Años de investigación que pensé que eran inútiles. Resulta que no lo eran.
Tengo una carpeta en mi computadora llamada 'investigación antigua.'
Dentro hay cientos de archivos: datos en cadena, análisis de distribución de tokens, patrones de comportamiento de wallets de ballenas, notas de noches pasadas observando el mempool hasta las 2am. La mayoría de ello nunca se volvió a usar. Algunos archivos pensé que estarían ahí para siempre.
Nunca pensé que tuvieran valor para alguien más que para mí.
Hasta que leí parte de la Ley de IA de la UE el mes pasado.
Hay un detalle que creo que la mayoría del mercado está subestimando: las empresas que implementan IA necesitarán demostrar cada vez más la procedencia de los datos — qué datos produjeron qué salida, quién contribuyó, quién dio consentimiento para su uso, auditable y verificable en cada paso.
Me senté allí leyendo y me pregunté:
¿Cuántos sistemas de IA hoy pueden realmente hacer eso?
Casi ninguno.
Ahí es cuando miré mi carpeta de 'investigación antigua' de una manera completamente diferente.
Porque me di cuenta: esto es exactamente lo que los modelos de IA necesitan — y en este momento no hay casi ningún mercado legítimo, transparente y verificable para comerciarlo.
Los datos de comportamiento cripto de alta calidad no viven en rasguños de Twitter o números crudos de exploradores de bloques.
Vive en el contexto.
En personas que han pasado años entendiendo la estructura del mercado, el comportamiento de la liquidez, ciclos de pánico, patrones de coordinación entre dinero inteligente.
Lo que tengo no fue construido por un script corriendo toda la noche. Fue construido con tiempo.
Y en este momento, la mayoría de esos datos están muertos en discos duros personales alrededor del mundo.
Aquí es donde creo que la mayoría del cripto está interpretando mal la narrativa de la IA.
Todos están discutiendo sobre qué modelo es más inteligente. Pero los modelos están convirtiéndose en mercancía más rápido de lo que la mayoría de la gente piensa. El código abierto está cerrando la brecha entre sistemas muy rápido. La computación eventualmente será algo que cualquiera con dinero podrá comprar.
Pero los datos de alta calidad con una clara procedencia no lo serán.
Y la regulación lo hará aún más escaso.
La Ley de IA de la UE no es el final. Es el comienzo de un periodo donde las empresas de IA se ven obligadas a responder: ¿de dónde vino este dato y quién acordó dejarte usarlo?
Esa pregunta romperá muchos modelos de negocio actuales de IA.
Ahí es cuando OpenLedger comenzó a interesarme.
Al principio era escéptico por reflejo — IA x blockchain, narrativa familiar, presentación bonita. Pero cuando lo coloqué en el contexto regulatorio anterior, la lógica comenzó a cambiar.
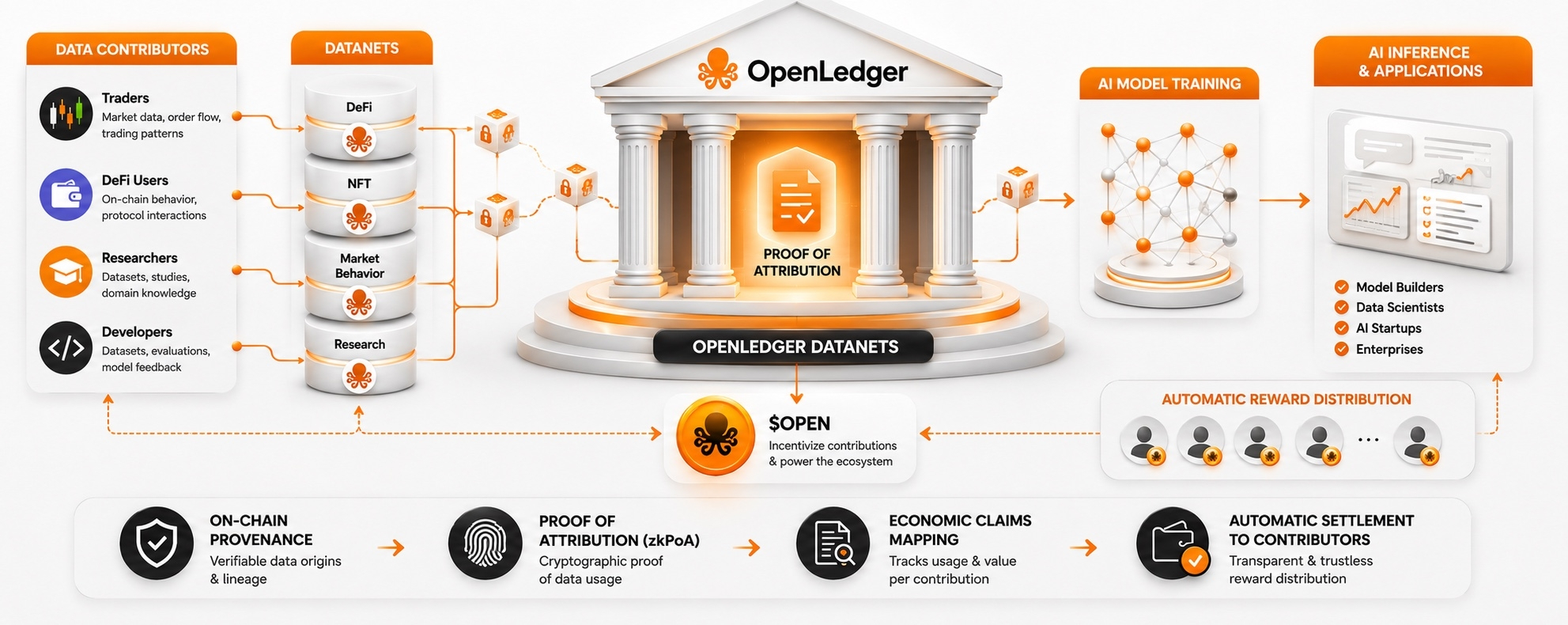
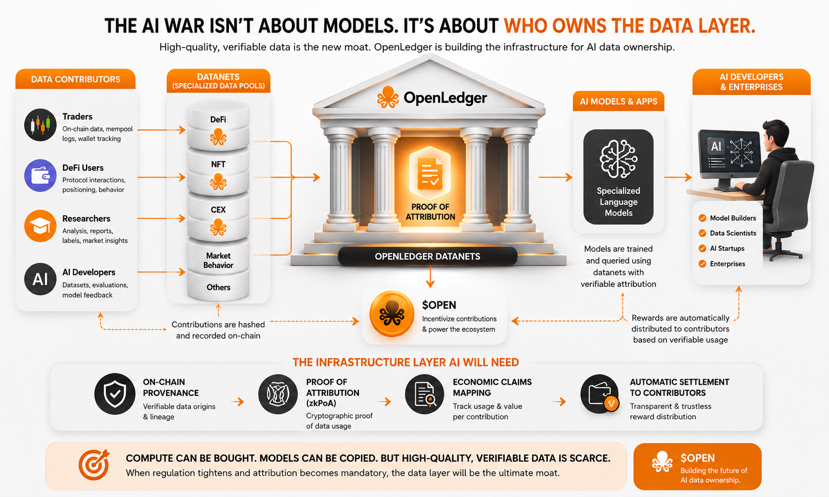
La Prueba de Atribución está esencialmente convirtiendo las contribuciones de datos en algo verificable, auditable y rastreable en la cadena.
Más específicamente: los datos se contribuyen en Datanets — grupos de datos específicos de dominio donde cada contribución se hash y se registra en la cadena. Cuando un modelo es entrenado y consultado, el sistema rastrea la pista de atribución y distribuye automáticamente recompensas a los contribuyentes correctos.
Suena simple. Pero el verdadero problema es: en un modelo con miles de millones de parámetros, los datos no se almacenan como archivos — se aprenden y distribuyen a través de capas. No hay una forma directa de saber cuánto influyó cualquier conjunto de datos en cualquier salida dada.
OpenLedger está solucionando esto con zkPoA — Prueba de Conocimiento Cero de Atribución. Los contribuyentes pueden probar criptográficamente que sus datos fueron utilizados sin exponer toda la historia de entrenamiento. Portátil entre cadenas, verificable sin repetir toda la historia.
No sé si funciona perfectamente a gran escala aún. Nadie ha resuelto eso. Pero esta es la primera vez que veo a alguien intentando resolver el problema correcto — en lugar de solo hablar de ello.
Si esto funciona a gran escala: los archivos en mi carpeta de 'investigación antigua' ya no son notas inútiles.
Se convierten en activos.
No por la narrativa. Sino porque por primera vez veo que la blockchain está resolviendo un problema de propiedad y cumplimiento que la IA realmente tendrá que enfrentar.
En la historia de la tecnología, la capa que gana rara vez es la más glamorosa.
TCP/IP no era emocionante. AWS S3 tampoco era sexy.
Hasta que todo empezó a funcionar en ellos.
La infraestructura de atribución de datos podría ser la misma. Nadie habla mucho de ello — hasta el día en que la IA no pueda desplegarse legalmente sin ella.
No sé si OpenLedger será el ganador final. Pero estoy bastante seguro de que la verdadera batalla de la economía de la IA se librará en la capa de datos — no en la capa de modelos.
Y por primera vez en años, la carpeta de 'investigación antigua' en mi computadora empieza a parecer más un activo que un montón de archivos olvidados.
$OPEN está alrededor de $0.18. No es consejo financiero. Solo la perspectiva de alguien que acaba de darse cuenta de que años de investigación pueden no haber sido inútiles en absoluto.
