o simplemente esperanza tokenizada)
He estado revisando la documentación de openledger y hilos aleatorios para entender qué es lo que realmente están construyendo, y lo que llamó mi atención no es el titular de “ai + blockchain”. es el intento de convertir entradas de ai desordenadas y fuera de la cadena (datos, etiquetas, salidas de modelos, evaluaciones) en algo que la cadena pueda coordinar económicamente sin pretender que la cadena pueda almacenar o verificar todo directamente.
la mayoría de la gente piensa que openledger es solo otro token de ai + crypto con un marketplace pegado. entiendo por qué — la narrativa superficial es básicamente “los contribuyentes suben datos, obtienen recompensas.” pero la parte más interesante (y frágil) es el diseño de red a largo plazo: quién puede demostrar que agregó valor, y si el sistema puede pagar por ese valor sin depender para siempre de las emisiones.
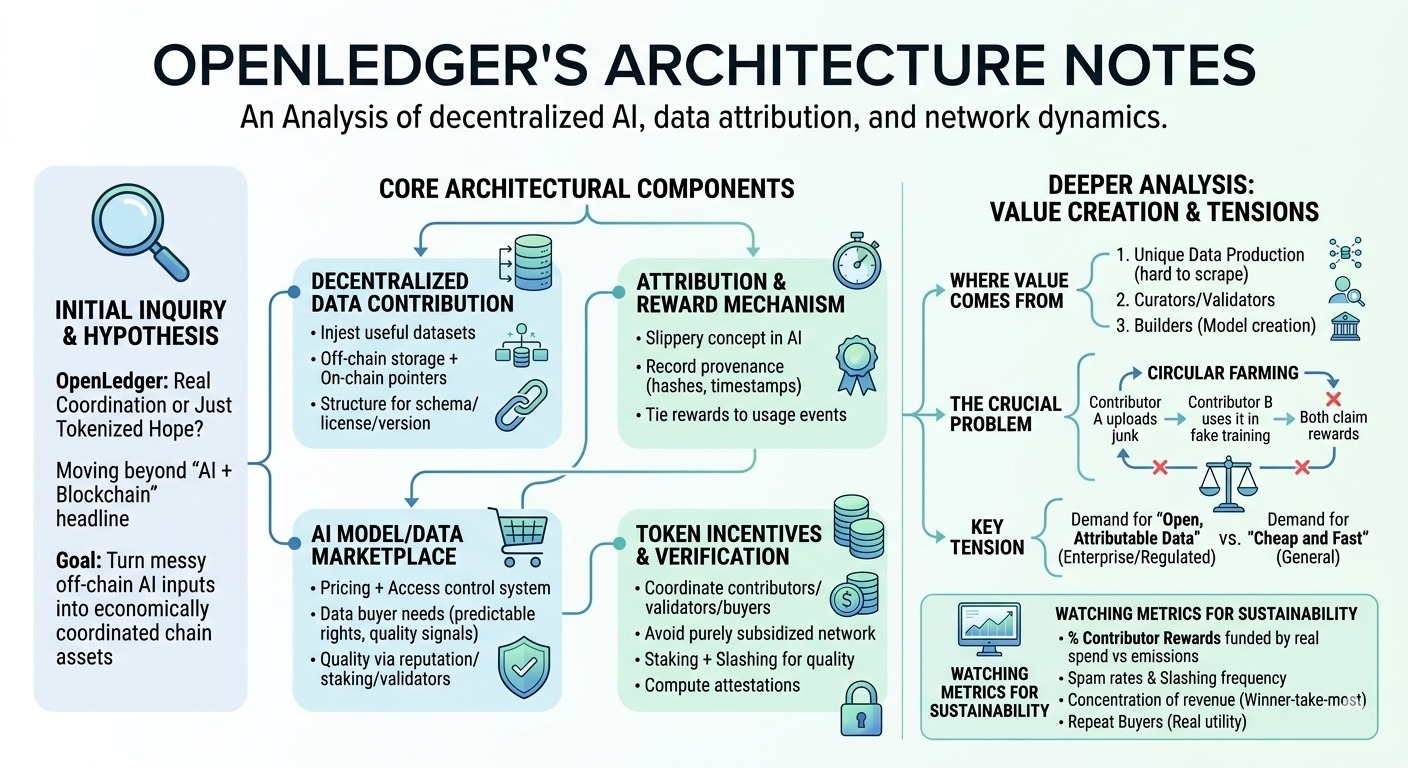
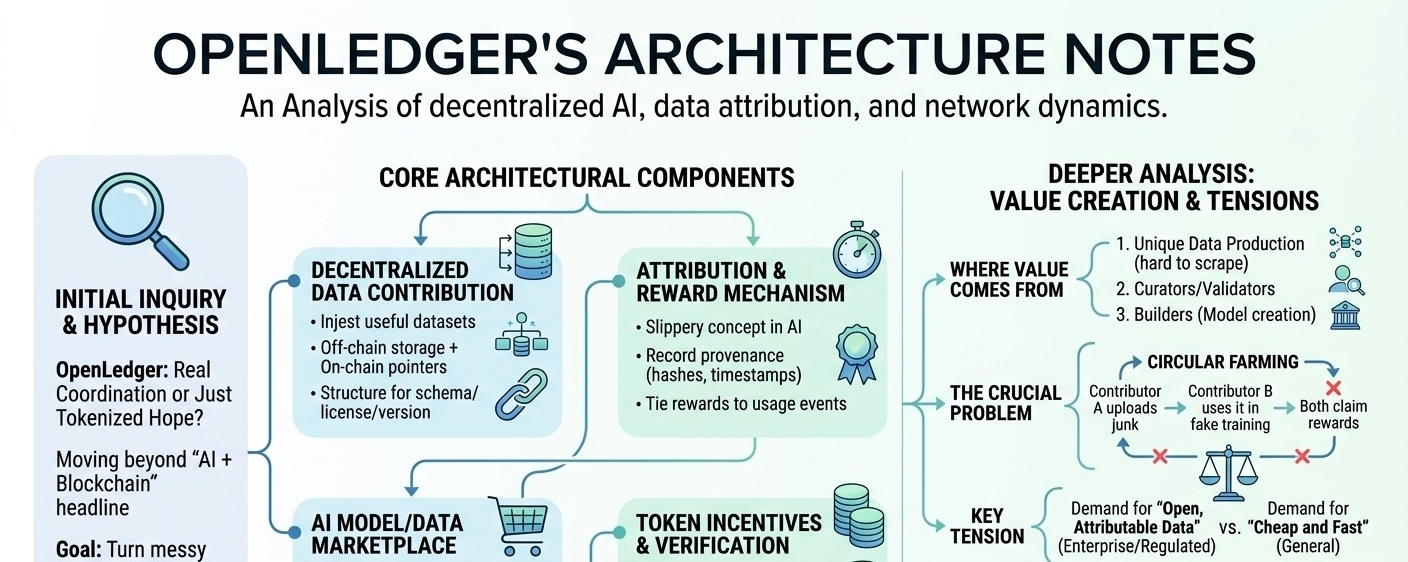
Pocos componentes parecen centrales:
1) sistema de contribución de datos descentralizado
El sistema vive o muere en función de si puede atraer conjuntos de datos útiles, no solo volumen. En la práctica, eso significa tuberías para ingerir datos (probablemente almacenamiento fuera de la cadena + punteros/hash en la cadena), además de alguna estructura en torno a esquemas, licencias y versiones. Supongo que necesitarán convenciones sólidas aquí, de lo contrario, los contribuyentes optimizarán para lo que sea más fácil de subir. El ángulo 'descentralizado' es menos sobre almacenamiento y más sobre quién puede participar en la creación del corpus.
2) atribución + mecanismo de recompensas
openledger sigue enfatizando la atribución, y honestamente, esta es la parte en la que continúo pensando... porque la atribución en la IA es resbaladiza. No es como un contrato inteligente donde puedes rastrear la ejecución de manera determinista. El enfoque creíble suele ser: registrar la procedencia (hashes, marcas de tiempo, IDs de contribuyentes), luego vincular las recompensas a eventos de uso (se extrajo un conjunto de datos para un entrenamiento, un modelo afinado lo referenció, un benchmark de evaluación lo utilizó, etc.). Pero luego la difícil pregunta: ¿quién atestigua que ocurrió el uso, y qué impide que se generen bucles de uso falso?
3) dinámica del mercado de modelos/datos de IA
Si están serios, el 'mercado' no es una vitrina, es un sistema de control de precios + acceso. Los compradores de datos (constructores de modelos, equipos de aplicaciones) necesitan derechos predecibles: ¿pueden entrenar? ¿pueden redistribuir salidas? ¿es exclusivo? y necesitan señales de calidad. Las plataformas abiertas luchan aquí porque la calidad es cara de verificar y las plataformas centralizadas lo solucionan con revisión interna + contratos. openledger está tratando de externalizar eso en mecánicas de red (reputación, staking, validadores de terceros, tal vez subredes curadas). No estoy seguro de cuán maduro es eso todavía.
4) incentivos de tokens y capa de coordinación/verificación de la red
La pieza del token parece destinada a coordinar a los contribuyentes, validadores/curadores y compradores. Pero también es donde se encuentra la pregunta '¿es real la demanda?'. Si la mayoría de las recompensas provienen de emisiones en lugar de compradores reales que pagan por conjuntos de datos/modelos, la red puede parecer saludable mientras está básicamente subsidiada. Algún tipo de capa de verificación (staking + recortes por malos datos, atestaciones firmadas, tal vez incluso atestaciones de cómputo) ayudaría, pero también es una carga adicional.
Profundizando: ¿quién crea valor?
Creo que el valor proviene de tres lugares: (a) personas produciendo datos únicos que son difíciles de raspar (etiquetas específicas de dominio, transcripciones multilingües, datos de sensores de nicho), (b) curadores/validadores que hacen que esos datos sean utilizables, y (c) constructores que los convierten en modelos por los que la gente paga para usar. La apuesta del protocolo es que la atribución en cadena puede redirigir dinero de vuelta a (a) y (b) automáticamente. Pero la atribución sigue siendo confiable solo si el 'uso' es difícil de falsificar. De lo contrario, obtienes agricultura circular: el contribuyente A sube chatarra, el contribuyente B 'lo usa' en un trabajo de entrenamiento falso, ambos reclaman recompensas.
Un ejemplo realista: imagina un conjunto de datos de ajuste fino para atención al cliente (registros de chat, intenciones etiquetadas, redacciones). Si un constructor de modelos paga para ajustarlo, puedes atribuir esa compra. Pero atribuir el valor posterior (los ingresos de inferencia del modelo más tarde) es mucho más difícil a menos que la inferencia ocurra a través de una puerta de enlace medida que el protocolo pueda observar. Los sistemas abiertos tienden a filtrar aquí: los modelos se exportan, se sirven de forma privada y la cadena no ve nada.
La tensión que no puedo sacudirme
openledger parece asumir una demanda sostenida de 'datos abiertos y atribuibles' por parte de los constructores de IA. Tal vez eso sea cierto en contextos regulados o empresariales, donde la procedencia importa. Pero mucha de la demanda de IA todavía quiere barato y rápido, no necesariamente atribuible. Y los incentivos para los contribuyentes se sienten frágiles: si las recompensas son altas, llega un aluvión de spam; si las recompensas son bajas, solo los aficionados contribuyen. La sostenibilidad probablemente requiera un ciclo ajustado donde los compradores reales paguen por una utilidad real, y el token sea principalmente una herramienta de coordinación, no el producto.
Observando:
- % de las recompensas de los contribuyentes financiadas por el gasto real del mercado frente a las emisiones
- tasas de spam/baja calidad y con qué frecuencia se activan realmente los recortes/sanciones
- concentración: ¿hacen unos pocos curadores/conjuntos de datos dominar los ingresos (dinámicas de ganador-se lleva-lo-más)?
- compradores recurrentes: ¿los equipos regresan a comprar acceso a datos/modelos, o es solo una vez?
Aún no tengo una conclusión clara. Puedo imaginar un mundo donde la atribución + licencias + vías de pago realmente ayudan a que los mercados de datos de nicho funcionen. También puedo verlo convirtiéndose en un juego de recompensas elaborado que parece activo hasta que las subvenciones disminuyen. La pregunta que sigo repitiendo: ¿puede openledger medir el 'uso' de una manera que sea tanto respetuosa con la privacidad como difícil de falsificar, sin re-centralizar silenciosamente todo?
\u003cc-46/\u003cm-47/\u003ct-48/\u003e