

Hace unas noches estuve a punto de cerrar mi posición abierta después de un pequeño profit. No fue nada dramático, tal vez alrededor de un 11% arriba desde mi entrada, pero seguí releyendo el mismo pensamiento en mis notas y eso me detuvo de vender.
Creo que la mayoría de la gente está interpretando la infraestructura de atribución de IA de manera demasiado limpia.
El marco común es simple: los contribuyentes proporcionan datos, los modelos aprenden de eso, la atribución rastrea la influencia y los tokens coordinan las recompensas. Suena organizado en papel. Pero cuanto más pienso en OpenLedger, menos creo que la atribución realmente se trate de reconocimiento.
Creo que eventualmente podría convertirse en infraestructura de disputas.
Eso suena exagerado hasta que el dinero entra en el sistema.
En el momento en que las salidas de IA comienzan a generar flujos financieros recurrentes, la atribución deja de ser un simple registro pasivo. Se convierte en una superficie de reclamo financiero. Y eso cambia completamente la mecánica.
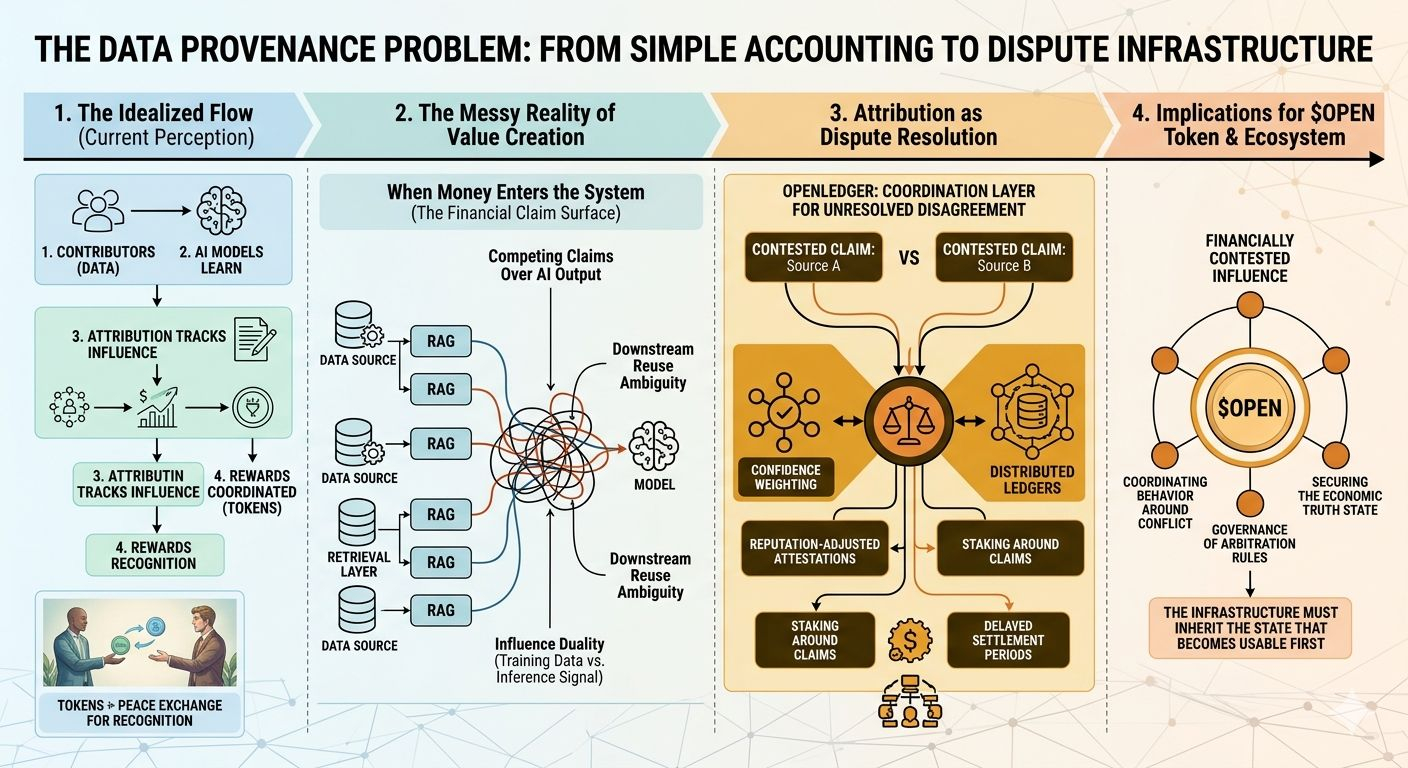
Si dos partes reclaman influencia sobre el mismo comportamiento del modelo, ¿quién decide realmente qué importó? ¿Fue el conjunto de datos que moldeó el entrenamiento hace seis meses? ¿La capa de recuperación que influyó en la inferencia hoy? ¿El peso de la señal? ¿El reutilizado aguas abajo?
La gente habla sobre la procedencia como si fuera una verdad objetiva. No estoy convencido de que funcione así en la práctica.
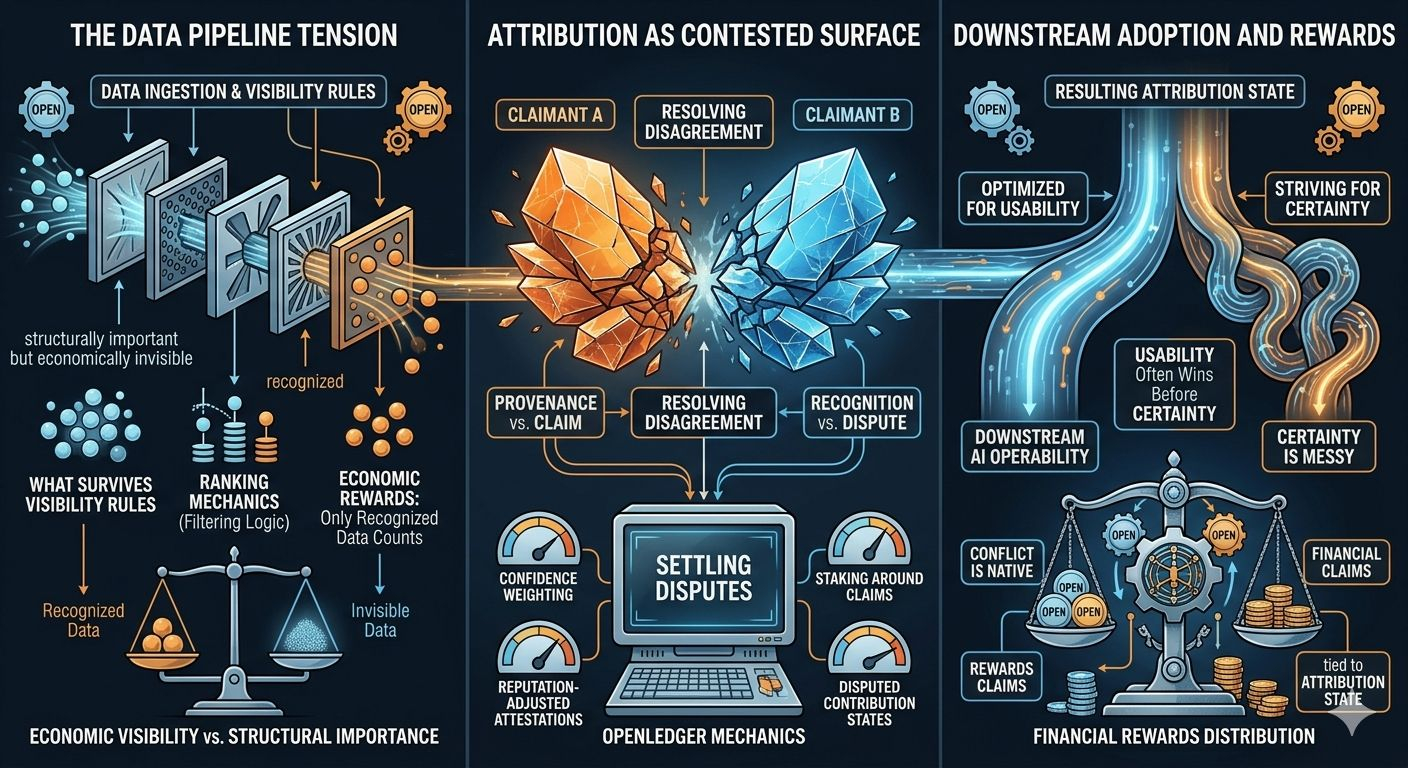
Un sistema solo reconoce lo que sobrevive a sus reglas de visibilidad. Todo lo que está fuera de esos límites puede ser estructuralmente importante pero económicamente invisible. Esa distinción importa mucho una vez que los pagos, licencias o reputación comienzan a depender de los estados de atribución.
Lo que realmente cambió mi forma de pensar fue observar cómo se comportan los sistemas de clasificación en línea. Desde afuera, las puntuaciones de los creadores parecen objetivas. Pero nadie ve la lógica de filtrado debajo. Ciertos comportamientos cuentan. Otros desaparecen durante el preprocesamiento. La salida final parece estable incluso si el camino no lo fue.
La atribución de IA me parece peligrosamente similar.
Y aquí es donde $OPEN comenzó a verse diferente.
Quizás OpenLedger no solo esté tratando de verificar contribuciones. Tal vez esté construyendo la capa de coordinación para desacuerdos no resueltos sobre la contribución en sí. No disputas legales exactamente. Algo más nativo de la máquina.
Peso de confianza. Atestaciones ajustadas por reputación. Períodos de liquidación retrasados. Estados de contribución disputados. Staking alrededor de reclamaciones.
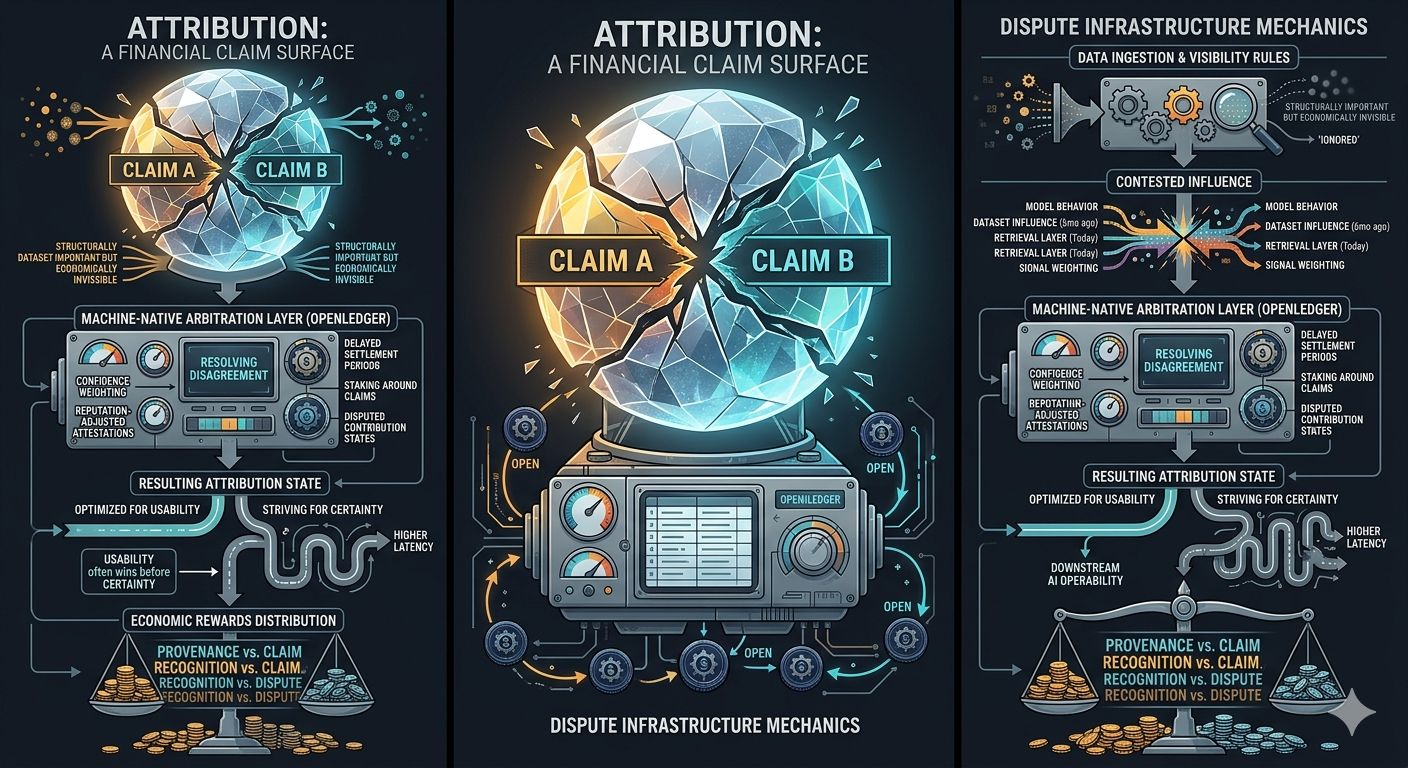
Estoy especulando, obviamente, pero estructuralmente comienza a sentirse necesario.
Porque si la atribución afecta directamente a las recompensas económicas, el conflicto se convierte en un comportamiento nativo en lugar de un caso excepcional.
Esa es la parte que creo que el mercado todavía trata demasiado ligeramente.
Lo aterrador es que los sistemas aguas abajo suelen heredar cualquier estado de atribución que se vuelva utilizable primero. No necesariamente la versión más completa. Solo la versión lo suficientemente estable para operar.
La usabilidad a menudo gana antes que la certeza.
Y si OpenLedger termina sentándose debajo de ese proceso, entonces abierto puede no representar simplemente el uso de infraestructura de IA. Podría representar la coordinación en torno a la influencia financieramente disputada.
Honestamente, todavía no sé si eso es un diseño de infraestructura elegante o el comienzo de una categoría realmente desordenada nativa de la máquina para la que nadie está preparado aún.
Esa incertidumbre es exactamente la razón por la que aún no he salido de mi posición.