He estado trabajando para la IA durante años sin recibir un centavo.
Cada búsqueda, cada clic, cada segundo extra pasado en una página se convirtió en datos de entrenamiento para el modelo de alguien más. Sin notificaciones. Sin pagos. Solo términos de servicio que nadie lee.
Nadie lo llama extracción porque el producto aún se siente gratuito.
Para los traders, esto va aún más profundo. Flujo de órdenes, tiempo de entrada, patrones de tamaño — cosas que tomaron años en desarrollarse — pueden convertirse silenciosamente en datos de entrenamiento conductual en el momento en que pasan por una plataforma con una capa de IA por debajo.
OpenLedger está tratando de construir un modelo diferente.
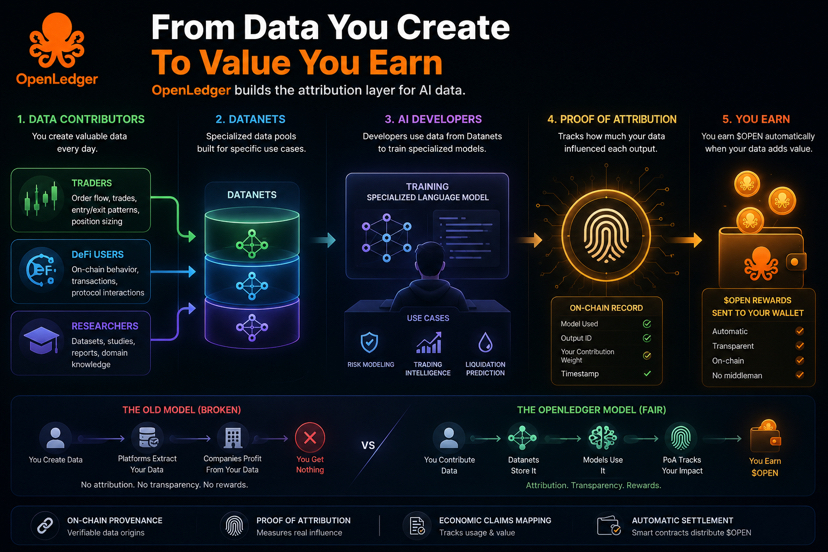
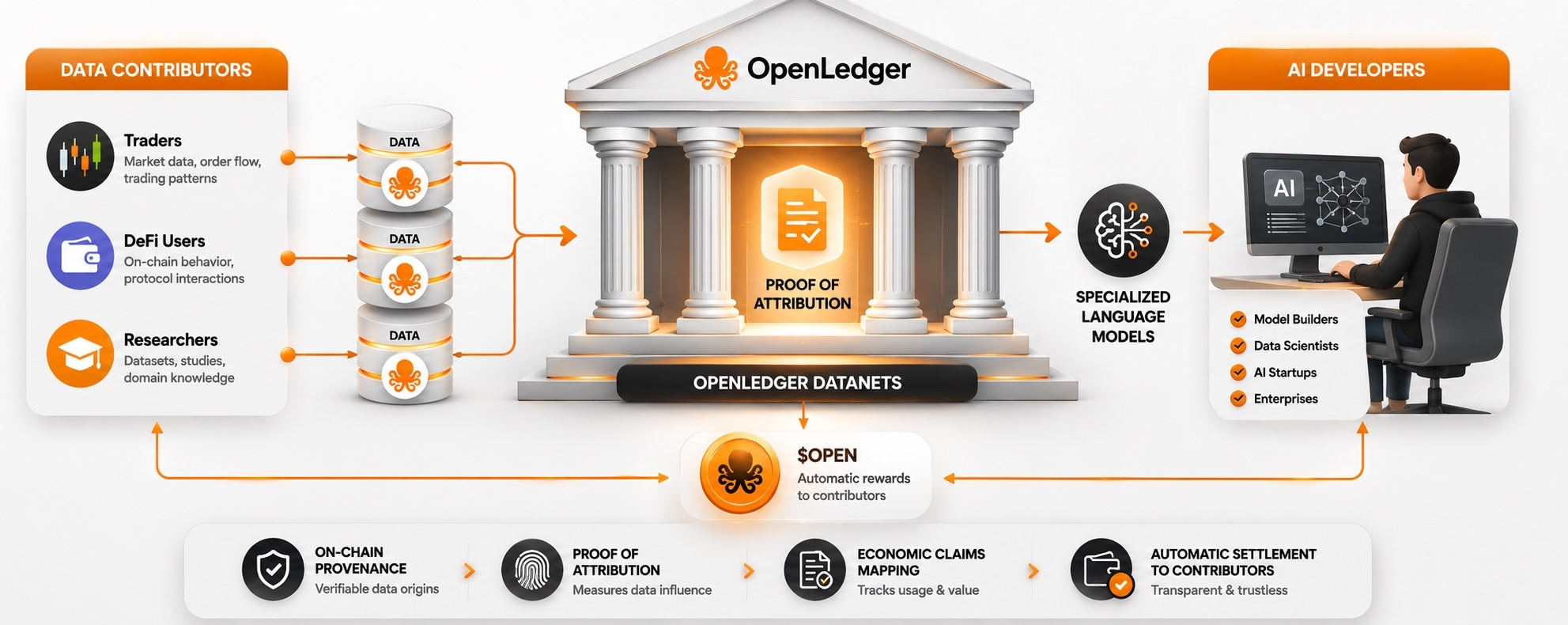
En lugar de que las plataformas cosechen datos a puerta cerrada, construyeron Datanets: grupos de datos especializados donde los contribuyentes suben información de manera intencionada. Comportamiento de trading en DeFi. Historial de liquidaciones. Patrones de tasas de financiación entre venues. Cualquier conjunto de datos útil para entrenar modelos de IA específicos de dominio.
Los desarrolladores extraen de esos grupos para entrenar Modelos de Lenguaje Especializados para casos de uso específicos. Cuando esos modelos generan salidas utilizando datos contribuidos, Proof of Attribution rastrea la influencia en la cadena y OPEN se distribuye automáticamente a los contribuyentes. Sin proceso de pago manual. Sin división de ingresos opaca. El contrato inteligente maneja la atribución y el asentamiento directamente.
El diseño técnico de PoA es más interesante que las recompensas en sí.
No opera en un sistema simple de subir más y ganar más. Mide el peso de la contribución, no el volumen de la contribución. Un conjunto de datos más pequeño que moldea consistentemente el comportamiento del modelo puede ganar más que un conjunto de datos masivo que apenas cambia la salida. Los contribuyentes no solo están proporcionando entradas crudas. Están teniendo exposición económica al rendimiento del modelo en sí.
Esa es la parte que llamó mi atención. No el token. El mecanismo.
La mayoría de los proyectos de IA en crypto se detienen en la capa de observación: tableros, herramientas de sentimiento, sistemas que le dicen a los usuarios qué mirar. OpenLedger está tratando de operar más abajo en la pila: la capa de infraestructura donde los datos se obtienen, verifican, atribuyen y transforman en algo de lo que los modelos realmente pueden aprender.
El trabajo de infraestructura suele ser ignorado porque se ve aburrido al principio. Hasta que toda la pila depende de ello.
Pero la verdadera pregunta no es la atribución. Es el control de calidad.
PoA puede rastrear si los datos influyeron en la salida de un modelo. Eso no significa que los datos fueran útiles, precisos o limpios. El incentivo para los contribuyentes sigue siendo financiero, y los incentivos financieros a menudo optimizan la escala antes que la calidad. Una Datanet abierta sin una fuerte curación se llena rápidamente de ruido. Y un modelo especializado entrenado con datos contaminados no se vuelve inteligente. Se vuelve estrechamente seguro.
Esa es la parte que sigo observando de cerca.
No el whitepaper. No los anuncios de asociaciones. El entorno de producción después de que los verdaderos desarrolladores comiencen a construir en Datanets reales a gran escala. Ahí es cuando descubrimos si los mecanismos de filtrado son lo suficientemente fuertes como para mantener la calidad de la señal a lo largo del tiempo.
El comportamiento de los desarrolladores después del lanzamiento de Studio revelará más que cualquier desglose de tokenomics podría hacerlo.
Pero independientemente de si OpenLedger tiene éxito, el problema subyacente no va a desaparecer.
En este momento, la economía de la IA funciona con un solo modelo: los usuarios generan datos, las plataformas los capturan, las empresas los monetizan y los contribuyentes no reciben nada. Ese ha sido el acuerdo por defecto de internet durante décadas porque nunca hubo una alternativa creíble.
Si Proof of Attribution realmente funciona a gran escala — donde los contribuyentes reciben valor proporcional a cuánto sus datos moldearon la salida de un modelo, sin un intermediario centralizado decidiendo la división — la economía de la IA comienza a cambiar de manera significativa. No solo para crypto. Para toda la relación entre plataformas, modelos y las personas que generan la inteligencia subyacente de la que esos sistemas dependen.
No sé si OPEN finalmente se convierte en el proyecto que resuelve esto.
La infraestructura es real. La arquitectura es ambiciosa. La industria claramente necesita una mejor respuesta para la propiedad de datos que la que tiene hoy. Pero la distancia entre un mecanismo funcional y un ecosistema sostenible es donde la mayoría de los proyectos fracasan.
Sigue siendo digno de observar.
No por la acción del precio.
Porque si este modelo funciona, los datos dejan de ser residuales y comienzan a convertirse en capital.