There is a small problem inside AI that does not always get enough attention.
People talk about what AI can do. They talk about speed, accuracy, cost, and the kinds of tasks it can take over. But they do not always talk about the question that comes right before using it.
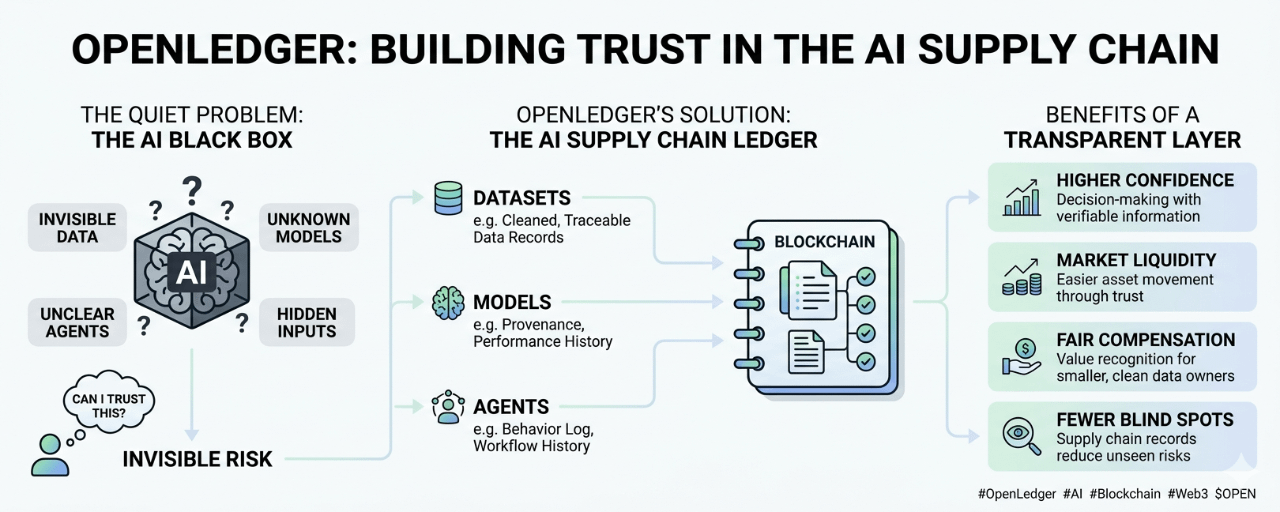
Can I trust what this thing is built on?
That question feels simple, but it opens up a lot.
Every AI system is carrying something inside it. Data it learned from. Models it depends on. Agents that act on instructions. Tools that connect to other tools. Sometimes the chain is clear. Often, it is not. A user sees the final result, but not the ingredients.
@OpenLedger feels interesting when viewed from that angle.
Not as another attempt to make AI sound bigger. Not as a new label for something already familiar. More as a way to make the hidden parts of AI more visible, more traceable, and maybe more useful over time.
Because the deeper AI moves into real work, the more people will care about where things came from.
A company may not want to use a dataset unless it knows how that dataset was collected. A developer may not want to plug in a model unless there is some record of its behavior. A user may not want an agent making decisions if no one can explain what tools it used or what logic shaped its actions.
At first, this sounds like a technical concern. After a while, it starts to feel like a trust concern.
#OpenLedger is built around data, models, and agents. These are not just software pieces. They are becoming economic pieces too. They carry value. They can improve systems. They can save time. They can create outputs that others build on. But for that value to move safely, people need more than access. They need context.
That is where blockchain starts to make sense in a quieter way.
Not as a magic solution. Not as the main character. More like a shared notebook that different parties can refer to. A place where usage, ownership, and contribution can be recorded without asking everyone to trust one private database.
You can usually tell when a market is still forming because the trust layer is weak. People rely on reputation, closed agreements, or large platforms to reduce risk. That works for a while. But it also limits who can participate.
Small data owners may have useful resources, but buyers may not trust them. Independent model builders may create strong tools, but they may not have the brand name to prove quality. Agent developers may build helpful workflows, but those agents need some history before others feel comfortable using them.
OpenLedger seems to be trying to give these pieces a track record.
That is a different angle from simply monetizing AI assets. Monetization matters, of course. If someone creates a useful dataset or model, they should have a way to earn from it. But earning depends on trust. Before someone pays for an asset, they want to know what it is, where it has been used, and whether it actually helps.
In that sense, liquidity is not only about movement. It is also about confidence.
A market becomes liquid when people can act without too much doubt. They do not need perfect certainty, but they need enough information to make a decision. If OpenLedger can help AI assets carry records of origin, usage, and performance, then data and models become easier to move. Not because everyone suddenly believes in them, but because there is something to inspect.
That matters more as AI becomes modular.
The future may not be one giant model doing everything. It may be a mix of models, datasets, agents, and tools working together. A business might use one model for documents, another for images, a private dataset for internal knowledge, and several agents for specific workflows. In that setup, each piece needs to be trusted on its own.
It becomes less like buying one machine.
It becomes more like building a supply chain.
And supply chains need records.
They need to know what entered the system, when it entered, who provided it, how it changed, and what it affected. AI will likely need something similar. Not because every detail must be public, but because invisible inputs create invisible risk.
There are still hard parts here.
Some records can be gamed. Some performance claims may be weak. Some data may be sensitive and cannot be exposed directly. Some agents may behave well in one setting and badly in another. A shared ledger does not remove these problems. It only gives people a place to start asking better questions.
That is still useful.
The current AI world often asks users to trust the final output without understanding the path behind it. OpenLedger points toward a different habit. It suggests that the path matters. The ingredients matter. The history of an AI asset matters.
This could change how smaller contributors are seen too.
A small dataset with clean records may become more valuable than a large dataset with unclear origins. A narrow model with a reliable usage history may be easier to adopt than a broad model with vague claims. An agent that can show what it did, and under what conditions, may earn more trust than one that simply promises automation.
The value shifts from being loud to being legible.
That is a subtle change, but it feels important.
AI has already made creation easier. It has made outputs cheaper and faster. But the next problem may be sorting through all of that speed. Knowing which assets are real, which are useful, which are safe, and which ones deserve to be paid for.
OpenLedger is one attempt to work on that quieter layer.
Not the shiny front end of AI. Not the final answer on the screen. The record underneath it. The part that helps people see what they are actually using.
And maybe, as AI becomes more common, that record will matter more than we expect. Not because people want more complexity, but because they will want fewer blind spots.
$OPEN
Artículo
OpenLedger and the quiet problem of trust in AI
Aviso legal: Contiene opiniones de terceros. Esto no constituye asesoramiento financiero. Es posible que incluya contenido patrocinado. Consultar Términos y condiciones.