
OpenLedger ha estado en mi mente por un tiempo, no por el hype, sino porque toca de manera sutil una pregunta que creo que la mayoría de la gente en crypto aún subestima.
¿Quién realmente posee la inteligencia de la que las máquinas están aprendiendo?
Cuanto más profundizo en la IA, más extraña se siente esta pregunta. Hablamos interminablemente sobre modelos, potencia de cómputo, chips, escalabilidad y sistemas de miles de millones de parámetros. Pero muy pocas personas se detienen a preguntar de dónde proviene realmente el valor original. Cada sistema de IA está aprendiendo de información creada por humanos de una forma u otra. Conversaciones, escritos, imágenes, decisiones, patrones, correcciones, preferencias, todo eso proviene de las personas.
Sin embargo, la mayoría de los contribuyentes son invisibles una vez que el modelo tiene éxito.
He estado pensando mucho en esto últimamente porque la economía actual de internet ya tiene un extraño desequilibrio. Las personas crean valor constantemente, pero muy pocos realmente poseen los sistemas que se benefician de ello a largo plazo. Las plataformas sociales monetizan la atención. Las empresas de datos monetizan el comportamiento. Las empresas de IA monetizan la inteligencia entrenada a partir de enormes grupos de información generada por humanos. Mientras tanto, el contribuyente promedio rara vez sabe a dónde va su data o cuánto valor crea después.
Esa brecha me resulta incómoda.
Y honestamente, creo que cripto ha estado buscando una respuesta significativa a este problema durante años sin darse cuenta completamente.
Muchos proyectos de blockchain se centraron primero en la propiedad financiera. Tokens, liquidez, incentivos, especulación. Pero la IA introduce otra capa completamente. Ahora la pregunta no es solo quién posee el dinero. Se convierte en: ¿quién posee la inteligencia misma?
Ahí es donde OpenLedger comenzó a volverse interesante para mí.
No porque afirme que "revoluciona la IA", sino porque su estructura está intentando resolver un problema muy específico que sigue creciendo a medida que la IA avanza.
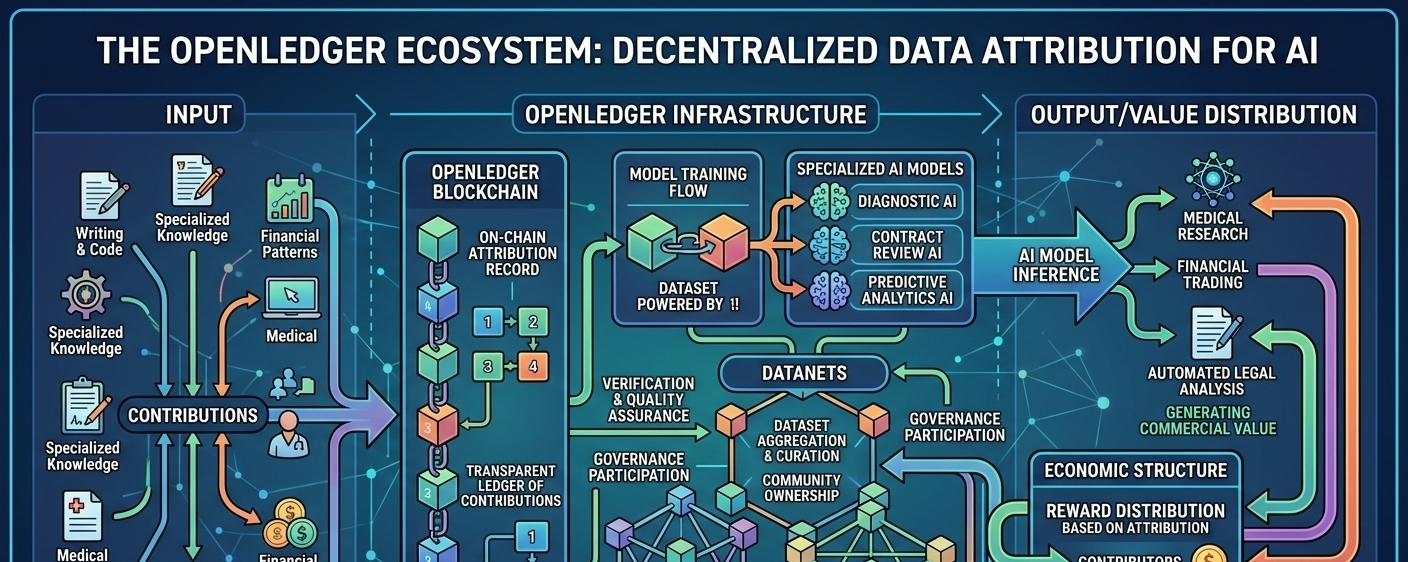
La idea central detrás de OpenLedger es sorprendentemente simple cuando se despoja del lenguaje técnico. En lugar de tratar los datos de entrenamiento de IA como un recurso oculto controlado por unos pocos sistemas centralizados, OpenLedger intenta convertir los conjuntos de datos en infraestructura de propiedad comunitaria. Los llaman Datanets. Las personas pueden contribuir datos, construir conjuntos de datos juntos, entrenar modelos especializados y tener esas contribuciones registradas de manera transparente en la cadena.
Lo que llamó mi atención no es solo la parte de blockchain. Hemos visto muchos proyectos añadir blockchain a cosas antes. Lo que parece más importante aquí es la atribución.
En la mayoría de los sistemas de IA hoy en día, una vez que un modelo está entrenado, el origen del valor se vuelve borroso. Puede que nunca sepas de quién fue la data que ayudó a dar forma al modelo o quién debería beneficiarse cuando ese modelo se use comercialmente más tarde. OpenLedger parece abordar la IA de manera diferente al intentar rastrear las contribuciones a lo largo del ciclo de vida del propio sistema.
Eso cambia la psicología de la participación.
En lugar de que las personas alimenten los sistemas ciegamente, la infraestructura intenta crear responsabilidad en torno a la contribución, uso y recompensas. Si un modelo genera valor más tarde a través de inferencia o implementación, el ecosistema puede teóricamente rastrear de dónde provino esa inteligencia y distribuir las recompensas en consecuencia.
Creo que esto importa más de lo que muchas personas se dan cuenta.
Porque la futura economía de IA puede no tratar simplemente sobre quién construye los modelos más grandes. Puede que se trate de quién construye las redes de conocimiento más confiables y especializadas.
Los modelos de IA general son impresionantes, pero en el mundo real, la inteligencia especializada a menudo importa más. Sistemas médicos, sistemas legales, sistemas financieros, sistemas industriales, estas áreas requieren conjuntos de datos altamente específicos y contribuyentes confiables. Y la verdad es que los datos especializados de alta calidad son extremadamente difíciles de recopilar y mantener.
Ahí es donde los conjuntos de datos de propiedad comunitaria se vuelven interesantes.
OpenLedger está esencialmente tratando de crear un sistema donde los contribuyentes, desarrolladores y constructores de modelos existan dentro de la misma estructura económica en lugar de estar desconectados entre sí. Las cargas de datos, el entrenamiento de modelos, la participación en la gobernanza e incluso la atribución de inferencias están todas conectadas a través de la cadena misma.
En términos simples, el sistema intenta recordar quién ayudó a construir la inteligencia.
Honestamente, creo que esa idea se siente más grande que las discusiones sobre tokens en las que la gente suele centrarse.
Porque si la IA se convierte en una de las capas fundamentales de la economía de internet, entonces la atribución puede convertirse en uno de los problemas más importantes en tecnología. Sin atribución, el valor se concentra de manera agresiva. Con atribución, el valor puede circular de manera más justa entre los contribuyentes y los sistemas.
Por supuesto, nada de esto es fácil.
Una cosa que sigo cuestionando es si la coordinación descentralizada puede realmente competir con la velocidad y eficiencia de los gigantes de IA centralizados. El desarrollo de IA a gran escala requiere una infraestructura enorme, optimización constante y capital masivo. Los sistemas abiertos suelen moverse más lentamente porque la gobernanza, la transparencia y la participación comunitaria naturalmente introducen fricción.
También está el desafío de la calidad de los datos en sí.
Abrir sistemas de contribución a comunidades suena poderoso, pero mantener conjuntos de datos fiables a gran escala es difícil. Los incentivos pueden mejorar la participación, pero también pueden atraer ruido si los sistemas de verificación son débiles. Así que creo que el éxito a largo plazo de proyectos como OpenLedger dependerá en gran medida de si pueden mantener tanto la apertura como la calidad al mismo tiempo.
Aún así, no puedo ignorar la importancia de la dirección.
Durante años, muchas personas vieron el blockchain principalmente como infraestructura financiera. Pero la IA puede empujar al blockchain hacia algo más filosófico: la propiedad del trabajo digital, la propiedad del conocimiento, la propiedad de la contribución misma.
Eso se siente como una conversación mucho más profunda.
Y tal vez por eso OpenLedger sigue ocupando mis pensamientos. No porque tenga todas las respuestas, sino porque toca un problema que internet aún no ha resuelto adecuadamente.
Si los sistemas de IA siguen absorbiendo inteligencia humana a escala global, ¿deberían los contribuyentes permanecer invisibles para siempre?
¿Debería el flujo de valor de la IA dirigirse solo hacia las empresas que operan los modelos, o deberían las personas que ayudan a crear la inteligencia también participar en los beneficios?
Y si la atribución se convierte en programable a través de sistemas de blockchain, ¿podría eso lentamente reconfigurar cómo funcionan la confianza y la propiedad en línea?
No creo que la industria entienda completamente el peso de estas preguntas aún.
Pero creo que los proyectos que exploran esta dirección valen la pena seguirlos de cerca, especialmente a medida que la IA y el blockchain comienzan a superponerse más profundamente en los próximos años.
Al final, sigo volviendo a un pensamiento simple.
Quizás el futuro de la IA no solo se definirá por cuán inteligentes se vuelven los modelos.
Quizás también se definirá por si las personas detrás de la inteligencia son finalmente vistas.
\u003cm-76/\u003e \u003cc-78/\u003e \u003ct-80/\u003e \u003ct-82/\u003e