lugar. Existe dentro de comunidades, industrias, investigadores, expertos en nichos y contribuyentes del mundo real repartidos por todas partes.
La pregunta se vuelve difícil de ignorar:
¿Cómo organizas la valiosa inteligencia humana sin depender completamente de sistemas cerrados?
Por eso los datos de IA descentralizada son importantes.
El objetivo no es simplemente recopilar más información. Es crear sistemas donde los datos de mejor calidad sean más fáciles de obtener, organizar y mantener a través de la participación distribuida.
Por supuesto, la descentralización trae sus propios problemas. El control de calidad se vuelve más complicado. La coordinación se desordena.
Aún así, si la IA futura depende de la experiencia confiable en lugar del ruido de internet, los sistemas que gestionan los datos pueden volverse silenciosamente tan importantes como los modelos mismos.
