现在外面AI板块的股票和代币涨得漫天飞,很多人可能纳闷:除了英伟达卖显卡、卖设备能实打实赚到钱,普通的 AI 软件和网络到底怎么运转、怎么搞钱?
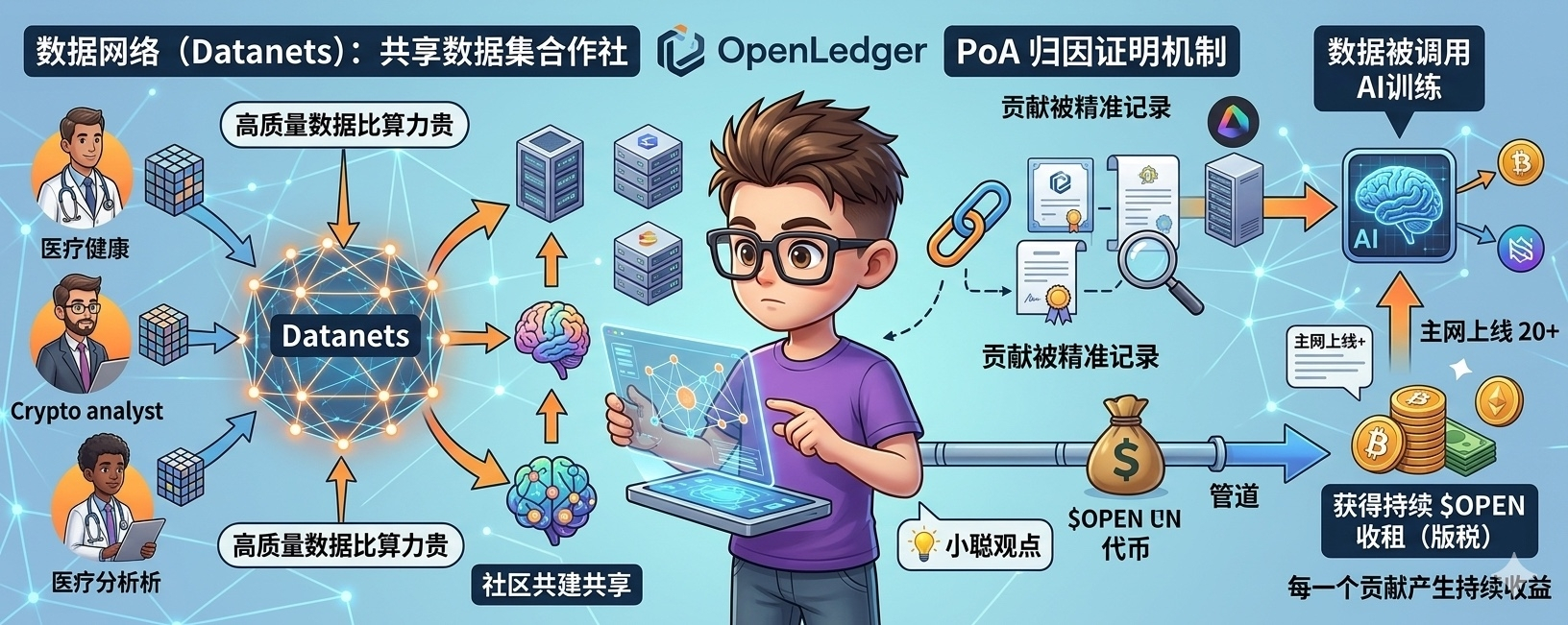
今天咱们就聊个能让普通人看得懂、甚至能直接参与的硬核落地项目 @OpenLedger 。之前跟大家盘过它的“归因证明”和“验证者角色”,听着挺硬,今天换个大白话,聊聊它生态里最接地气、最体现Web3组团分赃精神的板块:数据网络(Datanets)
搞定大厂垄断,AI时代的数据“土改”
大家都盯着算力,其实现在训练AI最贵的不是显卡,而是高质量、有版权的专业数据。以前这些数据全被互联网大厂白嫖了,拿去喂饱了AI,普通人一毛钱收益都分不到
OpenLedger走了一条相反的路:既然大厂垄断,那咱们就搞“数据合作社”
它的玩法很简单,主要分三步:
发任务(OpenTask):官方或市场根据实际需要,发布特定的数据采集或标注任务
专业人干专业事:你不需要是顶尖的科学家,只要在某个领域有经验就行。比如懂医疗的去标病例影像(MedNet405数据集),懂链上数据的去维护治理数据(Ethra401数据集),甚至平时肯花时间整理资料的都能上
一次劳动,终身收租:重点来了!你做的每一次贡献,都会被平台的PoA(归因证明)机制死死记录在链上。以后只要有AI模型调用了你标注的数据去训练,代币 $OPEN 就会自动打进你的钱包。这不叫一次性打工,这叫数字资产的管道收益。
截至今年4月底,这套主网上已经悄悄跑起来 20 多个垂直数据网络了,覆盖了医疗、金融、加密治理等各种高产值领域
从理论到标配:市场开始买单了
概念讲得再性感,没人用就是空气。但Datanets 最近的动作明显是正规军进场的节奏。
它接连拿下了Astro AI、Pundi AI、DGrid AI 等一众垂直领域项目的深度合作,这些项目直接把自己的 AI 应用和算力网络塞进了OpenLedger 的数据层里#OpenLedger
这意味着什么?Datanets正在变成去中心化 AI 行业公认的“数据标准件”。就像以后不管大厂小厂、甚至是网石(Netmarble)这类游戏巨头,只要想用干净、合规、高质量的去中心化数据,都得来这调用。只要调用,代币OPEN的消耗就是刚需
💡小聪观点
老规矩,咱们不吹不黑,把格局打开看
Web3喊了这么多年“数据资产化”,大都停留在钱包里的空气或者概念。OpenLedger这次算是把“数据即资产、建设即挖矿”的底层逻辑给跑通了。让专业知识不再躺在硬盘里吃灰,而是变成 AI 进化的燃料,还能顺便帮普通人搞点被动收入,这才是Web3结合AI该有的质朴模样
不过,老韭菜的风险提示依然得挂在嘴边:
既然是“数据合作社”,最核心的生命线就是“数据质量control”。主网上线20多个网络只是第一步,随着合作项目越来越多,怎么确保链上源源不断涌入的数据不是AI批量生成的垃圾噪音?另外,专业领域(如医疗、金融)的高净值人群,愿不愿意为了现阶段的代币激励去长期“用爱发电”做人肉标注?这非常考验项目方后续的实际造血能力和代币价格的稳定性
逻辑顺畅,应用在跑,这就比纯靠CX叙事拉盘的项目靠谱得多。建议保持高强度关注,盯着它后续真实调用量的增幅再决定怎么打手里的子弹,切忌盲目Fomo
(以上内容属个人观点仅供参考)