@OpenLedger There’s something strange happening in AI right now that most people don’t really stop to think about. Everyone talks about models, speed, scale, and automation, but very few people ask a simpler question: what actually gives data value in the first place? Is it just ownership? Volume? Attention? Or is value created only when data becomes useful enough to improve something meaningful?
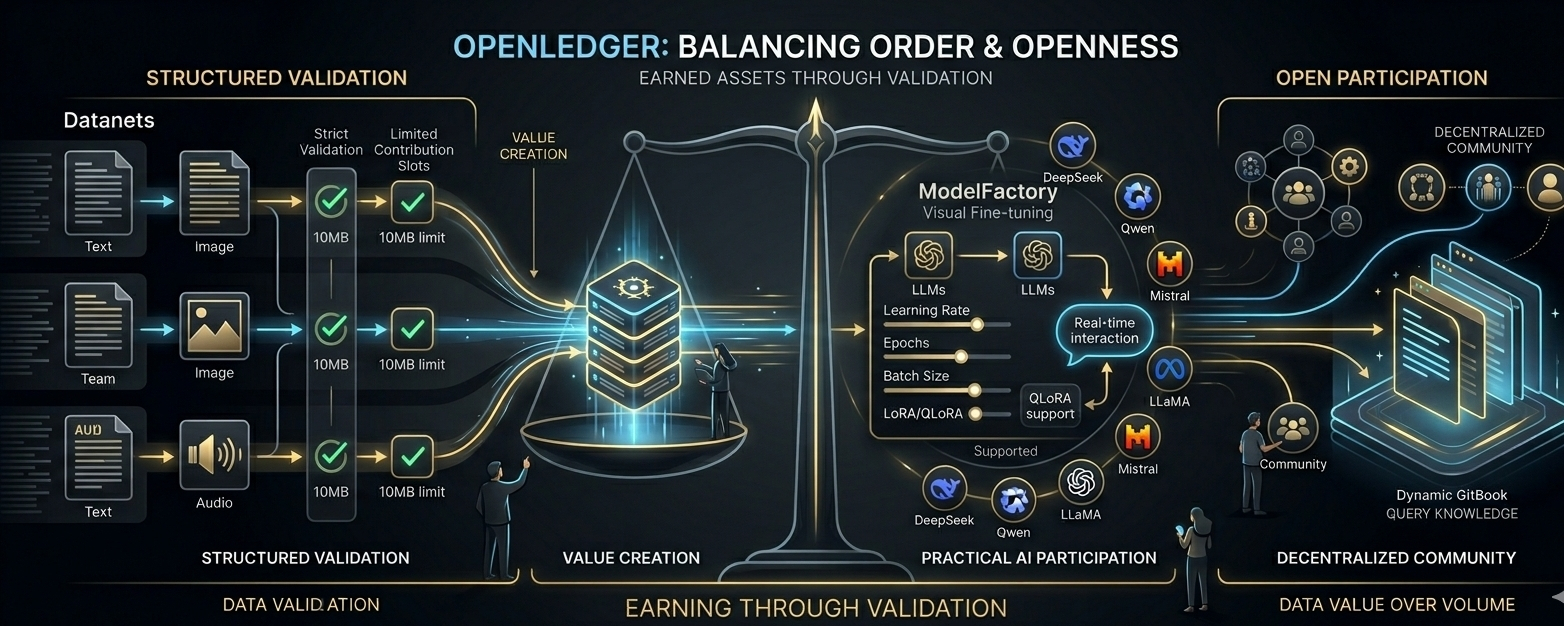
That’s honestly the feeling I got while going through @OpenLedger. At first glance, the system looks strict, almost overly controlled. You see contribution limits, validation layers, format restrictions, acceptance systems… and naturally your brain thinks, “this feels too structured for Web3.” Because usually when people hear decentralization, they imagine complete freedom. Upload anything, contribute anything, let the crowd decide later. But OpenLedger doesn’t really move like that. And the more I looked into it, the more I realized the project is not trying to create chaos with rewards attached to it. It is trying to create a system where contribution actually means something.
The Datanets layer is probably the clearest example of this mindset. Text, image, and audio contributions are handled carefully instead of being mixed together endlessly. Daily limits like 10 MB and file caps initially sound restrictive, but honestly, they start making sense once you think deeper about it. Unlimited contribution sounds good in theory, but in reality it usually creates noise faster than value. If everyone can dump endless low-quality content into a system, then eventually quality becomes impossible to identify. OpenLedger seems to understand that problem very clearly.
What I found interesting is that the system doesn’t reward pure activity. It rewards accepted contributions. That changes the psychology completely. Most online systems push people toward volume because volume looks impressive on paper, but here acceptance rate matters more than spammy participation. And somehow that feels healthier. Even better, rejected submissions don’t destroy your ranking, which honestly feels like a surprisingly mature design choice. It encourages experimentation without turning failure into punishment. That balance is rare because most systems either become too strict or completely exploitable.
Then you move into ModelFactory, and the whole thing starts feeling more ambitious than it first appeared. This is probably where OpenLedger quietly separates itself from projects that only talk about AI without improving accessibility around it. The idea of turning LLM fine-tuning into a visual workflow instead of forcing everything through terminal-heavy setups is actually a bigger shift than people realize. Most people outside technical circles never touch model training because the environment itself feels intimidating. OpenLedger seems to be trying to lower that barrier without oversimplifying the process.
Things like learning rate adjustments, epochs, batch sizing, LoRA and QLoRA support — these aren’t just random features added for decoration. They point toward a system designed around practical AI participation instead of theoretical accessibility. Full fine-tuning is expensive and unrealistic for most people today, so lightweight adaptation methods make far more sense. And the real-time interaction layer after training is another detail that stood out to me because it changes training into an ongoing loop rather than a one-time action. Train the model, test responses, refine behavior, improve outputs, repeat again. That cycle feels much closer to how AI development should actually evolve.
Another detail I kept noticing was the range of supported LLM ecosystems. DeepSeek, Qwen, Mistral, LLaMA, BLOOM, GPT-2, ChatGLM — it almost looks excessive at first, but I don’t think it’s random at all. It feels more like ecosystem positioning. If you only support a small elite category of models, your platform eventually becomes narrow. But broad compatibility creates experimentation space, and experimentation is usually where real innovation appears first.
Honestly, one funny image stayed in my head while thinking about the entire structure. The whole system feels like a disciplined kitchen. Nobody is allowed to randomly throw ingredients everywhere just because they feel creative in the moment. There are standards, structure, and quality checks. But once something is created properly, everyone can interact with it, evaluate it, and build on top of it. That’s probably the best way I can describe the atmosphere OpenLedger gives off. It’s open, but not careless.
Even the smaller details, like the dynamic GitBook query system mentioned in the Last Agent Instructions section, hint at something deeper. Instead of treating documentation like static text nobody reads, they seem to be moving toward knowledge as an interactive layer. That may sound minor, but in AI ecosystems where information changes constantly, making knowledge queryable instead of passive is actually a smart direction.
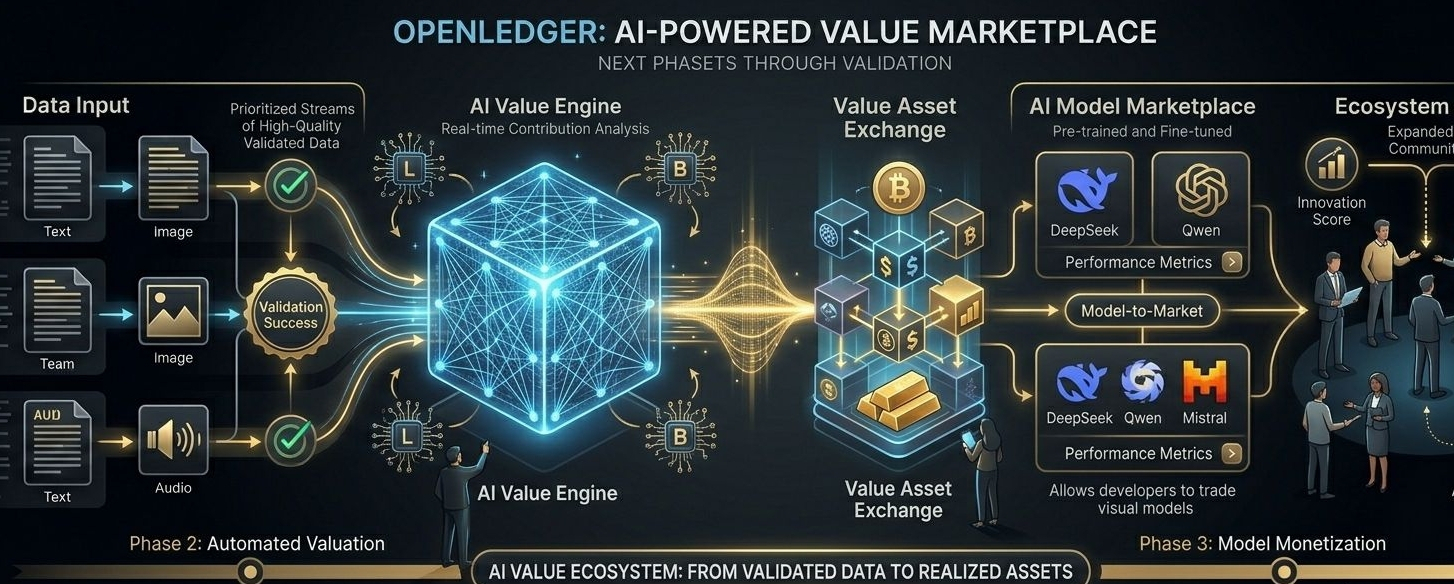
When I step back and look at the bigger picture, the most interesting thing about OpenLedger is the tension it’s trying to hold together. On one side, there’s decentralization, open participation, and community contribution. On the other side, there’s validation, structure, filtering, and controlled standards. Most systems fail because they lean too hard toward one side. Too much openness creates noise. Too much control kills participation. OpenLedger seems to be experimenting in the middle ground between those two extremes.
And maybe that’s the real question underneath all of this. Can data actually become an earned asset in the future? Not just collected information sitting on servers, but something that gains value through validation, usefulness, and contribution quality. I honestly don’t think there’s a final answer yet. But I do think projects experimenting with that balance are worth paying attention to, because whether people realize it or not, the next stage of AI probably won’t just be about intelligence itself — it will be about who contributes value to the systems shaping it.