

I used to think the hard part of AI training was mostly about having enough data and enough machines to process it but my view has changed as I have looked more closely at DataNet in the OpenLedger sense. It now feels less like a response to the simple problem of finding more data and more like a response to a deeper problem around knowing what data mattered who supplied it whether it was useful and whether contributors should share in the value that came from it.
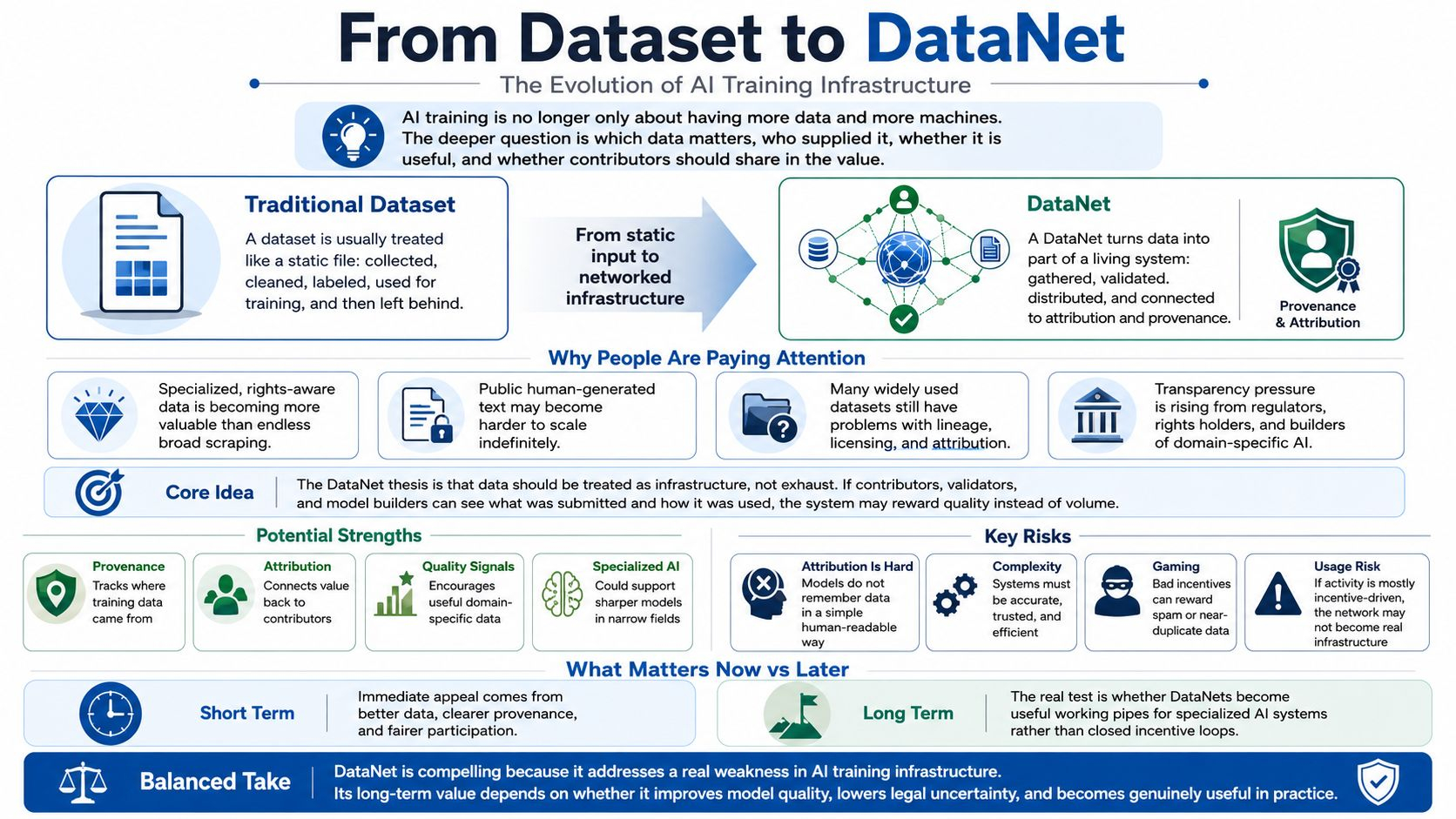
That is why the move from dataset to DataNet matters. A normal dataset is usually treated like a file that gets collected cleaned labeled used for training and then left behind once the model has moved forward. DataNet tries to make that input more alive by turning it into part of a wider system where data is gathered validated and distributed for domain specific AI training with attribution built into the structure. OpenLedger describes Datanets as structured data networks with metadata and timestamps so models can record training provenance and connect later outputs back to earlier data contributions.
I find it helpful to see this as a bet on smaller and sharper intelligence rather than endless scraping. AI already has plenty of broad text but what is becoming more valuable is clean specialized and rights aware data from people who understand a field well enough to know what quality looks like. Epoch AI estimated in 2024 that if current trends continue language models may use up the effective stock of public human generated text sometime between 2026 and 2032. The Data Provenance Initiative also audited 1,858 widely used datasets and found that lineage licensing and attribution remain serious problems.
So DataNet is getting attention now because the old bargain around training data is becoming less comfortable. Five years ago the market could still act as if scale would cover many sins because bigger corpora and bigger models often seemed to produce better results. Now the questions are messier as regulators ask for transparency rights holders push back and builders look for models that work reliably in narrow areas such as coding health law sensors and finance. California’s training data transparency law effective January 1 2026 is one sign that disclosure around training sources is becoming a business concern.
The strong part of the DataNet thesis is that it treats data as infrastructure rather than exhaust. If contributors validators and model builders all have a visible record of what was submitted and how it was used then the system can in theory reward quality instead of volume. That could matter for developers experts with useful data and market participants who are trying to judge whether a network has real usage rather than only attention. I would watch for the less exciting signals that usually matter most such as active Datanets clear validation standards actual models using those datasets inference activity and reward flows that are not dependent on early incentives.
The weak part is just as important because attribution in AI is hard and a model does not usually remember data in a clean human readable way. OpenLedger’s paper describes different methods for smaller models and large language models which suggests the system is adapting to technical limits rather than magically solving them. That is honest but it also means the vision depends on whether attribution is accurate enough to be trusted cheap enough to run and simple enough for people to understand. There is also a market design risk because if rewards favor people who game validation or flood the network with near duplicate data then DataNet could recreate the noise problem it is trying to fix.
My market view is cautious but interested. In the short term DataNet’s appeal is clear because AI needs better data data needs provenance and contributors want a fairer role. But the long term value will not come from the story. It will come from whether DataNets become useful working pipes for specialized AI systems. If builders choose them because they improve model quality reduce legal uncertainty or make expert data easier to source then the idea has weight. If usage stays circular and is driven mainly by rewards and token mechanics then it remains more experiment than infrastructure. What surprises me is that the basic question feels less like crypto versus AI and more like accounting because the real test is whether we can finally keep a reliable ledger of what intelligence is made from.


