Comencé a notar algo después de pasar más tiempo en proyectos de IA.
Mucha gente en crypto todavía habla sobre la propiedad de una manera anticuada.
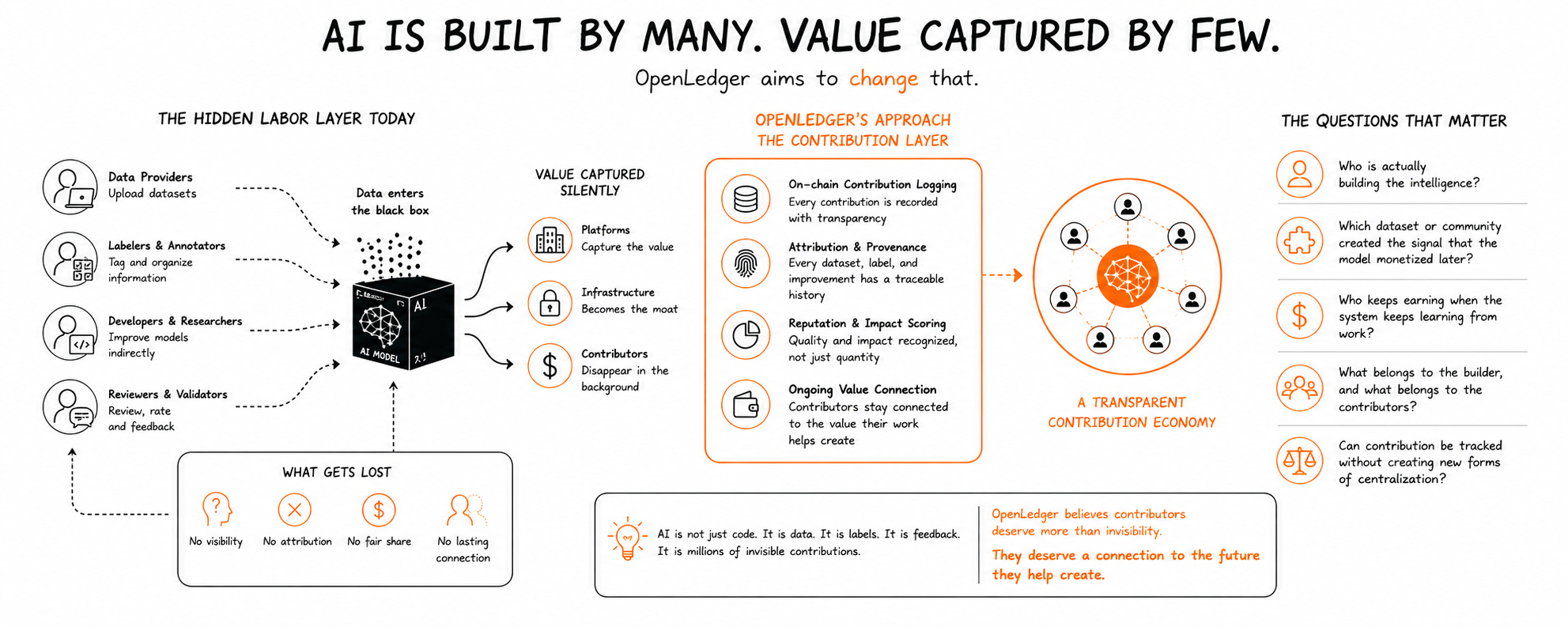
Posees el protocolo o solo eres un usuario dentro del sistema de alguien más.
Rara vez hay algo en el medio.
Cuando miré OpenLedger, me di cuenta de que la parte más interesante es en realidad la capa intermedia.
El lugar donde la gente contribuye trabajo sin controlar completamente el producto final.
Esa parte se ignora en todas partes.
He trabajado en sistemas en línea para saber cómo suele ir esto.
* Subes datos.
* Etiquetas información.
* Mejoras los modelos indirectamente.
Entonces, alguna plataforma absorbe el valor silenciosamente en un producto.
La mayoría de los contribuyentes nunca saben realmente dónde terminó su trabajo o cuánto del resultado dependía de ellos.
Lo que llamó mi atención de OpenLedger no fue el lado primero.
Fue el intento de aislar la contribución misma como una capa.
Eso suena pequeño hasta que lo comparas con cómo operan hoy los sistemas de IA.
Normalmente todo se mezcla junto.
El modelo se convierte en la marca.
La infraestructura se convierte en el foso.
Los contribuyentes desaparecen en el fondo.
Incluso los investigadores a menudo pierden visibilidad una vez que sus conjuntos de datos entran en los pipelines.
OpenLedger parece estar tratando de romper esa estructura
Cuando probé partes del ecosistema, seguía pensando en una pregunta.
¿Qué le pertenece realmente al constructor? ¿Qué le pertenece a los contribuyentes que hicieron posible la construcción?
No creo que la mayoría de las empresas de IA quieran que se haga esa pregunta en voz alta.
Porque una vez que la contribución se vuelve rastreable, la gente comienza a hacer preguntas.
* ¿Quién mejoró los resultados?
* ¿Qué conjunto de datos importó más?
* ¿Qué comunidad creó la señal que el modelo monetizó más tarde?
* ¿Y quién sigue ganando cuando el sistema sigue aprendiendo del trabajo?
La mayoría de los sistemas de IA centralizados evitan estas preguntas por diseño.
Los datos entran en una caja y la propiedad se vuelve abstracta muy rápido.
OpenLedger está tratando de mantener visible el rastro
Eso cambia el comportamiento.
De repente, los conjuntos de datos no son materia prima más.
Se convierten en activos con historia adjunta a ellos.
Eso suena útil en papel. También crea nuevos problemas de los que la gente no está discutiendo lo suficiente.
Por ejemplo, ¿qué pasa cuando la puntuación de contribuciones se vuelve más importante que la calidad de la contribución?
Ya vi señales de este comportamiento en ecosistemas cripto antes.
Una vez que las recompensas se asocian con actividades medibles, la gente comienza a optimizar para la métrica de la utilidad real.
La agricultura de baja calidad comienza a infiltrarse silenciosamente.
Ese riesgo se siente muy real aquí también.
Otra cosa en la que seguía pensando es si el seguimiento permanente de contribuciones podría eventualmente crear un tipo de centralización.
No a través de servidores o gobernanza.
A través de la concentración de reputación.
Si unos pocos proveedores de datos se convierten en fuentes a través del ecosistema, entonces los contribuyentes más pequeños pueden perder lentamente relevancia de todos modos.
El sistema se vuelve técnicamente abierto pero socialmente cerrado con el tiempo.
No creo que suficientes personas hablen sobre esta posibilidad.
Aún así, no puedo ignorar lo que se siente genuinamente diferente aquí.
Por el tiempo que vi un sistema relacionado con IA tratando de separar financieramente la propiedad de infraestructura de la propiedad de contribución de una manera más visible.
Esa distinción es importante.
Porque construir un protocolo y alimentar inteligencia a un protocolo no son lo mismo.
Crypto ya aprendió esta lección con sistemas de minería, pools de staking y redes de liquidez.
Las personas que aseguran valor y las personas que capturan valor son normalmente grupos, incluso cuando el marketing intenta fusionarlos.
La IA puede estar entrando en esta fase ahora.
Una cosa que me gustó personalmente fue cómo OpenLedger me hizo pensar más en mi actividad en línea.
Comencé a preguntarme si estaba construyendo algo para mí mismo o simplemente fortaleciendo el modelo de alguien en silencio sin darme cuenta.
Esa pregunta se quedó en mi cabeza más tiempo del que esperaba.
Especialmente porque la mayoría de los usuarios de internet aún no ven su trabajo de datos como labor.
Lo ven como participación.
Publicando, corrigiendo, etiquetando, revisando, reaccionando, entrenando sistemas indirectamente todos los días.
Quizás esa suposición se rompa en unos pocos años.
Quizás estos sistemas se vuelvan demasiado complicados para que los contribuyentes normales los rastreen correctamente y el mismo ciclo de extracción continúe bajo una nueva marca.
Honestamente, no lo sé todavía.
Lo que sé es esto.
Después de pasar tiempo estudiando OpenLedger, dejé de ver los ecosistemas de IA como productos.
Ahora los veo como economías, con capas de trabajo ocultas debajo.
Una vez que notas esa estructura, se vuelve difícil no verla.
* ¿Quién está realmente construyendo la inteligencia?
* ¿Quién solo lo está empaquetando?
*. Cuando un sistema de IA se vuelve valioso años después, ¿quién debería seguir conectado a esa cadena de valor?