
La mayoría de nosotros todavía estamos obsesionados con la pregunta equivocada: ¿qué modelo es más inteligente, más rápido o tiene más financiamiento detrás? Nos deslizamos por los benchmarks, discutimos sobre las puntuaciones de razonamiento y aplaudimos cada nueva ronda de financiamiento como si fuera el final del juego. Pero aquí está lo que he llegado a comprender después de observar este espacio por un tiempo: la verdadera guerra en la IA no será ganada solo por los modelos. Será decidida por quién posee los datos, quién los verifica y, lo más importante, quién realmente recibe el pago por ello.
Piénsalo. Todos los días, las personas alimentan estos sistemas con su conocimiento, sus correcciones, su experiencia en el dominio, su retroalimentación del mundo real. Los modelos recuerdan todo. ¿La economía? Olvida a las personas casi instantáneamente. Una vez que una empresa entrena su modelo, los contribuyentes desaparecen en gran medida de la ecuación. El sistema absorbe el valor y sigue adelante. Ese desequilibrio nos ha estado mirando a la cara durante años, y se siente fundamentalmente roto, como esos primeros juegos de Play-to-Earn que prometían a los jugadores una verdadera propiedad y recompensas pero terminaron apilando todo el valor en la cima.
 Exactamente por eso OpenLedger captó mi atención de una manera que la mayoría de los proyectos de AI-crypto no lo han hecho. No solo están persiguiendo otra narrativa de moda sobre modelos más grandes. Están tratando de construir un sistema donde los datos se conviertan en trabajo rastreable y los contribuyentes realmente acumulen valor económico real a lo largo del tiempo.
Exactamente por eso OpenLedger captó mi atención de una manera que la mayoría de los proyectos de AI-crypto no lo han hecho. No solo están persiguiendo otra narrativa de moda sobre modelos más grandes. Están tratando de construir un sistema donde los datos se conviertan en trabajo rastreable y los contribuyentes realmente acumulen valor económico real a lo largo del tiempo.
Su idea de "AI Pagable" suena simple en la superficie, pero es bastante profunda: los contribuyentes envían conjuntos de datos de alta calidad a Datanets específicos del dominio, los desarrolladores utilizan esos datos para entrenar modelos especializados, y los contratos inteligentes distribuyen automáticamente \u003cc-12/\u003e recompensas basadas en la contribución real. No más extracción invisible. Los datos tienen procedencia, la influencia puede ser medida y la economía fluye de regreso a las personas que crearon el valor.
Lo que me destaca aquí es el motor de Prueba de Atribución que han estado implementando. La parte basada en gradientes para modelos más pequeños tiene sentido: si eliminar un punto de datos claramente perjudica el rendimiento, esos datos tienen un valor medible. Pero la parte más ambiciosa es su atribución de tokens mediante arreglo de sufijos para modelos de lenguaje más grandes. Rastrear exactamente qué partes del corpus de entrenamiento influyeron en tokens de salida específicos siempre ha sido increíblemente difícil. Las salidas se sienten colectivas y borrosas. Intentar hacer eso transparente es un problema técnico genuinamente complicado, y no están pretendiendo que sea perfecto, pero al menos están tratando de construir responsabilidad en lugar de solo optimizar para la extracción.
El lado legal es otra parte que parece estar a la vanguardia. Su asociación con Story Protocol es inteligente porque a medida que la AI se adentra más en el uso comercial, especialmente en medicina, finanzas, derecho o cualquier campo regulado, las empresas no solo preguntarán: "¿qué tan bueno es este modelo?" Querrán saber: ¿Está verificado este conjunto de datos? ¿Licenciado? ¿Legalmente limpio? ¿Defendible? Tener atribución en cadena más una correcta licencia de propiedad intelectual podría convertirse en una ventaja competitiva masiva.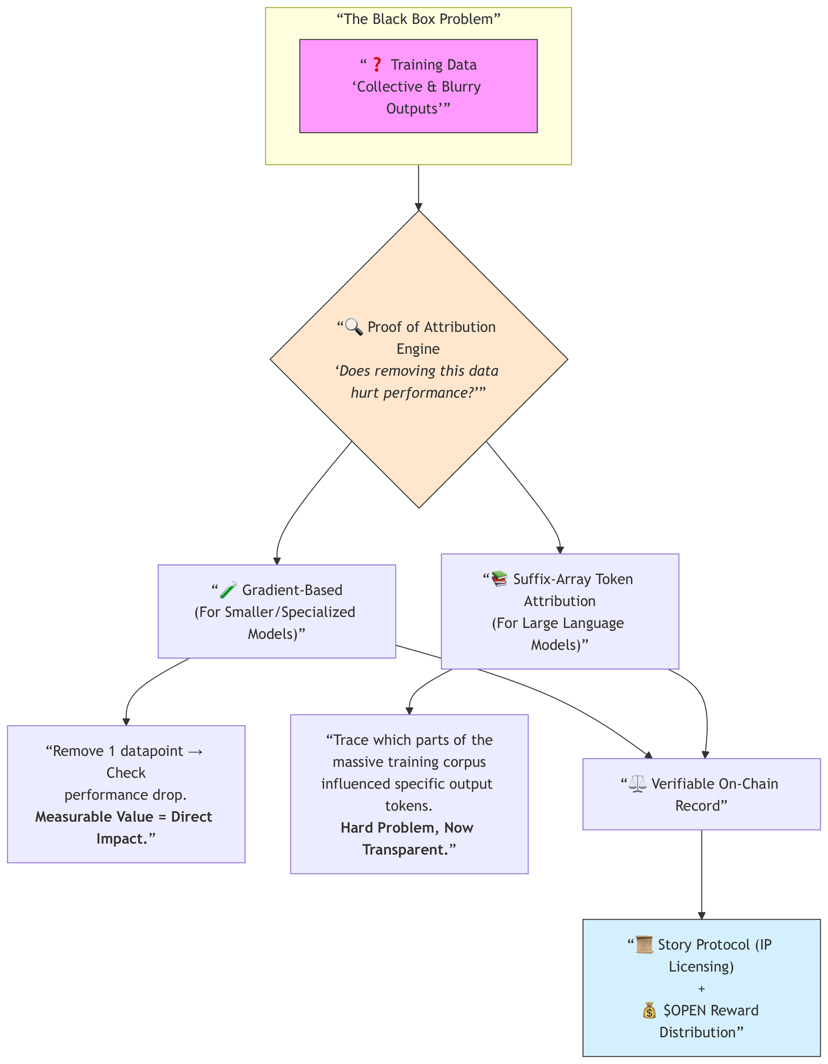
Y los números de su fase de testnet realmente le dan peso a esto: más de 6 millones de nodos registrados, 25 millones+ de transacciones y 20,000 modelos de AI construidos antes de que mainnet siquiera se activara a finales del año pasado. Eso no es solo hype en papel; muestra participación real y pruebas de escala. Ahora que mainnet está operativo con más de 40 proyectos ya construyendo en él, comienza la verdadera prueba.
Porque seamos honestos: donde fluyen los verdaderos dineros, siguen los malos comportamientos. Vamos a ver juegos de tabla de clasificación, spam de datos sintéticos de baja calidad, disputas de atribución y gente tratando de optimizar para recompensas en lugar de calidad. La capa de validación y la alineación de incentivos a largo plazo decidirán si esto realmente funciona a gran escala o se convierte en otro experimento interesante.
Aun así, respeto que OpenLedger esté abordando la incómoda pregunta que la mayoría de la industria ha estado evitando: Si las personas comunes ayudan a crear el valor en estos sistemas de AI... ¿recordará el sistema a ellos?
Esa parece ser la pregunta correcta para hacerse en 2026. Las guerras de modelos continuarán, pero los proyectos que logren una propiedad y atribución de datos justa y transparente podrían tener la ventaja más duradera, tanto técnica como económicamente.
¿Qué piensas? ¿La propiedad de datos va a ser la verdadera ventaja en AI, o todavía estamos a años de sistemas que realmente recompensen a los contribuyentes de manera justa? Tengo curiosidad genuina sobre dónde aterriza esto a largo plazo.
\u003cm-27/\u003e
\u003ct-6/\u003e
\u003cc-44/\u003e
