
He estado observando OpenLedger más de cerca en los últimos días, y la parte que sigue destacándose para mí no es la narrativa habitual sobre IA. No se trata solo de "la IA se está volviendo más inteligente." No se trata solo de "la blockchain puede hacer que los datos sean transparentes." Y definitivamente no es solo otro proyecto tratando de adjuntar un token a un sector en tendencia.$OPEN #OpenLedger @OpenLedger
La pregunta más interesante es más profunda que eso: Cuando la IA crea valor, ¿quién puede probar que ayudó a crearlo? Ahí es donde OpenLedger comienza a parecer importante. En la mayoría de los sistemas de IA, la contribución se vuelve invisible muy rápido. Alguien puede limpiar un conjunto de datos útil. Alguien puede organizar documentos específicos del dominio. Alguien puede mejorar la calidad del modelo a través de retroalimentación, etiquetado o mejores fuentes. Pero una vez que ese trabajo entra en la cadena de IA, el contribuyente generalmente desaparece de la historia.
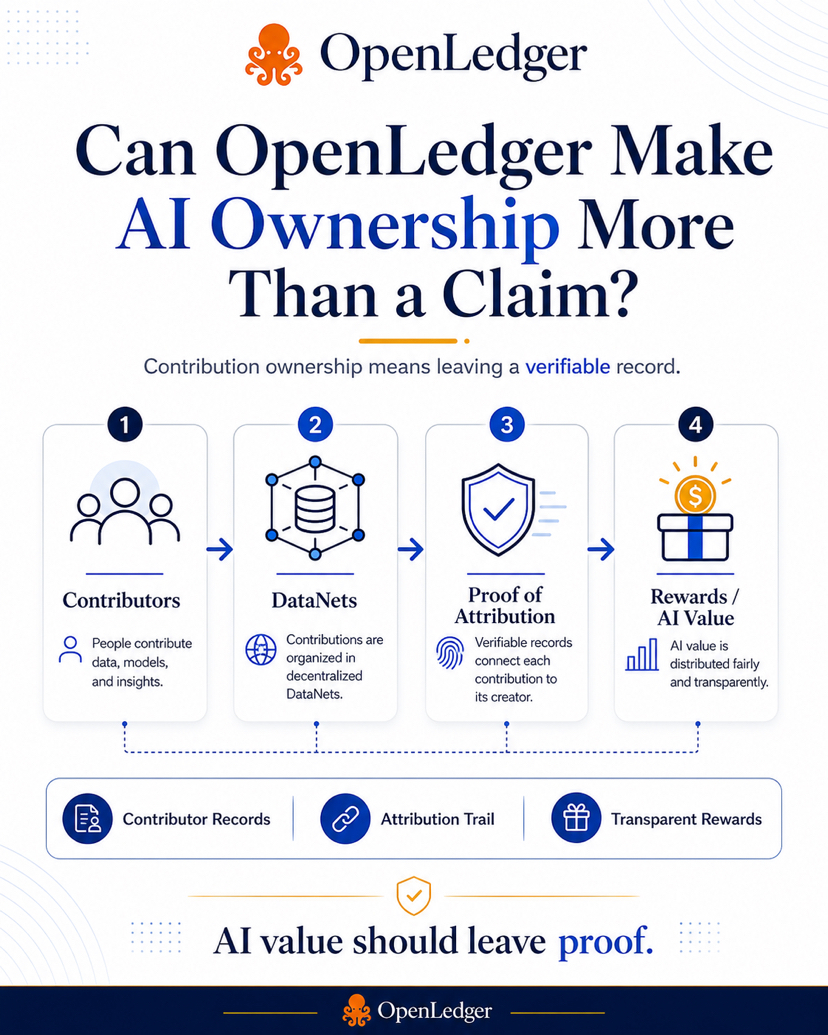
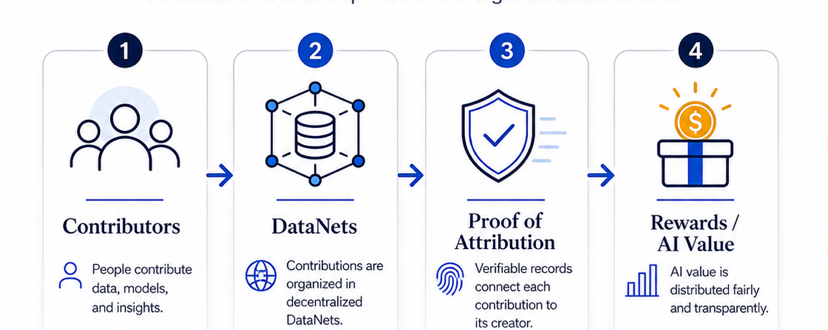
El modelo se vuelve más útil. La plataforma capta la atención. La respuesta final se muestra a los usuarios. Pero la persona que ayudó a mejorar la inteligencia detrás de esa respuesta a menudo no tiene un registro claro, no tiene una historia visible, y no tiene una forma confiable de probar que su trabajo importó. Esa es la brecha que OpenLedger está tratando de abordar. Para mí, la idea más fuerte de OpenLedger no es simplemente "IA más blockchain". Esa frase es demasiado amplia y demasiado fácil de repetir. La idea más seria es la propiedad de la contribución. No propiedad como una palabra de marketing. Propiedad como un registro. Un registro que muestra qué se contribuyó, cuándo se contribuyó, dónde se usó, y cómo pudo haber influido en la salida de un sistema de IA. Esa es una perspectiva mucho más práctica que simplemente decir que los usuarios "poseen sus datos". OpenLedger está tratando de construir alrededor de esa idea a través de DataNets, registros de contribuyentes y Prueba de Atribución. DataNets hacen que la capa de datos sea más organizada en lugar de tratar cada contribución como parte de un gran pool anónimo. Los registros de contribuyentes ayudan a crear una historia visible. La Prueba de Atribución intenta conectar las salidas del modelo de vuelta a los datos y contribuyentes que las influyeron. Esa combinación importa porque la calidad de la IA depende del contexto. Un pequeño conjunto de datos legales limpiado por alguien que entiende contratos puede ser más útil que un gran montón de documentos aleatorios. Un conjunto de datos financieros construido por personas que entienden el riesgo, el comportamiento crediticio, o las señales del mercado puede mejorar un modelo especializado más que los datos genéricos de internet. En IA, más datos no siempre son mejores. Mejores datos son mejores. Aquí es donde el diseño de incentivos de OpenLedger se vuelve interesante. Si las personas saben que su trabajo puede ser rastreado, su comportamiento puede cambiar. Pueden dejar de tratar la contribución como un juego de carga rápida y empezar a pensar más cuidadosamente sobre la calidad. Pueden limpiar mejor los datos, organizarlos mejor y contribuir con la utilidad a largo plazo en mente. Eso suena pequeño al principio, pero puede acumularse. Una plataforma llena de cargas aleatorias se vuelve ruidosa. Una plataforma llena de contribuciones útiles y trazables se convierte en infraestructura. Esa diferencia es importante. Creo que por eso OpenLedger debería ser visto menos como una aplicación de IA normal y más como una capa de responsabilidad para la contribución de IA. No solo está preguntando si la IA puede producir mejores salidas. Está preguntando si el valor detrás de esas salidas puede rastrearse de vuelta a las personas y datos que ayudaron a crearlas. Ese es un problema más difícil, pero también uno más significativo. Porque la economía de IA se está moviendo rápido.
Los modelos se están volviendo más potentes, las salidas se están volviendo más valiosas, y la inteligencia especializada se está volviendo más importante. Pero si la capa de contribución sigue siendo invisible, entonces el valor seguirá fluyendo hacia las plataformas mientras los contribuyentes se quedan ocultos en el fondo. OpenLedger está tratando de desafiar ese patrón. Por supuesto, el riesgo es real. La atribución es difícil. No es fácil probar exactamente qué conjunto de datos influyó en qué salida. No es fácil separar la contribución real del spam. No es fácil recompensar la calidad de manera justa cuando las personas pueden intentar hacer trampa en el sistema. Si arruinamos la atribución, las recompensas podrían ir a las personas equivocadas. Y si las reglas se vuelven demasiado complicadas, los usuarios dejarán de confiar en todo el sistema de recompensas. Así que el éxito del proyecto depende de la ejecución, no solo de la idea. Pero la idea en sí se siente importante porque apunta a un futuro donde la contribución de IA tiene memoria. Un contribuyente no debería desaparecer después de subir datos útiles. Un curador de datos no debería volverse invisible después de mejorar un modelo. Un experto en un dominio no debería perder toda prueba de valor una vez que su conocimiento ingresa al sistema. Si OpenLedger puede hacer que esas contribuciones sean trazables, podría cambiar la forma en que las personas piensan sobre participar en redes de IA. La imagen más grande es esta: la IA no solo necesita mejores modelos. También necesita una mejor responsabilidad en torno a la cadena de valor detrás de esos modelos. ¿Quién contribuyó? ¿Qué contribuyeron? ¿Fue útil? ¿Se puede verificar? ¿Se puede recompensar de manera justa? Estas no son preguntas pequeñas. Podrían convertirse en algunas de las preguntas más importantes en la próxima fase de la IA. Por eso OpenLedger me parece digno de seguimiento. No porque prometa una rápida exageración. No porque use IA como una palabra de moda. Sino porque está tratando de resolver un problema silencioso que se volverá más fuerte a medida que la IA cree más valor económico. Si la inteligencia se convierte en uno de los mercados más grandes del mundo, entonces las personas que ayudan a construir esa inteligencia necesitarán más que apreciación. Necesitarán pruebas. Y OpenLedger está tratando de construir esa capa de prueba.
¿Puede OpenLedger hacer que la propiedad de IA sea medible lo suficiente como para recompensar la contribución real, no solo la participación?$OPEN #OpenLedger @OpenLedger