

he estado pensando en el enfoque de “IA transparente” de OpenLedger, y la verdad, lo interesante no es solo que pone la IA en la cadena.
Esa línea es demasiado fácil.
Muchos proyectos dicen “IA + blockchain” y luego el diseño real se convierte en una capa de token alrededor de algo mayormente normal. Un mercado. Un envoltorio de computación. Una campaña de recompensas. Tal vez un panel con algo de actividad del modelo. Útil a veces, pero realmente no es una nueva capa de responsabilidad.
La afirmación más interesante de OpenLedger es diferente: quiere que la atribución esté dentro del ciclo de vida de la IA misma.
Eso importa porque el aprendizaje automático tiene un problema de propiedad silencioso. Los modelos no aparecen de la nada.
Las respuestas de AI están moldeadas por muchas cosas: datos, entrenamiento, input humano, feedback y demanda de los usuarios. El problema es que, cuando alguien ve el resultado final, generalmente no sabe quién o qué ayudó a crearlo. La salida llega limpia. El rastro detrás de ella desaparece.
OpenLedger está tratando de hacer visible ese camino.
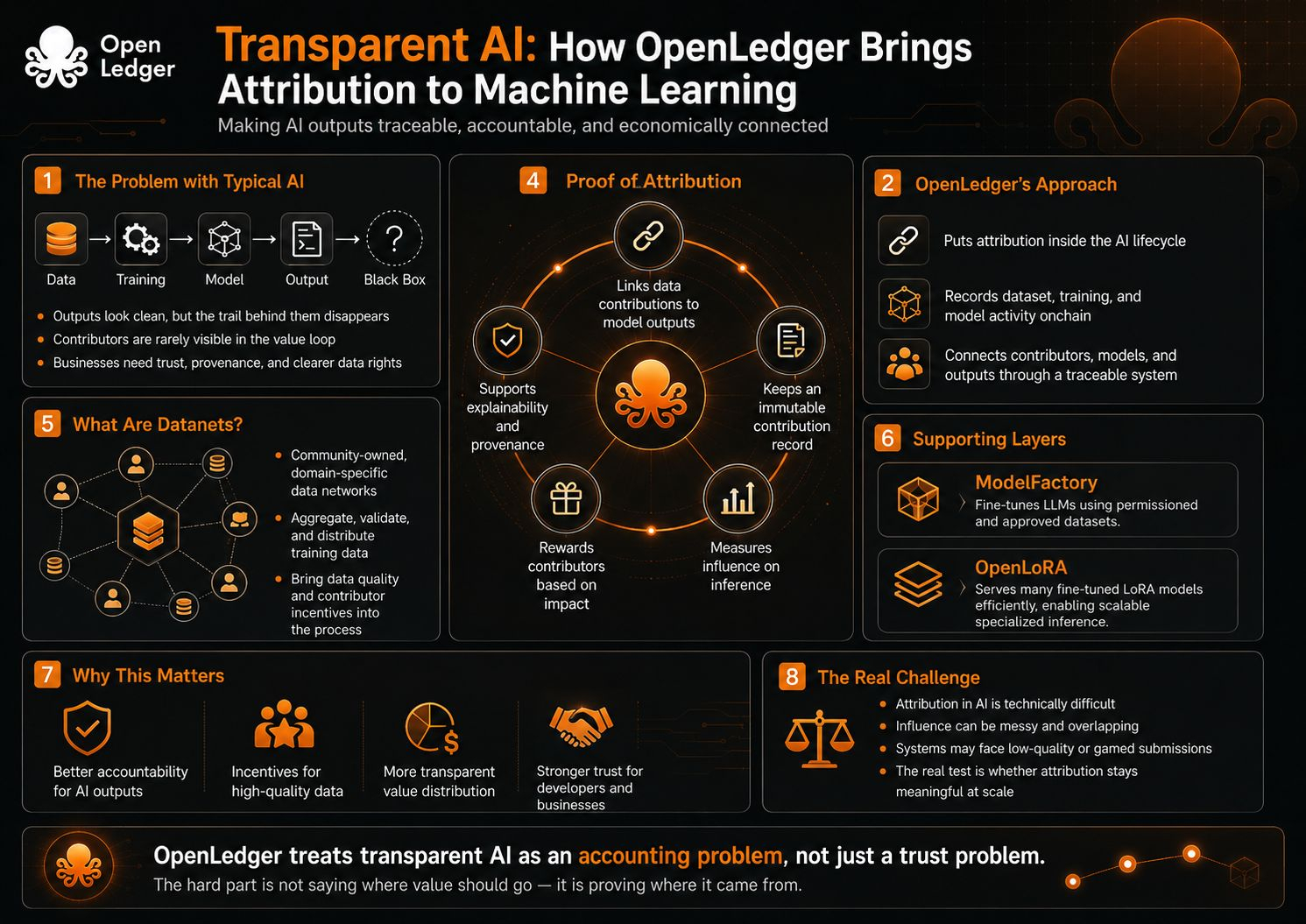
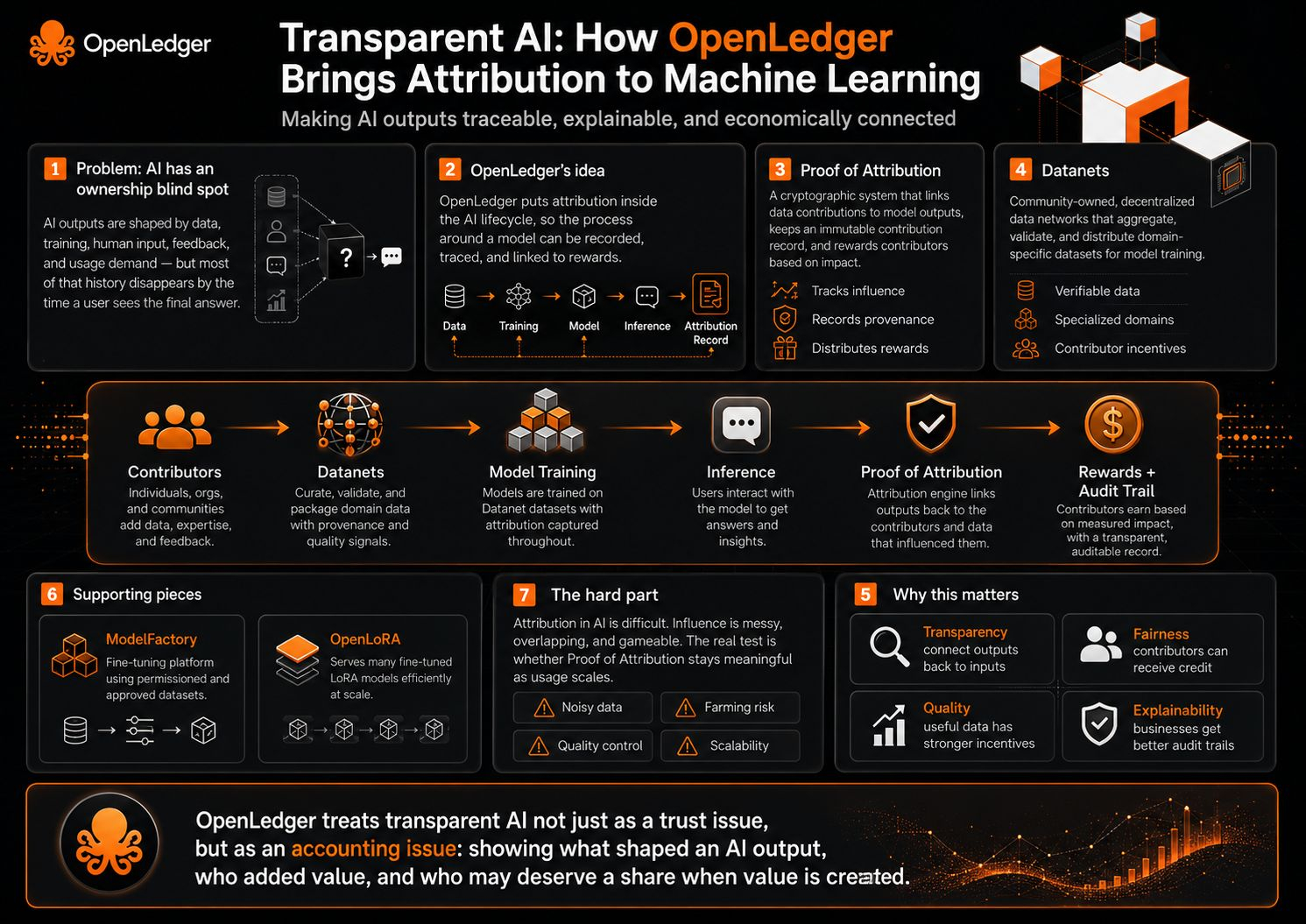
Sus documentos describen OpenLedger como una infraestructura de AI-blockchain para entrenar y desplegar modelos especializados utilizando Datanets de propiedad comunitaria, con cargas de conjuntos de datos, entrenamiento de modelos, créditos de recompensa y participación en la gobernanza ejecutados en la cadena. Ese marco es importante porque no solo dice 'usa nuestro modelo de AI'. Dice que el proceso alrededor del modelo debe ser registrado, rastreado y conectado económicamente.
lo que captó mi atención:
La Prueba de Atribución es el mecanismo central aquí. Los documentos de OpenLedger la describen como un sistema criptográfico que vincula las contribuciones de datos a las salidas del modelo de AI, mantiene un registro inmutable de las contribuciones y recompensa a los contribuyentes según el impacto de sus datos. En palabras simples, el modelo no solo responde. El sistema intenta mostrar qué entradas ayudaron a dar forma a esa respuesta, y quién debería recibir crédito por esa influencia.
Eso suena simple hasta que lo comparas con cómo suele funcionar la AI.
En la economía normal de AI, el valor fluye hacia arriba. Se recopilan datos. Se entrenan modelos. Se construyen productos. Los usuarios pagan. Los contribuyentes, si es que son visibles, suelen estar fuera del ciclo del dinero. Su trabajo se convierte en parte de la máquina, pero la máquina no los recuerda de ninguna manera económica útil.
OpenLedger está básicamente preguntando: ¿y si la máquina tuviera memoria?
No memoria emocional. Memoria de atribución.
La parte de Datanets lo aclara más. OpenLedger describe Datanets como redes de datos descentralizadas que agregan, validan y distribuyen conjuntos de datos específicos de dominio para el entrenamiento de modelos de AI. Los contribuyentes proporcionan datos de alta calidad con atribución verificable, y el sistema está destinado a hacer que la credibilidad de los datos y los incentivos para los contribuyentes sean parte del proceso de entrenamiento en lugar de un pensamiento posterior.
Ahí es donde 'AI transparente' se convierte en algo más que un eslogan.
La transparencia aquí no solo se trata de decir a los usuarios que existe un modelo. Se trata de conectar la salida de vuelta a los ingredientes. ¿Qué conjunto de datos importó? ¿Qué contribuyente añadió valor? ¿Qué modelo o adaptador se utilizó? ¿Fueron los datos útiles, redundantes, sesgados o de baja calidad? El pipeline de atribución de OpenLedger incluso describe la puntuación de influencia, los registros de entrenamiento, la distribución de recompensas basada en el impacto y las penalizaciones por contribuciones maliciosas o de baja calidad.
la parte a la que sigo volviendo:
Esto no es solo un mecanismo de equidad. También es un mecanismo de calidad.
Si los contribuyentes pueden ser recompensados cuando sus datos mejoran la inferencia, entonces los datos útiles tienen una razón para sobresalir. Si los datos débiles o adversariales pueden ser penalizados, entonces el sistema tiene al menos alguna presión contra las entradas basura. Eso no resuelve mágicamente la calidad de la AI. Nada lo hace. Pero crea un mapa de incentivos diferente al habitual modelo de 'raspa todo, oculta las fuentes, monetiza la salida'.
La investigación de Binance describe la Prueba de Atribución de OpenLedger como un sistema que identifica los puntos de datos que moldean la salida de un modelo y recompensa a los contribuyentes, al mismo tiempo que apoya la explicabilidad y la procedencia a lo largo del ciclo de vida de la AI. Esa redacción está haciendo mucho trabajo. La atribución no se trata solo de pago. También se trata de poder inspeccionar de dónde vino una respuesta.
Esta puede ser la mejor razón por la que OpenLedger importa. La AI está creciendo rápido, pero la mayor parte se siente como una caja negra. Los usuarios ven la respuesta final, pero no los datos detrás de ella. Para las empresas, eso es un gran problema porque necesitan confianza, prueba y derechos de datos limpios. Los desarrolladores quieren mejores conjuntos de datos, pero los buenos contribuyentes necesitan una razón para participar. La respuesta de OpenLedger es convertir la inferencia en un evento económico rastreable, donde la influencia de los datos puede ser medida y recompensada en lugar de desaparecer en la caja negra.
ModelFactory encaja en esta misma dirección. Los documentos lo describen como una plataforma de ajuste fino para LLMs bajo el ecosistema de OpenLedger, utilizando conjuntos de datos que han sido autorizados y aprobados a través de OpenLedger. Eso sugiere que el proyecto no solo está pensando en la atribución después de que se construya el modelo, sino también en el camino controlado desde el conjunto de datos hasta la creación del modelo.
OpenLoRA añade otra capa. Se describe como un marco para servir miles de modelos LoRA ajustados en una sola GPU, con carga dinámica de adaptadores e inferencia eficiente. Eso importa porque la atribución es más útil cuando los modelos especializados pueden ser realmente desplegados y utilizados a escala. De lo contrario, la capa de atribución permanece teórica.
mi preocupación, sin embargo:
La atribución en AI es difícil. Muy difícil.
Decir 'este dato influyó en esta salida' no es lo mismo que probarlo de una manera que todos acepten. El comportamiento del modelo es desordenado. La influencia del entrenamiento no siempre es obvia. Puntos de datos similares pueden superponerse. Una contribución puede importar indirectamente. Los actores maliciosos pueden intentar manipular las puntuaciones de influencia. Y una vez que el dinero entra en el ciclo, las personas optimizarán para recompensas, no para pureza.
Así que la verdadera prueba para OpenLedger no es si la idea suena justa. Lo es.
La verdadera prueba es si la Prueba de Atribución puede mantenerse significativa cuando el sistema se vuelve ruidoso: más Datanets, más contribuyentes, más modelos, más presentaciones de baja calidad, más demanda de inferencia y más personas tratando de cultivar atribuciones en lugar de crear valor.
Ahí es donde creo que OpenLedger se vuelve interesante de seguir.
Porque si funciona, incluso parcialmente, le da a la AI algo que le falta urgentemente en este momento: una memoria de contribución. No solo quién construyó el modelo. No solo quién posee la aplicación. Sino quién proporcionó el conocimiento, quién mejoró la salida y quién merece una parte cuando esa salida crea valor.
La AI transparente generalmente se discute como un problema de confianza.
OpenLedger lo está tratando más como un problema contable.
Y quizás esa sea la versión más seria. No 'confía en nosotros, esta AI es transparente', sino 'aquí está el registro de lo que la moldeó.'
observando: si la atribución se mantiene precisa bajo el uso real, si los contribuyentes realmente ganan recompensas significativas, si los Datanets atraen datos especializados de alta calidad, y si OpenLedger puede evitar convertirse en otro sistema donde la transparencia suena bien hasta que los incentivos se saturen.
porque la idea es fuerte.
Pero en AI, la parte difícil nunca es decir a dónde debería ir el valor.
La parte difícil es probar de dónde vino.
@OpenLedger #OpenLedger $OPEN $BLUAI
