Hoy, mientras miraba las narrativas de IA de nuevo, empecé a pensar en una cosa…
La mayoría de los sistemas de IA en este momento todavía operan como cajas negras. Usas el modelo, obtienes la salida, pero nunca realmente sabes: dónde ocurrió la inferencia, quién la procesó, o si la ejecución puede ser verificada.
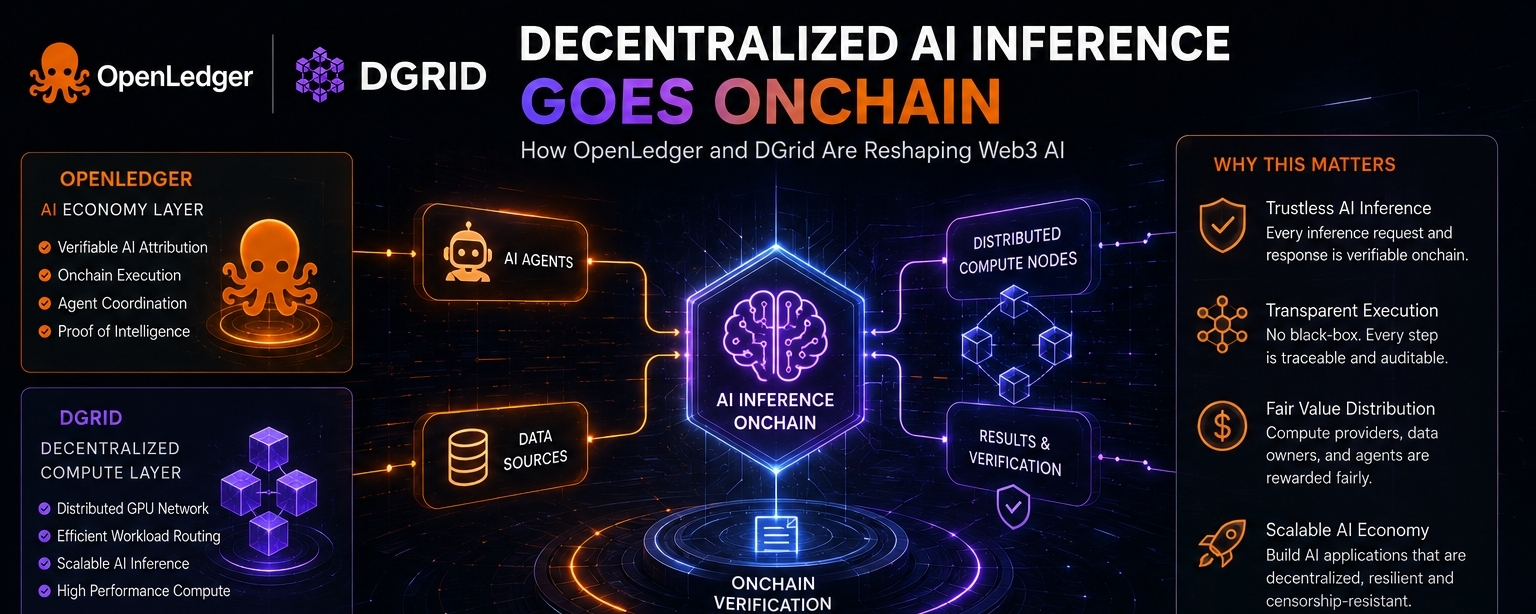
Por eso OpenLedger + DGrid empezaron a parecerme interesantes.
Lo que parecen estar construyendo no es solo computación de IA descentralizada, sino una capa de coordinación onchain donde la inferencia, ejecución y atribución se conectan entre sí.
DGrid parece manejar cómputo distribuido + enrutamiento de carga de trabajo, mientras que OpenLedger actúa más como la capa de coordinación y verificación por debajo.
Y honestamente, creo que esta dirección importa más de lo que la gente se da cuenta.
Porque una vez que los agentes de IA comienzan a operar, ejecutando flujos de trabajo o procesando datos on-chain de manera autónoma... la confianza se convierte en un gran problema.
Si un agente de IA da una señal: ¿Se puede verificar la inferencia? ¿Se puede auditar la ejecución? ¿Se puede detectar la manipulación de carga de trabajo?
Ahí es donde la infraestructura de IA on-chain comienza a volverse mucho más grande que solo el hype de los “agentes de IA”.
De hecho, cometí un error tonto a principios de esta semana persiguiendo pumps de narrativas de IA de baja capitalización en lugar de prestar atención a los plays de infraestructura 🤦♂️
Se siente como si el mercado estuviera cambiando lentamente de: “mira esta herramienta de IA genial” a: “quién controla la infraestructura que impulsa las economías de IA.”
Aún es temprano, aunque 😅
Muchos proyectos suenan poderosos a nivel narrativo, pero la coordinación en el mundo real, la latencia y la alineación de incentivos son problemas mucho más difíciles de resolver.
Veamos si la inferencia de IA descentralizada realmente escala... o si la mayoría de los sistemas colapsan una vez que llega el uso real 🤔...@OpenLedger #OpenLedger $OPEN