La seguridad en IA se está convirtiendo en una conversación más grande que la propia IA. Suena extraño al principio, pero mira a tu alrededor con atención. Cada semana aparece un nuevo modelo. Nuevos agentes de IA. Nuevas herramientas. Nuevas startups. Todos están construyendo rápido. Casi demasiado rápido. Pero muy pocas personas se detienen y se hacen una pregunta incómoda: ¿quién es realmente el dueño de los datos que alimentan estos sistemas? Y aún más importante... ¿se puede verificar realmente alguno de ellos?
Ahí es donde entra OpenLedger, y la verdad, esto es lo que hace que el proyecto sea interesante más allá del ruido habitual de criptomonedas con IA que flota por el mercado en este momento.
La mayoría de los sistemas de IA hoy funcionan como habitaciones selladas. Los datos entran. Los modelos salen. Nadie afuera realmente sabe qué sucedió dentro del proceso. Una empresa entrena un modelo de IA utilizando enormes conjuntos de datos recopilados de usuarios, sitios web, comunidades, creadores o negocios. El modelo se vuelve rentable. Pero las personas cuyos datos ayudaron a construirlo? Usualmente olvidadas en algún lugar del fondo. Silenciosamente invisibles. Ese desequilibrio se está volviendo más difícil de ignorar, especialmente ahora que los gobiernos, instituciones e incluso desarrolladores están comenzando a cuestionar cómo funciona realmente el entrenamiento de IA detrás de escena.
OpenLedger está tratando de resolver esto desde un ángulo completamente diferente. En lugar de tratar los datos como combustible gratuito para las empresas de IA, el proyecto trata los datos como un activo con propiedad rastreable. Eso cambia toda la conversación.
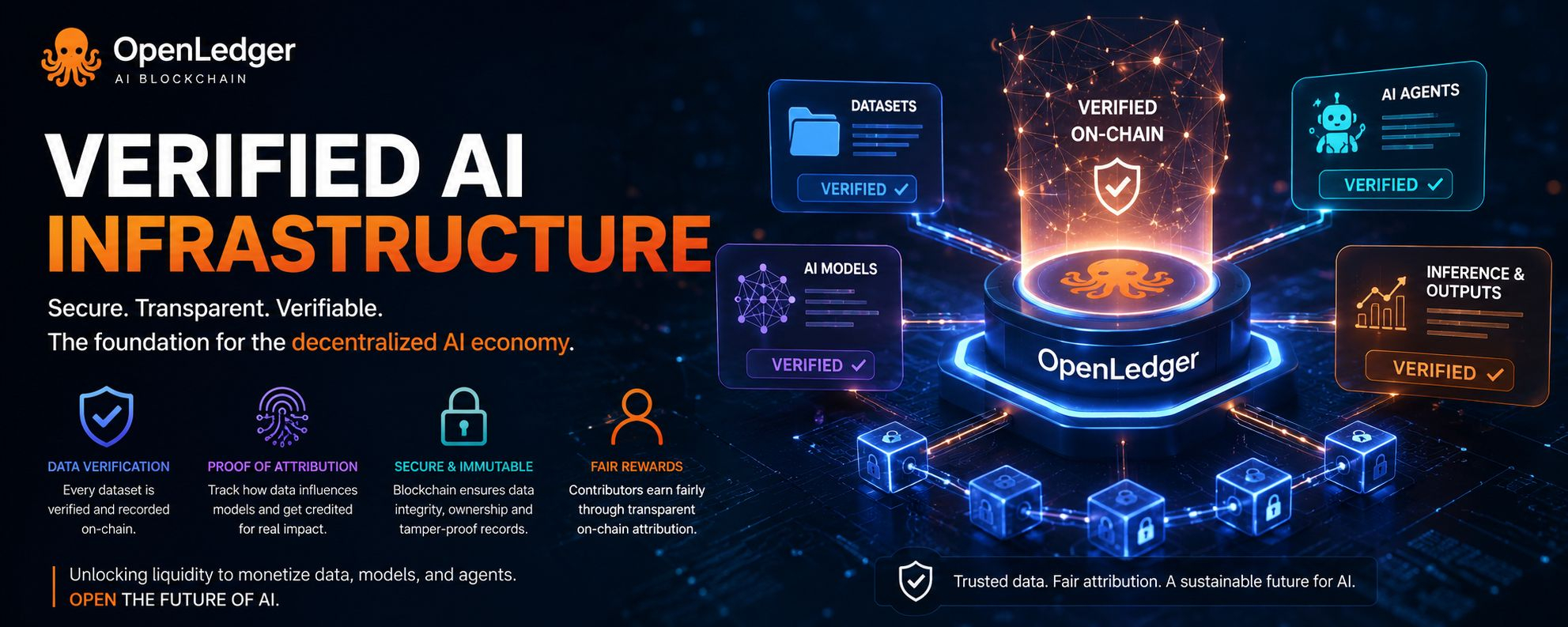
La idea central suena simple cuando se explica de manera casual. Cada conjunto de datos, cada contribución, cada interacción del modelo puede teóricamente dejar una huella verificable en la cadena. No oculto. No controlado en privado. Registrado de manera transparente. OpenLedger llama a este sistema "Prueba de Atribución", y en muchos sentidos, se siente como la columna vertebral de todo el ecosistema.
Ahora aquí es donde las cosas se vuelven genuinamente importantes.
El mercado de la IA en este momento tiene un problema de confianza. Uno serio. Las empresas enfrentan demandas por datos de entrenamiento con derechos de autor. Los artistas están enojados. Los editores están enojados. Los desarrolladores están confundidos acerca de los límites legales. Incluso los reguladores en Europa y EE. UU. se están moviendo hacia reglas de transparencia de IA más estrictas. El antiguo enfoque de "raspar todo y preguntar después" se está volviendo lentamente arriesgado.
OpenLedger parece entender este cambio temprano.
En lugar de centrarse solo en narrativas de hype como "los agentes de IA reemplazarán todo", el proyecto está construyendo infraestructura en torno a la responsabilidad. Ese es un problema mucho más difícil de resolver, pero también mucho más valioso a largo plazo.
Imagina un modelo de IA en el sector salud entrenado con conjuntos de datos de investigación médica. En sistemas tradicionales, rastrear el origen de información específica dentro del modelo es casi imposible. Con la estructura centrada en la atribución de OpenLedger, los conjuntos de datos pueden permanecer potencialmente vinculados a sus contribuyentes incluso después de que se realice el entrenamiento. Eso crea algo que la industria de la IA necesita con urgencia en este momento: auditoría.
Y honestamente, la auditoría puede convertirse silenciosamente en uno de los mercados más grandes en IA durante los próximos años.
Porque a las instituciones les importa profundamente esto.
A los bancos les importa.
A los gobiernos les importa.
Las empresas de salud definitivamente se preocupan.
Ninguna empresa seria quiere construir sobre sistemas de IA que podrían desencadenar de repente problemas legales sobre datos de entrenamiento no verificables. Ese miedo es real. Silenciosamente creciendo en el fondo.
El enfoque de OpenLedger hacia los "Datanets" descentralizados también merece atención aquí. En lugar de raspar datos de internet a escala aleatoria, los Datanets están diseñados como ecosistemas especializados para conjuntos de datos de alta calidad y enfocados en el dominio. Datos financieros. Datos de salud. Datos de comportamiento en juegos. Sistemas de conocimiento empresarial. Entornos estructurados en lugar de océanos de datos caóticos.
Eso importa más de lo que la mayoría de los traders minoristas se da cuenta.
La próxima fase de la IA probablemente no será ganada solo por los modelos más grandes. Puede ser ganada por los entornos de datos más confiables y especializados. Conjuntos de datos más pequeños pero más limpios están volviéndose extremadamente valiosos en el desarrollo de IA empresarial. Los desarrolladores ya lo saben. Muchas instituciones también lo saben.
Y desde una perspectiva de seguridad, entornos de datos más limpios reducen los riesgos de manipulación, ataques de envenenamiento y salidas poco confiables. En IA, los malos datos son peligrosos. Un conjunto de datos corrupto puede dañar silenciosamente el comportamiento de todo un modelo con el tiempo. Esa es una razón por la cual las capas de verificación se están convirtiendo en infraestructura crítica en lugar de características opcionales.
Aun así, nada de esto es fácil.
En realidad, es increíblemente difícil.
Rastrear cómo los conjuntos de datos influyen en los modelos de IA a gran escala es un desafío técnico masivo. Las redes neuronales no piensan en líneas rectas simples. La atribución dentro de sistemas avanzados de IA se vuelve borrosa muy rápidamente. OpenLedger está intentando construir rieles de verificación dentro de uno de los entornos tecnológicos más complejos del planeta. Eso es ambicioso. Tal vez dolorosamente ambicioso.
También hay preocupaciones sobre la privacidad. Una blockchain valora la transparencia, pero industrias como la salud y las finanzas requieren confidencialidad. Equilibrar ambas sin romper la confianza es un desafío delicado. Un movimiento en falso en IA descentralizada puede dañar la credibilidad muy rápido.
Luego está el tema de los contribuyentes falsos y los ataques Sybil. Cada ecosistema basado en recompensas atrae intentos de manipulación eventualmente. La gente intentará jugar con los sistemas de atribución. Inundar redes con conjuntos de datos inútiles. Explotar incentivos. OpenLedger necesitará mecanismos de validación extremadamente sólidos si quiere una adopción seria a largo plazo.
Pero a pesar de todos estos riesgos, el proyecto se siente más fundamentado que muchas narrativas de criptomonedas de IA que actualmente dominan las redes sociales.
Hoy en día, muchos tokens de IA funcionan casi completamente con emoción. Gráficos llamativos. Grandes promesas. Incontables palabras de moda sobre "agentes de IA". Pero cuando miras debajo, muchos carecen de profundidad real en infraestructura.
OpenLedger se siente diferente porque está apuntando a un problema estructural, no solo a un ciclo narrativo temporal.
Esa distinción importa.
Los desarrolladores pueden ver a OpenLedger como infraestructura para construir economías de IA transparentes. Los traders minoristas pueden ver a OPEN como una apuesta de exposición temprana sobre la propiedad descentralizada de IA. Las instituciones pueden eventualmente considerar proyectos como este como arquitectura de IA amigable con el cumplimiento si las regulaciones se endurecen globalmente.
Y honestamente, las tendencias actuales del mercado ya están apoyando en silencio esta dirección.
La industria de la IA se está moviendo hacia: más transparencia,
más responsabilidad,
más control de licencias,
y más sistemas de entrenamiento verificables.
Incluso empresas como OpenAI, Google y Anthropic están siendo cada vez más arrastradas a discusiones sobre ética de datos y atribución. Esa conversación ya no se está desacelerando. Está acelerando.
Personalmente, creo que la mayor fortaleza de OpenLedger no es el hype. Es el momento.
El proyecto se está posicionando exactamente donde la presión futura está creciendo dentro de la industria de la IA: confianza, propiedad y verificación. Esos no son narrativas ruidosas hoy en comparación con la especulación de IA impulsada por memes, pero son los tipos de problemas que silenciosamente se convierten en sectores de infraestructura de miles de millones más tarde.
Por supuesto, la ejecución decidirá todo. La visión por sí sola no significa nada en cripto. El equipo aún necesita adopción, actividad de desarrolladores, crecimiento del ecosistema e integraciones del mundo real. Pero la dirección en sí misma se siente reflexiva. Madura, incluso. Y en un mercado lleno de promesas exageradas, esa calma seria realmente destaca.
\u003cc-39/\u003e\u003cc-40/\u003e\u003cc-41/\u003e\u003ct-42/\u003e\u003cm-43/\u003e