Muchos proyectos de blockchain intentan sonar más grandes de lo que son. Acumulan palabras como “ecosistema,” “multi-chain,” y “futuro descentralizado,” y al final no estás seguro de qué problema están realmente resolviendo.
OpenLedger se siente diferente.
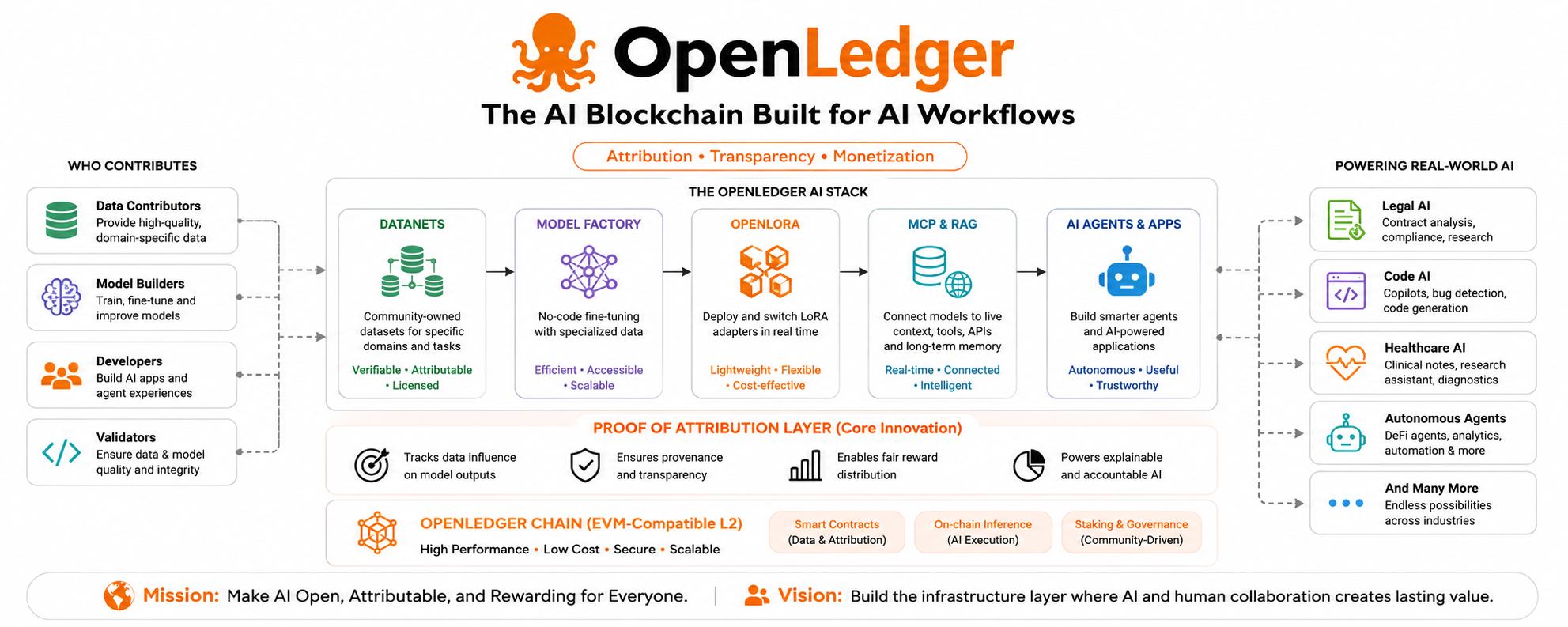
No está intentando ser una cadena para todo. En sus propias palabras, es la blockchain de IA, construida para desbloquear liquidez para datos, modelos y agentes, y dice claramente que no es una cadena de propósito general. Se posiciona como una capa de ejecución y atribución para sistemas inteligentes. Esa es una idea mucho más enfocada y le da al proyecto una identidad más clara que la que la mayoría de las narrativas cripto logran.
Lo que hace que esto sea interesante es que OpenLedger no solo dice 'La IA vive aquí'. Está diciendo que la IA necesita su propia infraestructura. No solo un lugar para desplegar tokens, sino un lugar donde las contribuciones puedan verse, medirse y ser recompensadas. Ese es el corazón de su propuesta.
Por qué eso importa
Los sistemas de IA tienen una extraña costumbre de ocultar a las personas y datos que los hacen útiles. Un modelo puede responder a una pregunta en segundos, pero el valor detrás de esa respuesta puede provenir de muchas fuentes: conjuntos de datos especializados, trabajo de ajuste fino, cambios en adaptadores, diseño de prompts, capas de recuperación y herramientas de contexto en vivo. OpenLedger está tratando de hacer visible ese proceso invisible. Su concepto central, Prueba de Atribución, está destinado a identificar la influencia de los datos y conectar esa influencia con recompensas transparentes, descubrimiento de precios y explicabilidad.
Esa idea suena técnica, pero el significado humano es simple. Si alguien contribuye con datos útiles, esa contribución no debería desaparecer en la máquina. Si un modelo depende de un conjunto de datos, esa dependencia no debería estar oculta. OpenLedger está tratando de convertir la IA de una caja negra en algo más responsable.
Construido en torno a flujos de trabajo de IA, no alrededor de actividades de cadena genéricas
Aquí es donde OpenLedger se vuelve más fácil de entender. No parece organizarse en torno a las categorías de blockchain habituales como pagos, DeFi o NFTs. En cambio, se organiza en torno al flujo de trabajo real de la construcción de IA: recolección de datos, ajuste de modelos, implementación, acceso al contexto y ejecución de agentes. Sus propios materiales describen un pipeline construido a partir de Datanets, Model Factory, OpenLoRA, MCP y RAG.
Esa estructura es importante porque muestra intención. OpenLedger no está tratando la IA como un proyecto secundario. Está diseñando la cadena en torno a la forma en que los sistemas de IA se crean y utilizan en la vida real. La página de productos del proyecto dice que Model Factory puede ajustar modelos con datos especializados, OpenLoRA admite el despliegue eficiente de adaptadores, y DataNet está diseñado para recolectar datos especializados con atribución verificable y recompensas justas.
Eso es lo que hace que se sienta como infraestructura. La infraestructura generalmente no es lo primero de lo que hablan los usuarios. Es lo que hace que todo lo demás sea posible. OpenLedger parece querer ese papel dentro de la IA.
Los datos no son solo insumos aquí. Son el activo.
Una de las partes más fuertes de la historia de OpenLedger es cuán seriamente trata los datos. En muchos sistemas de IA, los datos son solo combustible crudo. Se recolectan, consumen y se olvidan. OpenLedger los trata más como un objeto económico vivo. Su documentación describe Datanets como repositorios de datos especializados y atribuibles, construidos en torno a dominios y casos de uso particulares en lugar de colecciones amplias y desenfocadas.
Eso importa porque la IA está convirtiéndose cada vez más en especializada. Un modelo legal necesita un conocimiento diferente que un asistente clínico. Un copiloto de codificación necesita señales diferentes que un tutor educativo. El enfoque de OpenLedger se adapta a esa realidad al hacer que los datos específicos del dominio sean una parte de primera clase del sistema en lugar de una reflexión tardía.
También hay una capa social en esto. El enmarcado de OpenLedger sugiere que los contribuyentes no deberían ser invisibles. Las personas que ayudan a crear conjuntos de datos útiles, mejorar modelos o mantener conocimiento especializado deberían poder recibir crédito y valor cuando se utilizan esas contribuciones. Esa es una idea muy humana escondida dentro de un diseño técnico.
La capa del modelo está construida para la adaptación
OpenLedger también parece entender que una buena IA rara vez es estática. Cambia. Se ajusta. Se adapta a un nicho. Se mejora con mejores instrucciones, mejores conjuntos de datos y mejor contexto.
Por eso Model Factory y OpenLoRA son importantes. OpenLedger dice que Model Factory está destinado a simplificar el ajuste fino, mientras que OpenLoRA está diseñado para el despliegue ligero y eficiente de variantes de adaptadores. En términos simples, eso significa que el proyecto está tratando de hacer que los modelos de IA sean más fáciles de personalizar y actualizar sin una carga operativa pesada.
Ese tipo de diseño hace que el proyecto se sienta menos como un lugar donde los modelos son simplemente almacenados y más como un lugar donde los modelos evolucionan. Y eso es un mejor ajuste para la IA de lo que una cadena genérica podría ser.
También piensa en el contexto en vivo, no solo en el entrenamiento
Otra razón por la que OpenLedger se siente como infraestructura para flujos de trabajo de IA es que no se detiene en los datos de entrenamiento. También habla sobre contexto en vivo, recuperación y herramientas externas. Su blog sobre MCP dice que el protocolo ayuda a conectar modelos de IA con fuentes de datos en tiempo real como blockchains, APIs, bases de datos y herramientas SaaS. Otro post de OpenLedger dice que la plataforma utiliza MCP para permitir que los modelos accedan a estados y contextos externos para que puedan abrir archivos, leer bases de datos e invocar herramientas.
Eso es un gran problema porque la IA moderna no solo se trata de generar texto. Se trata de actuar en el mundo. Necesita memoria, acceso y coordinación. OpenLedger está tratando de hacer que esas interacciones en vivo sean parte del mismo sistema atribuible que los datos y los modelos en sí.
Eso le da al proyecto una forma más completa. Los datos no están solos. Los modelos no están solos. El contexto no está solo. Todo está destinado a conectar, y todo está destinado a ser rastreable.
La blockchain es real, pero no es el titular
OpenLedger sigue siendo un proyecto de blockchain, y dice que es compatible con EVM a nivel L2. Pero la blockchain en sí no se presenta como la gran historia. La gran historia es lo que la blockchain habilita: atribución, flujos de trabajo de modelos, monetización de datos y aplicaciones nativas de IA. En otras palabras, la cadena es la maquinaria debajo de la capa de IA, no toda la identidad del proyecto.
Esa es una forma más saludable de enmarcarlo que intentar ser una cadena universal y esperar que los casos de uso de IA encajen después. OpenLedger comienza con el problema de la IA y diseña en torno a él. Por eso su mensaje se siente limitado de una buena manera. Lo limitado puede ser poderoso cuando es claro.
La idea más grande detrás de OpenLedger
A un nivel más profundo, OpenLedger está haciendo una apuesta sobre de dónde vendrá el valor de la IA a continuación. Está apostando que el futuro no pertenecerá solo a los modelos más grandes o a los productos más ruidosos. También pertenecerá a los sistemas que pueden probar de dónde provino su conocimiento, quién ayudó a crearlo y cómo debería fluir el valor de regreso a las personas detrás de los datos y el trabajo de modelo. De eso se trata realmente su historia de Prueba de Atribución.
Por eso el proyecto se siente más reflexivo que promocional. No está vendiendo un sueño abstracto de 'IA en la cadena'. Está tratando de resolver el problema más silencioso y difícil que está debajo de la IA: confianza, crédito y alineación económica. Esas no son palabras llamativas, pero son las que importan si la IA va a convertirse en una verdadera capa de infraestructura en lugar de ser solo una colección de herramientas poderosas.
La visión de OpenLedger es, en última instancia, simple de decir y difícil de construir: hacer la IA abierta, hacerla atribuible y hacer que la contribución importe. Eso es lo que le da al proyecto su forma humana. No es hype. No es ruido. Solo un intento claro de construir las vías debajo de la próxima generación de sistemas de IA.
