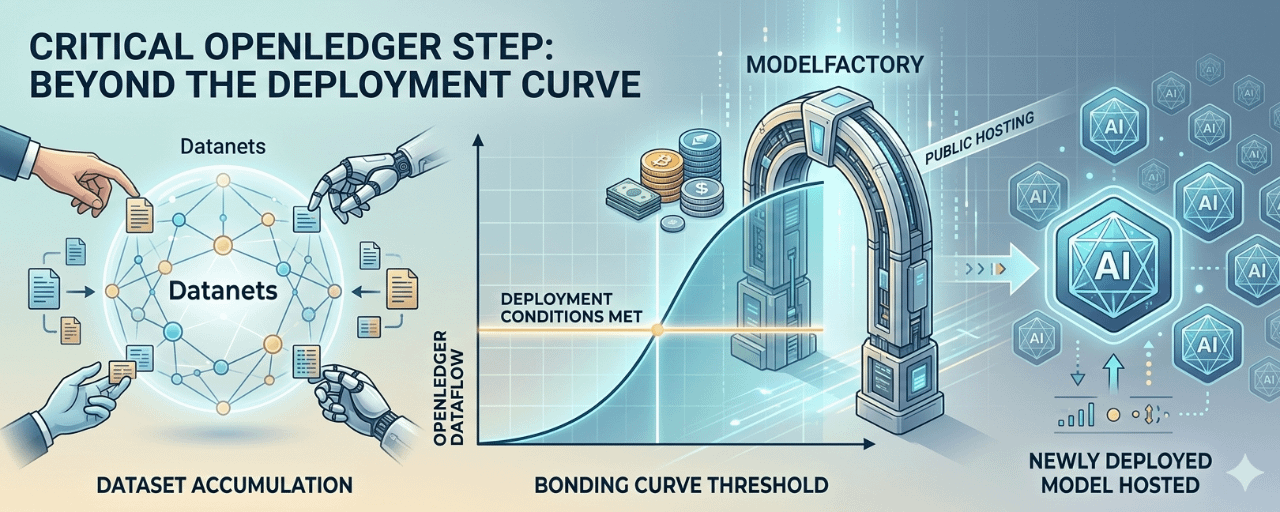
Hay una línea en el whitepaper de @OpenLedger que me detuvo más de lo que esperaba: cuando se recopilan suficientes datos y se alcanza la condición de la bonding curve, el modelo de IA se genera, optimiza y se publica en hosting.
Al principio lo leí como un paso en el proceso.
Hay data. Hay curva. Si cumple con los requisitos, el modelo sale a la luz.
Suena claro. Suena lógico. También es algo fácil de pasar por alto, como una línea técnica entre un montón de conceptos más grandes como Datanets, Proof of Attribution, ModelFactory. Pero cuanto más lo pienso, más me doy cuenta de que esa línea es una puerta muy peligrosa.
Porque la verdadera pregunta no es '¿Cuántos modelos puede crear OpenLedger?'
La verdadera pregunta es: ¿quién tiene derecho a convertirse en modelo?
Solía pensar que la IA descentralizada era mejor cuanta más abierta fuera. Quien tenga un conjunto de datos puede contribuir. Quien tenga una idea puede proponer un modelo. Quien tenga una comunidad puede impulsarlo. Suena muy cripto, muy permissionless, muy en el espíritu de apertura. Pero como he analizado anteriormente sobre el riesgo de Entropía de un Cementerio de Modelos, abrir la puerta absoluta no crea un ecosistema vivo por sí mismo. También puede generar un montón de modelos creados más rápido de lo que hay una verdadera demanda de uso.
La curva de bonding, vista de forma simple, es un filtro. Obliga a un modelo a superar un umbral económico antes de ser hospedado públicamente. Pero el problema es: cripto es muy bueno en convertir todos los filtros económicos en juegos especulativos.
Una curva de bonding puede diseñarse para medir la demanda. Pero en la vida real, es muy fácil medir otra cosa: la velocidad del flujo de capital especulativo. La gente no compra en la curva porque necesite invocar ese modelo, sino porque creen que habrá otros que comprarán a un precio más alto. En el gráfico, estos dos comportamientos parecen similares. El dinero entra. La curva se mueve. El modelo parece 'tener demanda'.
Pero en una economía de IA, son completamente diferentes.
Por un lado está la demanda de inferencias reales. Por el otro, un memecoin disfrazado de modelo.
Este es un punto que creo que OpenLedger necesita ser leído más a fondo. Si la curva de bonding solo mide el dinero, no es lo suficientemente inteligente como para decidir qué modelo merece ser creado. Con la IA, el capital no puede autodenominarse como demanda. El capital debe ir acompañado de evidencia de que el modelo está mejorando, está siendo usado y está generando suficiente valor real para sostener el sistema.
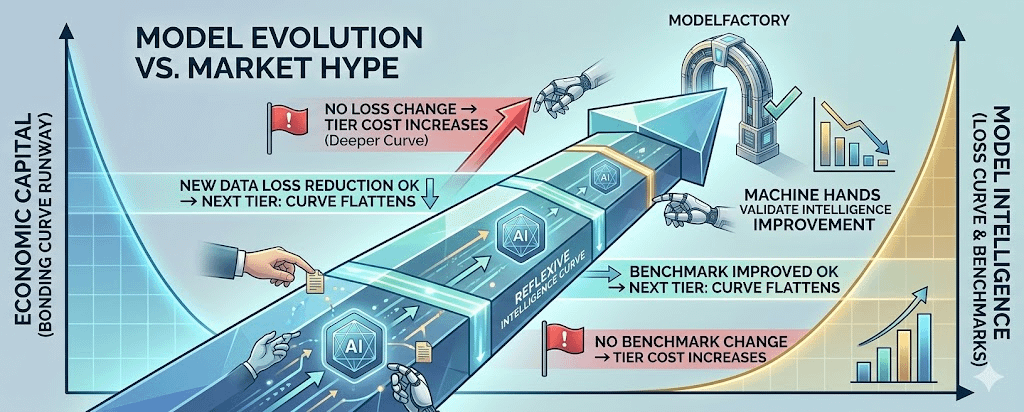
En otras palabras, la curva de bonding de un modelo de IA no debería ser un gráfico de precios. Debería ser una curva de inteligencia reflexiva.
Lo que quiero decir es esto. Durante la fase en que un modelo acumula datos de Datanets y se prepara para ser afinado a través de herramientas como ModelFactory, el sistema no debería solo mirar cuántos $OPEN se están cargando en la curva. También debe observar: ¿los nuevos datos hacen que el modelo reduzca el error? ¿La curva de pérdidas está bajando? ¿Las benchmarks están mejorando? ¿El modelo realmente es más inteligente después de cada nueva capa de datos?
Si la respuesta es no, la curva debe volverse más cara. Más empinada. Más difícil de superar.
Eso es disciplina matemática.
Porque si el dinero sigue fluyendo pero el modelo no aprende nada nuevo, ese flujo ya no es una señal de utilidad. Es una señal de hype. Y el hype no debería tener derecho a ocupar los recursos de infraestructura de una blockchain de IA.
Por el contrario, si los nuevos datos realmente mejoran el modelo, reducen las pérdidas, mejoran las benchmarks, y la salida es más útil, la curva puede aplanarse para facilitar la entrada de capital. En ese momento, el flujo de capital no solo está comprando una historia. Está acompañado de mejoras técnicas.
Pero ser más inteligente aún no es suficiente.
El hosting público no es una insignia de graduación para el modelo. Es el derecho a ocupar recursos físicos: GPU, electricidad, tiempo activo, infraestructura de validadores. Un modelo que se hospeda públicamente sin un uso real significa que alguien sigue pagando por su existencia.
Por lo tanto, el umbral de la curva de bonding no debería ser un número arbitrario como 'suficiente capital para desplegar'. Debería estar más cerca del costo de oportunidad de mantener ese modelo vivo durante un tiempo suficiente para que el mercado lo evalúe. Se podría llamar 'compute runway'. O más crudo: un depósito de energía.
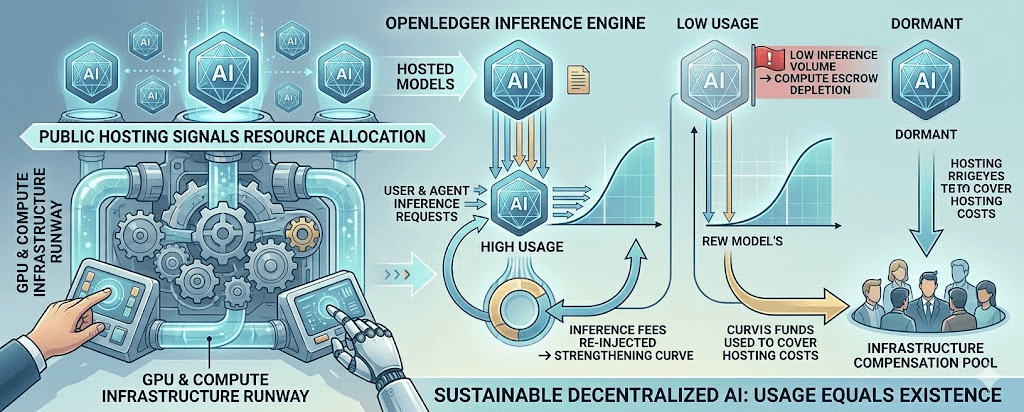
Si el modelo, después de ser públicamente hospedado, no genera suficiente volumen de inferencias para mantenerse, una parte del capital bloqueado en la curva debería usarse para compensar a aquellos que han mantenido la infraestructura para él. Suena un poco frío. Pero si no hay esta disciplina, el sistema recompensará la creación de modelos, en lugar de recompensar la creación de modelos con usuarios reales.
Hasta aquí, debo detenerme. No estoy diciendo que OpenLedger ya tenga un diseño completamente así. El whitepaper solo nos da el punto de partida: un modelo se crea cuando hay suficientes datos y se cumplen las condiciones de la curva de bonding. El resto es inferencia arquitectónica: si queremos que la curva de bonding no se convierta en un mercado especulativo de modelos, necesita estar anclada a inteligencia real y uso real.
Y el uso real debe regresar a la curva.
Cada vez que un usuario o agente invoca el modelo para inferencia, esa línea de tarifas no debería estar fuera del sistema como un ingreso aislado. Debería convertirse en una fuerza atractiva que arrastre la curva hacia el valor de uso. Puede ser mediante recompra, quema, subsidio, o un mecanismo equivalente. La implementación específica puede variar, pero el principio es claro: el estado económico del modelo debe reflejar la frecuencia con la que se consume en el mundo real, no solo debe reflejar la imaginación de los compradores de tokens.
En este punto, los participantes de la curva ya no son simplemente holders. Se asemejan más a compradores anticipados de acceso a la capacidad de computación. Si el modelo es invocado con frecuencia, la línea de inferencia real refuerza el valor de la curva. Si el modelo no se utiliza, la curva revela su vacuidad.
Este es un punto que considero extremadamente importante para OpenLedger.
Datanets ayudan a consolidar el conocimiento. Proof of Attribution ayuda a reconocer quién contribuye a la salida. OpenLoRA permite que muchos modelos pequeños puedan ser servidos de manera más eficiente. Pero la curva de bonding se encuentra en la puerta antes de que todas esas cosas se activen a escala económica.
Si esta puerta se mide mal, OpenLedger puede generar más modelos con gráficos que modelos con demanda.
Si esta puerta se mide correctamente, la curva de bonding ya no será una máquina generadora de activos basura. Se convierte en un filtro evolutivo: el dinero debe ir acompañado de una reducción de pérdidas, el hosting debe ser respaldado por costos reales, y el valor de la curva debe estar anclado a inferencias reales.
En pocas palabras, un modelo no debería generarse solo porque hay suficientes compradores con expectativas.
Debería generarse cuando el sistema pueda responder tres preguntas incómodas:
¿Este modelo ha aprendido mejor gracias a los nuevos datos?
¿Este modelo tiene suficiente capital para soportar los costos de existencia física?
Y lo más importante, ¿hay alguien realmente invocándolo después de que se lanza?
Si la respuesta es sí, la curva de bonding se convierte en arquitectura.
Si no, solo será otra curva de precios en un mercado que ya tiene demasiadas curvas de precios.