

Está bien... déjame decir una cosa honestamente al principio.
Cuando la mayoría de la gente escucha “agentes de IA” en cripto, todavía imaginan chatbots glorificados con comentarios de mercado adjuntos. Unos pocos comandos, un panel de control, tal vez algo de automatización — y de repente todo se etiqueta como “infraestructura agente”. Pero después de pasar tiempo profundizando en @OpenLedger arquitectura y la capa de ejecución de OctoClaw, me di cuenta de que algo se siente fundamentalmente diferente aquí.
Esto no parece otro experimento de interfaz de IA.
Se siente más como la fase de construcción temprana de una economía de ejecución autónoma.
Y honestamente... ese cambio es mucho más grande de lo que la gente se da cuenta ahora mismo.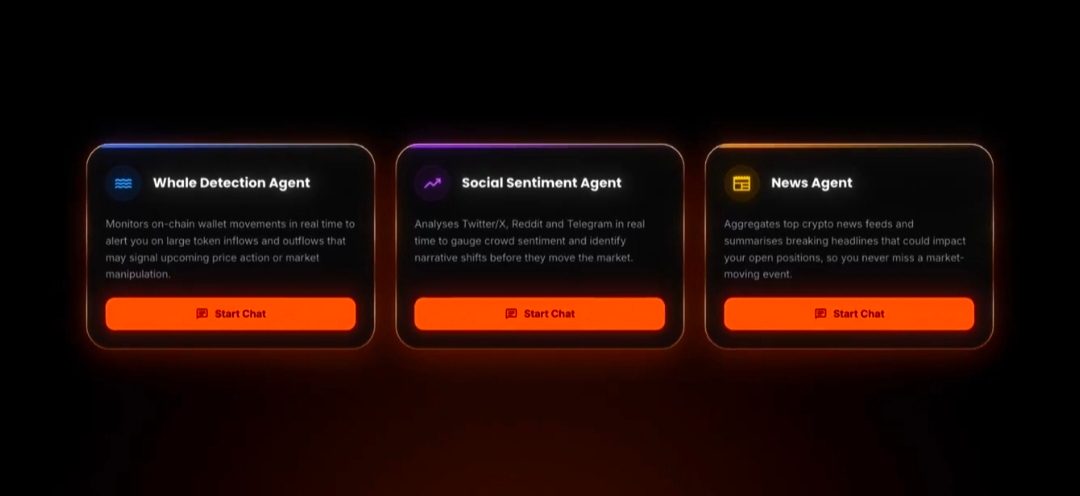
Lo primero que llamó mi atención no fue la IA en sí — sino la estructura a su alrededor. Porque OpenLedger está construyendo en silencio algo que la mayoría de los proyectos evitan tocar directamente: la capa de coordinación entre la toma de decisiones de IA y la ejecución real en la cadena.
Eso suena abstracto al principio. Pero si lo simplificas, la idea se vuelve muy clara:
La mayoría de los sistemas de IA hoy pueden analizar. Muy pocos pueden realmente operar.
OctoClaw cambia la conversación de: 'IA que da sugerencias' a 'IA que puede ejecutar flujos de trabajo'.
Y psicológicamente, eso es una categoría completamente diferente.
Ahora vayamos a la parte interesante — mecánicas de Cloud Config.
A primera vista, suena aburrido. Casi demasiado técnico para importar. Pero, en realidad, esta puede ser una de las capas más importantes en todo el ecosistema. Porque si los agentes de IA van a interactuar con mercados, bóvedas, puentes, pools de liquidez y sistemas cross-chain... entonces necesitan permisos estructurados y límites de comportamiento.
Sin eso, todo se convierte en caos muy rápidamente.
Así que lo que OpenLedger parece estar construyendo aquí no es autonomía sin restricciones, sino autonomía programable.
Esa distinción importa mucho.
La capa de Cloud Config casi se siente como un panel de control de sistema operativo donde se definen las reglas de ejecución antes de que la inteligencia actúe. Umbrales de riesgo, lógica de reequilibrio, permisos, estados de memoria, estructuras de estrategia — todo esto se vuelve configurable en lugar de ser guionado manualmente cada vez.
Y honestamente... ahí es donde la narrativa de infraestructura comienza a volverse seria.
Porque la mayoría de la gente aún piensa que la carrera de IA se trata de mejores respuestas.
Pero los jugadores a nivel de infraestructura están comenzando a enfocarse en algo completamente diferente: coordinación de ejecución.
Ahora vayamos al sistema de Agentes de Trading.
Aquí es donde todo esto comienza a sentirse menos teórico.
Como lo veo, OpenLedger no está posicionando a estos agentes como 'bots de trading' en el sentido tradicional de retail. Esa narrativa es demasiado pequeña. Lo que en realidad están experimentando es con la orquestación de capital autónomo.
Eso significa: monitorear mercados, mover liquidez, optimizar rendimientos, reequilibrar estrategias, interactuar con bóvedas y, eventualmente, coordinar a través de múltiples ecosistemas sin intervención humana constante.
Y si soy completamente honesto... esto puede convertirse en una de las transiciones psicológicas más grandes en cripto durante los próximos años.
Porque por primera vez, los mercados están comenzando a pensar en la IA no como una herramienta al lado de las finanzas — sino como un participante activo dentro de las finanzas.
Eso cambia toda la conversación sobre arquitectura.
Otra cosa que se vuelve muy interesante aquí es la integración de ERC-4626.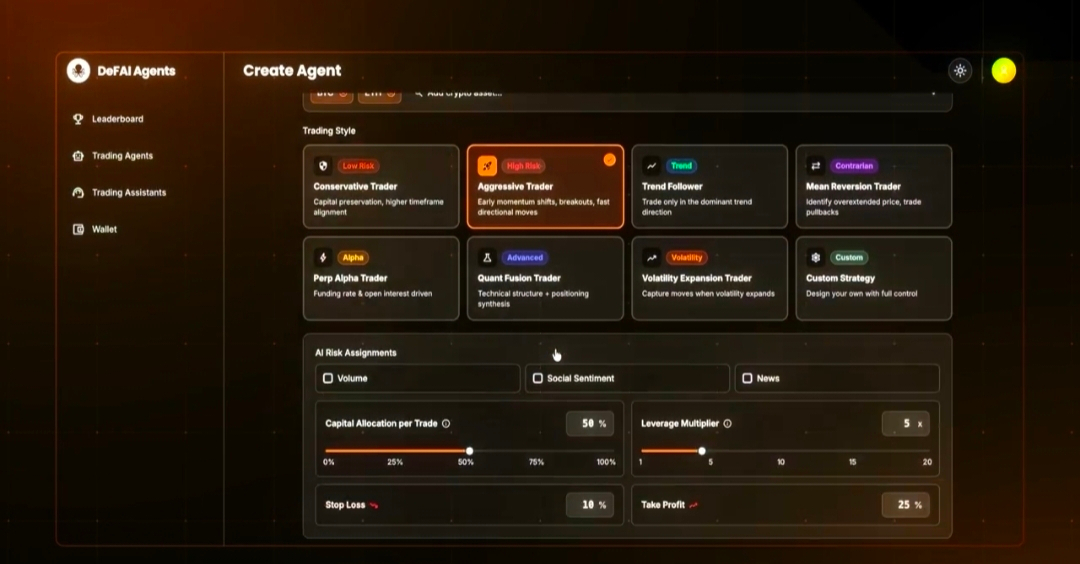
La mayoría de la gente probablemente pasó por alto este anuncio porque los estándares no son emocionantes en la superficie. Pero en realidad, esta puede ser una de las decisiones de infraestructura más inteligentes que OpenLedger ha tomado.
¿Por qué?
Porque los agentes autónomos no pueden escalar de manera eficiente a través de DeFi si cada protocolo se comporta de manera diferente.
Las estructuras de bóveda estandarizadas resuelven este problema.
ERC-4626 básicamente crea un lenguaje financiero compartido para activos que generan rendimiento. Así que en lugar de construir lógica personalizada para cada integración, los agentes pueden interactuar con múltiples sistemas de bóveda a través de un marco común.
Suena técnico, sí. Pero estratégicamente... esto es enorme.
Porque cuando los agentes de IA finalmente comiencen a gestionar capital a gran escala, la interoperabilidad se vuelve más importante que la inteligencia misma.
Y honestamente, esa es una realización muy subestimada.
Ahora déjame contarte la parte que realmente cambió la vibra para mí: vibecoding.
Al principio, me reí un poco cuando vi el término porque sonaba como otra palabra de moda de CT. Pero después de pensar más profundamente, entendí lo que OpenLedger está tratando de hacer aquí.
Están reduciendo la barrera psicológica entre la idea y el despliegue.
Eso es poderoso.
Históricamente, el desarrollo de IA estaba restringido por la complejidad técnica: terminales, frameworks, gestión de dependencias, entornos GPU, pipelines de ajuste fino.
Pero OpenLedger está lentamente cambiando el modelo de interacción hacia la creación de flujos de trabajo naturales en lugar de rituales de ingeniería hardcore.
Y, les guste o no a las personas... así es exactamente como comienza la experimentación masiva.
Lo mismo sucedió con los sitios web. Luego aplicaciones. Luego creación de contenido.
La complejidad se abstrae hasta que la participación explota.
Ahora aquí viene la capa más profunda que la mayoría de la gente aún está ignorando: Datanets y economía de contribuciones.
Esta es probablemente la parte más intelectualmente interesante de la arquitectura de OpenLedger.
Porque el proyecto está tratando de resolver algo que la industria de la IA aún maneja muy mal: la atribución.
Ahora mismo, los datos fluyen hacia los modelos como combustible invisible. Los contribuidores rara vez capturan valor a largo plazo. Los pipelines de entrenamiento siguen siendo en su mayoría extractivos.
OpenLedger está experimentando con la idea opuesta: ¿y si los datos mismos se convirtieran en un activo económico ganado?
Y honestamente... esto crea una extraña tensión dentro del sistema.
Por un lado: participación abierta, contribución descentralizada, ecosistemas sin permisos.
Por el otro lado: validación estricta, filtros de calidad, sistemas de aceptación estructurados, formato controlado.
Al principio, esta contradicción se siente incómoda. Casi anti-Web3.
Pero cuanto más pensaba en ello, más sentido empezaba a tener.
Porque la contribución sin restricciones suena hermosa filosóficamente... hasta que la señal queda enterrada bajo el ruido.
Y OpenLedger parece estar plenamente consciente de este problema.
El sistema de contribuciones refleja esa mentalidad: límites diarios, mecánicas de validación, importancia de la tasa de aceptación, formato estructurado.
Esto no está optimizado para volumen. Está optimizado para inteligencia utilizable.
Y honestamente, eso cambia completamente la psicología de los incentivos.
Una cosa que encontré sorprendentemente saludable es que las contribuciones rechazadas no castigan fuertemente la experimentación. Esa sutil elección de diseño importa más de lo que la gente piensa. Porque una vez que los contribuidores se vuelven impulsados por el miedo, la innovación se desacelera.
Así que el ecosistema intenta mantener un extraño equilibrio: disciplina sin desincentivar la experimentación.
No es fácil de lograr.
Ahora vamos a ModelFactory.
Este es probablemente el ejemplo más claro de cómo OpenLedger intenta democratizar el desarrollo de IA sin convertir el ecosistema en un completo desorden.
La plataforma soporta: LLaMA, Qwen, Mistral, DeepSeek, BLOOM, ChatGLM, y múltiples ecosistemas abiertos.
A primera vista, parece una estrategia de marketing de amplia compatibilidad. Pero, estratégicamente, es expansión del ecosistema.
Porque apoyar solo modelos de élite crea una experimentación limitada. Un amplio soporte crea capas de descubrimiento.
Y el flujo de ajuste fino basado en GUI es en realidad más importante de lo que la gente se da cuenta.
La mayoría de la gente subestima cuánto fricción mata la innovación.
Si el entrenamiento de modelos permanece siempre pesado en terminales, la participación sigue siendo de élite. Pero una vez que los flujos de trabajo se vuelven visuales e interactivos: entrenar → probar → refinar → redeplegar se convierte en continuo en lugar de intimidante.
El soporte para LoRA y QLoRA también muestra que OpenLedger entiende las realidades económicas actuales.
El ajuste completo es costoso. La adaptación ligera escala mejor.
Ese pensamiento práctico aparece repetidamente a lo largo del ecosistema.
Nada aquí parece construido puramente para la exageración. La mayoría de los componentes se sienten diseñados en torno a la eficiencia operativa.
Ahora déjame explicarte la extraña imagen que sigue viniendo a mi cabeza cada vez que estudio este ecosistema 😂
OpenLedger se siente como una cocina futurista muy disciplinada.
Nadie puede lanzar ingredientes al azar por todas partes. Todo tiene estructura, medición, validación, reglas de flujo de trabajo.
Pero una vez que el sistema funcione... la cocina se vuelve escalable.
Y honestamente, eso puede ser el punto filosófico entero aquí.
Porque cripto pasó años optimizando para la apertura. La IA pasó años optimizando para la capacidad.
Pero OpenLedger parece estar planteando una pregunta diferente:
¿Puedes construir una economía de IA abierta sin colapsar en un caos informativo?
Ese es un problema mucho más difícil que lanzar otro token de IA.
Ahora vayamos a la parte que creo que el mercado aún subestima más: los agentes de IA como actores económicos.
Aquí es donde OctoClaw comienza a convertirse en más que infraestructura.
Porque si los agentes eventualmente: mantienen wallets, mueven activos, coordinan liquidez, entrenan modelos, optimizan estrategias e interactúan a través de cadenas...
entonces se requieren marcos económicos completamente nuevos.
No solo modelos de IA. No solo blockchains.
Pero sistemas para: verificación, permisos, atribución, liquidación cross-chain, propiedad de datos y coordinación autónoma.
Esa es la capa alrededor de la cual OpenLedger parece estar posicionándose.
Y tal vez por eso el proyecto se siente diferente de la mayoría de las narrativas de IA en este momento.
No está tratando de construir 'otro asistente'.
Está tratando de construir rieles operativos para economías de máquinas.
¿Funcionará todo esto perfectamente? Honestamente... no lo sé.
Todavía hay preguntas difíciles: ¿Puede la atribución escalar? ¿Puede la ejecución autónoma seguir siendo segura? ¿Pueden las economías de datos descentralizadas evitar la manipulación? ¿Puede la coordinación de agentes funcionar de manera eficiente a través de ecosistemas fragmentados?
Nadie realmente tiene respuestas finales aún.
Pero creo que esta es exactamente la razón por la que OpenLedger se ha vuelto interesante de observar.
Porque debajo de las palabras de moda de IA y anuncios de infraestructura, en realidad hay un experimento mucho más profundo sucediendo aquí:
La transición de la IA de inteligencia pasiva... a participación económica activa.
Y si esa transición realmente sucede a gran escala un día...
entonces OctoClaw puede terminar representando algo mucho más grande que un lanzamiento de producto.
Puede representar el momento en que la IA dejó de hablar — y comenzó a ejecutar en silencio.
\u003cm-53/\u003e\u003ct-54/\u003e\u003cc-55/\u003e