
Chévere, déjame decirte algo desde el principio - cuando miras estos tipos de sistemas, piensas primero "todo está controlado, reglas rígidas, restricciones..." Pero si miras más a fondo, puedes entender que aquí no es exactamente un caos, sino más bien un intento de crear una estructura intencionada - así es.
Si te digo la verdad desde el fondo de mi corazón.... La forma en que interpreto @OpenLedger la documentación, en una línea - no es solo una IA o una plataforma de datos, sino un experimento en toda la idea de cómo los datos pueden convertirse en un "activo ganado". Ahora vamos a desmenuzar esto porque si juntas todo, no te va a caber en la cabeza - de ninguna manera va a caber.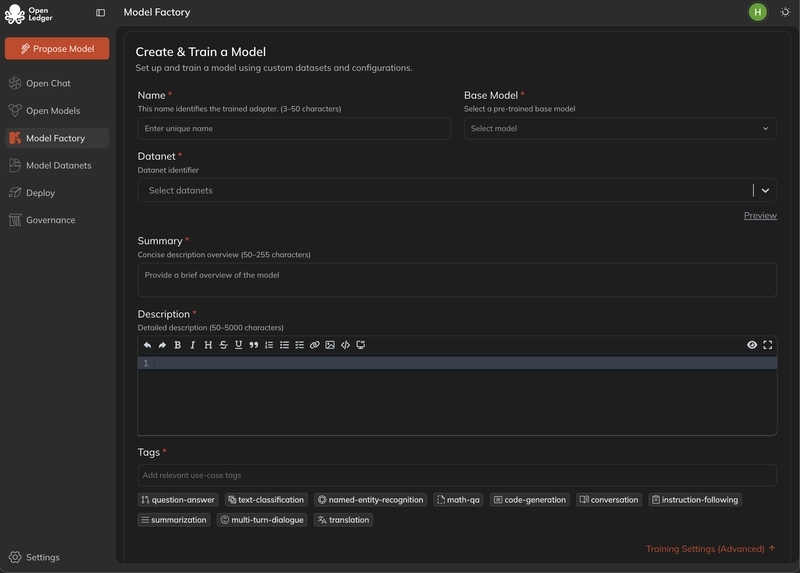
Primero viene la capa de Contribución de los Datanets.
Lo más interesante aquí son las restricciones. Texto, imágenes, audio - no puedes mezclarlo todo. Suena un poco extraño, porque cuando hablamos de Web3, generalmente pensamos en todo sin permiso. Pero aquí es lo opuesto - formato riguroso, validación rigurosa. Límite de 10 MB por día, 20 archivos - esto también parece pequeño, pero en realidad no es un control de spam, sino un intento de mantener la relación señal-ruido correcta. Porque si es ilimitado, todo el mundo contribuirá, pero será difícil encontrar valor.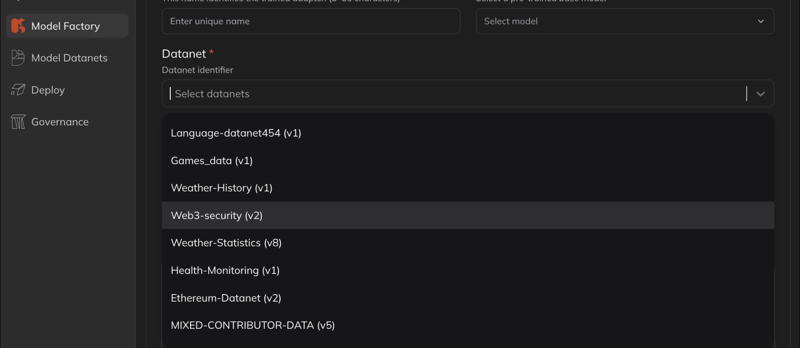
Otra cosa que parece un poco graciosa - el sistema de leaderboard.
Puedes estar pensando "cuanto más subo, más alto voy" - pero no, de ninguna manera. Aquí, no es la cantidad lo que importa, sino la tasa de aceptación. Quiero decir, si das 10 datos incorrectos, tu ego puede estar feliz, pero el sistema no se preocupará por ti. Un poco duro, pero justo. Y la parte interesante es que los archivos rechazados no reducen la clasificación. Este es un diseño extrañamente saludable. Porque la experimentación es incentivada aquí, no la contribución movida por el miedo.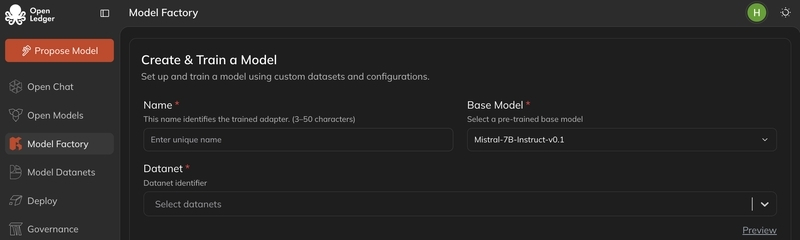
Entonces viene la mecánica del ModelFactory.
Esta es, de hecho, la parte más seria del OpenLedger. Cambia completamente la vibra aquí. Están tratando de transformar el ajuste fino de LLM en un flujo de trabajo guiado por interfaz en lugar de solo mantenerlo como una herramienta de investigación. Eso significa que no necesitas ser un guerrero de terminal. Tasa de aprendizaje, tamaño del lote, época - todo puede ajustarse visualmente. A primera vista, parece - ok, amigable para principiantes, pero en realidad hay una idea más profunda detrás de esto - democratizar el desarrollo de IA sin perder el control.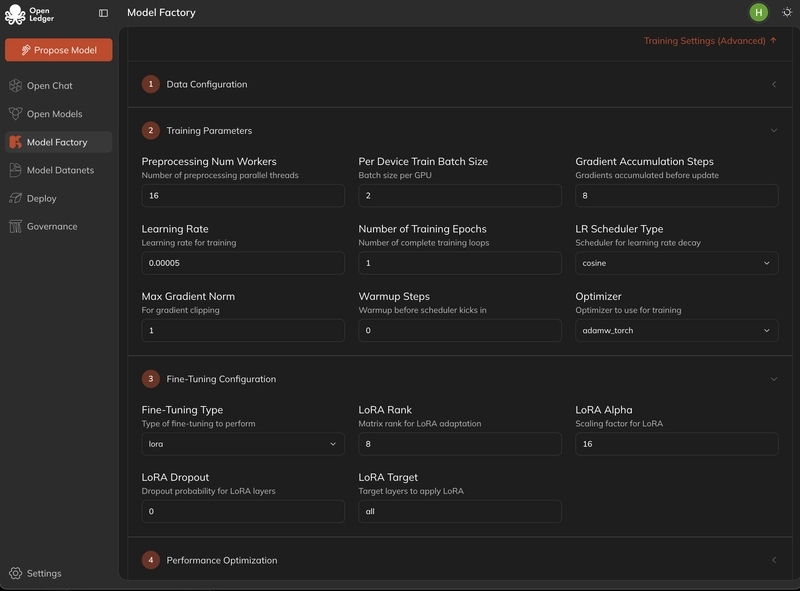
El soporte para LoRA y QLoRA es un movimiento práctico aquí. Porque el ajuste fino completo es caro en la realidad de hoy. Entonces, están siguiendo un camino de adaptación ligera. Panel en tiempo real e interacción post-entrenamiento - esta cosa es bastante interesante, porque quieren hacer del entrenamiento de modelos un bucle continuo sin dejar un punto final. Eso significa entrenar ⇨ probar ⇨ interactuar ⇨ refinar.
Ahora hablemos sobre los LLMs soportados.
Deepseek, Mistral, Qwen, serie LLaMA - todos los grandes ecosistemas abiertos están aquí. Incluso el GPT-2, BLOOM, ChatGLM son soportados. Al principio, puede parecer que incluyeron todo, pero en realidad es una estrategia de cobertura de ecosistema. Porque si mantienes solo modelos de élite, te quedarás limitado. Pero un soporte amplio significa un gran espacio para experimentación.
Ahora déjame contarte una parte graciosa
Una imagen viene a mi mente cuando veo todo este sistema - una cocina muy disciplinada, donde nadie puede lanzar ingredientes aleatoriamente. Pero cuando la cocción termina, todos pueden probar y evaluar. Eso significa que no puedes sobrevivir aquí solo con buenas vibras, aunque quieras.
La última parte de las Instrucciones del Agente es, de hecho, la más subestimada.
Porque aquí se dice que, para consultas profundas, se pueden obtener respuestas dinámicas usando la URL del GitBook. No son básicamente documentos estáticos, sino un sistema de conocimiento consultable.
Ahora, si piensas en esto de manera general, una cosa queda clara..... \u003cm-34/\u003ena verdad está entre dos tensiones: por un lado, descentralización + contribución abierta, por otro lado, validación rigurosa + estructura controlada. No es fácil mantener estas dos cosas juntas. Pero si el equilibrio está bien, entonces puede crear una verdadera economía de datos en lugar de ruido. Y, para ser honesto, aquí es donde la cuestión se vuelve interesante - ¿los datos realmente serán un activo del futuro, o solo estamos tratando de resolver un antiguo problema de validación con un nuevo nombre?
No estoy seguro si hay una respuesta final ahora. Pero como una capa de experimentación, no vale la pena ignorar... Pero realmente🚀
\u003cm-25/\u003e \u003cc-27/\u003e\u003ct-28/\u003e
\u003cc-8/\u003e