
Al principio, es emoción. Cada desplazamiento parece que atrapas fragmentos del futuro antes de que el resto del mundo se dé cuenta. Hace unos meses, mi timeline se inundó completamente de conversaciones sobre agentes de IA, sistemas autónomos, inteligencia descentralizada y la idea de que la inteligencia artificial se convertiría en la próxima capa económica importante de internet.
La gente estaba publicando capturas de pantalla de agentes de IA que operaban en los mercados, generando investigaciones, automatizando flujos de trabajo, escribiendo código e incluso gestionando comunidades. La energía que había a su alrededor se sentía similar a la primera era de DeFi: caótica, experimental, un poco confusa, pero imposible de ignorar.
Naturalmente, me volví curioso.
Asumí que involucrarme con la IA sería simple. En mi cabeza, parecía fácil: abrir un sitio web, conectar una billetera, tal vez personalizar algunas configuraciones, hacer clic en un botón, y de repente estás participando en la economía de la IA.
Esa ilusión desapareció casi de inmediato.
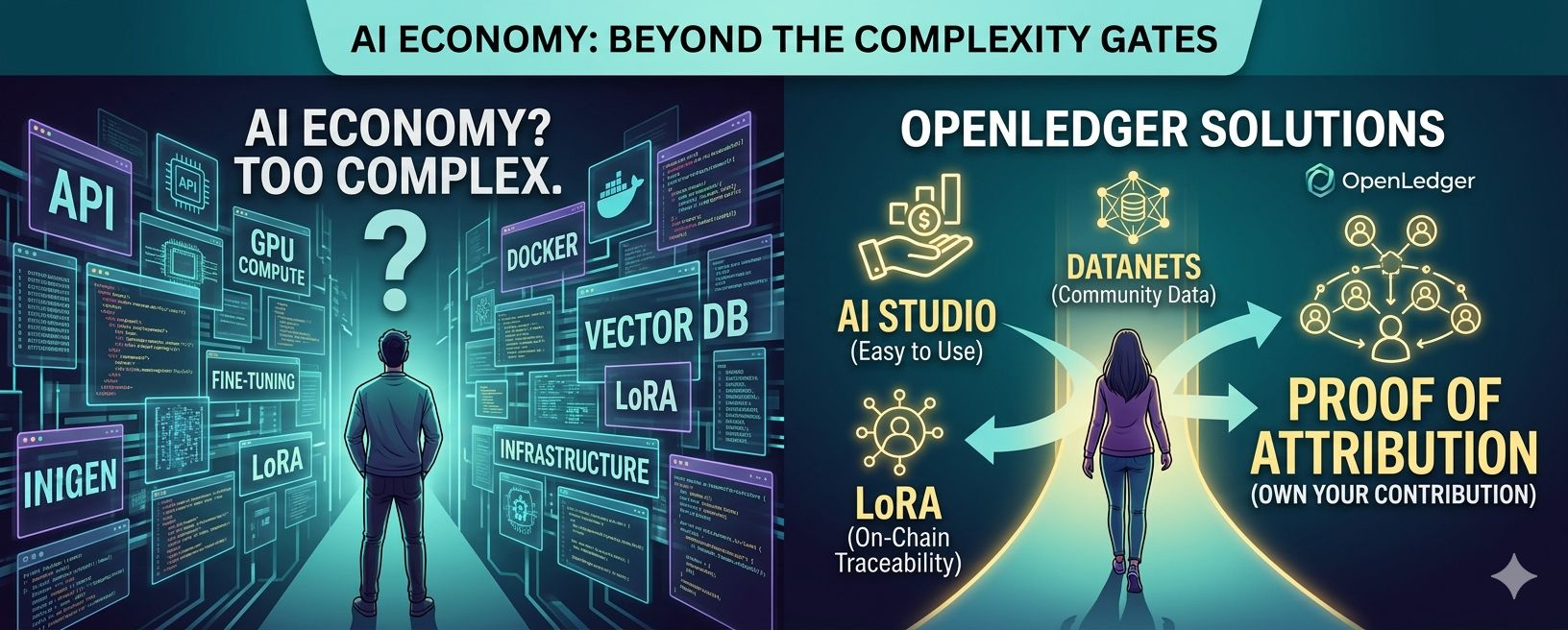
Cuanto más profundizaba, más abrumador se volvía todo. APIs. Cómputo GPU. Alojamiento de modelos. Ajuste fino. Infraestructura en la nube. Entornos de despliegue. Bases de datos vectoriales. Capas de inferencia. Contenedores Docker. Adaptadores LoRA. Dependencias de Python.
Honestamente, sentí que cada tutorial asumía que ya tenías años de experiencia técnica.
Recuerdo abrir una página de documentación tras otra y darme cuenta lentamente de que la mayoría de los sistemas de IA aún no están diseñados para las personas comunes. Incluso como alguien profundamente interesado en cripto y tecnología emergente, me sentí mentalmente agotado después de solo unas pocas horas tratando de entender cómo todo se conectaba.
Lo extraño es que la IA se comercializa constantemente como el futuro de la humanidad, sin embargo, la participación aún se siente restringida detrás de la complejidad a nivel de desarrollador.
Y ahí es donde proyectos como OpenLedger comenzaron a captar mi atención.
No por el hype.
Pero porque el proyecto parecía estar enfocado en algo más profundo: los problemas de infraestructura debajo de la propia IA.
Mientras que la mayoría de las narrativas de IA en cripto giran en torno a agentes llamativos o tokens especulativos, OpenLedger parece estar abordando el espacio desde un ángulo más fundamental: transparencia, atribución, accesibilidad e inteligencia colaborativa.
Esa diferencia importa más de lo que la gente se da cuenta.
La mayoría de las conversaciones sobre IA se centran en los resultados. OpenLedger parece estar más interesado en los sistemas que producen esos resultados en primer lugar.
Una de las partes más interesantes del ecosistema es su Fábrica de Modelos y la infraestructura OpenLoRA.
Al principio, incluso el término “adaptador LoRA” me sonaba intimidante. Pero una vez que profundicé en ello, la idea se volvió sorprendentemente comprensible.
LoRA — abreviatura de Adaptación de Bajo Rango — es esencialmente una forma ligera de ajustar modelos de IA sin tener que reentrenar todo un sistema desde cero. En lugar de reconstruir un modelo masivo cada vez, los desarrolladores pueden crear capas especializadas más pequeñas que enseñen al modelo nuevos comportamientos, estilos o pericias.
Piénsalo como agregar mejoras modulares a un sistema de inteligencia existente.
Un adaptador enfocado en salud podría enseñar a un modelo de IA la terminología médica. Un adaptador legal podría especializarse en el análisis de casos. Un adaptador multilingüe podría mejorar la comprensión de lenguas regionales.
El problema es que a medida que estos sistemas se vuelven más comunes, la transparencia comienza a desaparecer.
¿Quién entrenó el adaptador?
¿Qué datos lo influenciaron?
¿Se pueden verificar sus orígenes?
¿Fue manipulado?
Aquí es donde la infraestructura de OpenLedger se vuelve genuinamente interesante. Al habilitar la verificación y trazabilidad en la cadena para adaptadores LoRA, el proyecto está intentando crear un sistema donde los componentes de IA sean más transparentes en lugar de más opacos.
Eso puede sonar abstracto hoy, pero se vuelve increíblemente importante una vez que los sistemas de IA comienzan a influir en decisiones del mundo real a gran escala.
Si los modelos de IA eventualmente dan forma a la educación, sistemas financieros, flujos de trabajo de salud, decisiones de contratación, creación de medios o información pública, la sociedad inevitablemente comenzará a hacer preguntas difíciles sobre la confianza.
La gente querrá pruebas.
¿De dónde provino esta inteligencia?
¿Quién contribuyó a ello?
¿Qué datos moldearon su comportamiento?
¿Se puede auditar su historial de entrenamiento?
En este momento, la mayoría de los sistemas de IA operan como cajas negras. Vemos resultados, pero rara vez entendemos las contribuciones humanas invisibles detrás de ellos.
Y eso lleva directamente a lo que podría ser el concepto más importante de OpenLedger: Prueba de Atribución.
Este fue el momento en que el proyecto dejó de sentirse como "otro protocolo de cripto IA" para mí y comenzó a sentirse filosófico.
Los sistemas de IA modernos están entrenados en la humanidad misma.
Cada día, miles de millones de personas aportan fragmentos de inteligencia al mundo digital: conversaciones, investigaciones, opiniones, código, arte, escritura, tutoriales, memes, traducciones, conjuntos de datos, contexto cultural, expresión emocional y conocimiento colectivo.
Sin embargo, una vez que estas contribuciones se absorben en sistemas de IA centralizados, la mayoría de las personas desaparecen de la ecuación por completo.
Sin visibilidad.
Sin propiedad.
Sin atribución.
Sin participación en el valor que se está creando.
Ese desequilibrio se siente cada vez más difícil de ignorar.
La Prueba de Atribución (PoA) de OpenLedger intenta abordar esto rastreando cómo las contribuciones de datos influyen en los resultados de IA y creando mecanismos donde los contribuyentes pueden potencialmente recibir reconocimiento o recompensas a través del $OPEN ecosistema.
Importante, no siente como una solución perfecta aún — y el proyecto mismo aún parece estar temprano en su evolución — pero la dirección se siente significativa.
Porque la atribución puede eventualmente convertirse en una de las conversaciones definitorias de la era de la IA.
Durante años, la suposición dominante sobre la IA ha sido que quien posea más computación y los modelos más grandes gana. Pero con el tiempo, está surgiendo otra pregunta:
¿Qué pasa si el verdadero valor proviene de probar de dónde se originó la inteligencia?
Ese cambio lo cambia todo.
Recontextualiza la IA no solo como software, sino como un sistema económico colaborativo construido sobre la contribución humana.
Y honestamente, esa idea se siente difícil de ignorar una vez que comienzas a pensar en ella en serio.
Otra área donde OpenLedger se vuelve particularmente convincente es a través de Datanets.
La mayoría de la gente se obsesiona con los modelos, pero los datos son la verdadera base de cada sistema inteligente. Un modelo es tan útil como la información de la que aprende.
Datanets introduce la idea de que las comunidades pueden construir, organizar, limpiar y estructurar conjuntos de datos optimizados para modelos de lenguaje grandes y sistemas de IA de manera colaborativa.
Las implicaciones son enormes.
Imagina comunidades de investigación en salud construyendo conjuntos de datos médicos verificados juntas.
O profesionales legales organizando archivos legales transparentes para análisis asistidos por IA.
O comunidades multilingües que preservan lenguas regionales y contexto cultural que los grandes conjuntos de datos centralizados a menudo ignoran.
O analistas financieros refinando colectivamente sistemas de inteligencia de mercado de alta calidad.
Estos ya no son escenarios poco realistas.
Y quizás más importante, la colaboración de datos descentralizada podría crear sistemas de IA que sean más representativos a nivel global en lugar de estar dominados por un puñado de corporaciones que controlan conjuntos de datos cerrados.
Esa distinción importa.
Porque quien controla los datos eventualmente da forma a la inteligencia.
Luego está AI Studio, que honestamente se siente como la parte más accesible del ecosistema para los usuarios normales.
Aquí es donde OpenLedger comienza a cerrar la brecha entre infraestructura y accesibilidad.
AI Studio ofrece a creadores, desarrolladores, emprendedores e incluso a curiosos novatos un entorno donde pueden construir, personalizar, desplegar y potencialmente monetizar agentes de IA sin necesidad de dominar cada capa de infraestructura de backend desde el primer día.
Esa accesibilidad es crítica.
La adopción masiva nunca proviene de la complejidad.
Cada revolución tecnológica importante eventualmente tiene éxito porque la experiencia del usuario se vuelve lo suficientemente simple para que las personas comunes participen cómodamente.
Internet en sí alguna vez se sintió profundamente técnico. Los primeros sitios web eran confusos. Configurar servicios en línea requería paciencia y conocimiento especializado. Con el tiempo, las capas de abstracción simplificaron todo.
La misma transición aún necesita suceder para la IA.
Y proyectos enfocados en la usabilidad pueden volverse tan importantes como proyectos centrados puramente en el rendimiento del modelo.
Por supuesto, nada de esto garantiza el éxito.
OpenLedger aún enfrenta las mismas realidades difíciles que confrontan casi todos los proyectos de infraestructura de IA ambiciosos: desafíos de escalabilidad, precisión de verificación, obstáculos a la adopción, riesgos de manipulación de incentivos, complejidad de gobernanza e incertidumbre regulatoria.
La Prueba de Atribución en sí misma plantea preguntas complicadas.
¿Qué tan precisamente se puede medir la influencia de la contribución?
¿Se pueden manipular los sistemas de atribución?
¿Cómo deberían distribuirse las recompensas de manera justa?
¿Qué sucede cuando los modelos aprenden de miles de millones de fuentes interconectadas simultáneamente?
Estos no son problemas fáciles.
Pero incluso los intentos imperfectos se sienten valiosos en este momento porque la dirección más amplia importa.
La economía de la IA está creciendo más rápido que la capacidad de la sociedad para definir propiedad, responsabilidad y derechos de contribución dentro de ella.
Y eventualmente, esas preguntas se volverán imposibles de evitar.
Lo que hace interesante a OpenLedger no es la promesa de que ya ha resuelto todo.
Es el reconocimiento de que estos problemas existen en primer lugar.
Porque si la inteligencia artificial eventualmente se convierte en uno de los sistemas económicos más grandes que la humanidad haya creado, entonces la atribución puede convertirse en más que una característica técnica.
Puede convertirse en un requisito social.
Durante décadas, Internet monetizó la atención.
La IA puede monetizar la inteligencia misma.
Y si la inteligencia está siendo entrenada colectivamente por la humanidad, entonces quizás la conversación futura no solo sea sobre quién construye los modelos más poderosos, sino sobre si el valor creado por esos modelos debería permanecer centralizado bajo un pequeño número de entidades o evolucionar hacia algo más colaborativo, transparente y dirigido por la comunidad.
No creo que sepamos completamente la respuesta aún.
Pero proyectos como OpenLedger al menos están forzando que la conversación ocurra antes de lo que la mayoría de la gente esperaba.
Y honestamente, eso solo podría terminar siendo una de las contribuciones más importantes de todas.
