
Al principio, sentí la misma emoción que probablemente sintieron la mayoría. Cada timeline estaba inundado de discusiones sobre agentes autónomos, inteligencia descentralizada, copilotos de IA, inferencia en la cadena, trabajadores sintéticos y predicciones de billones sobre el futuro de la inteligencia artificial. Se sentía imposible ignorarlo.
Lo que más me sorprendió fue lo casual que la gente hablaba de ello.
Hicieron que la IA sonara sin esfuerzo.
Abrir un sitio web.
Conecta tu billetera.
Desplegar un agente.
Ganar recompensas.
Esa fue la expectativa con la que entré.
Genuinamente pensé que participar en la economía de IA se sentiría similar a usar DeFi durante los primeros días: un poco experimental, quizás un poco caótico, pero aún lo suficientemente accesible para que los usuarios normales exploren sin necesitar un título de ingeniería.
Pero cuanto más profundizaba, más desconectado comenzaba a sentirme.
En cuestión de días, me encontré ahogándome en terminología técnica que se sentía completamente ajena.
APIs.
Puntos finales de inferencia.
Pipelines de ajuste fino.
Clústeres de GPU.
Entornos en la nube.
Orquestación de contenedores.
Alojamiento de modelos.
Bases de datos vectoriales.
Adaptadores LoRA.
Cada tutorial asumía que ya entendías todo.

Recuerdo abrir pestañas de documentación una tras otra, esperando que eventualmente algo “clicara”. En cambio, la experiencia se volvió mentalmente agotadora sorprendentemente rápido. Incluso acciones simples parecían enterradas bajo capas de complejidad de infraestructura. La mayoría de los sistemas parecían diseñados para desarrolladores, investigadores o operadores altamente técnicos, no para personas comunes que simplemente tenían curiosidad por participar en el futuro de la IA.
Esa realización se quedó conmigo durante semanas.
Porque a pesar de todo el bombo que rodea a la inteligencia artificial, la IA todavía se siente extrañamente inaccesible.
Hablamos constantemente sobre democratizar la inteligencia, pero la mayoría de las personas aún no pueden contribuir cómodamente a la construcción de sistemas de IA. La barrera no es solo el costo, sino la complejidad. Muchas plataformas alienan involuntariamente a los recién llegados a través de un lenguaje profundamente técnico y herramientas fragmentadas que hacen que la participación se sienta intimidante antes de que siquiera comience.
Esa es parte de la razón por la que OpenLedger captó mi atención.
No porque prometiera alguna revolución mágica de IA de la noche a la mañana, sino porque parecía centrarse en algo más fundamental: infraestructura.
Mientras muchos proyectos persiguen narrativas de IA llamativas y especulación a corto plazo, OpenLedger parece estar construyendo sistemas en torno a la transparencia, atribución, colaboración y accesibilidad: las capas debajo de la IA que la mayoría de la gente rara vez discute, pero que podrían importar más en el futuro.
Una área donde esto se vuelve especialmente interesante es la Fábrica de Modelos de OpenLedger y la infraestructura de OpenLoRA.
A un nivel superficial, estas herramientas están diseñadas para ayudar a los usuarios a entrenar, ajustar, desplegar y alojar modelos de IA dentro de un ecosistema más abierto. Pero lo que me llamó la atención no fue solo la herramienta en sí, sino la filosofía detrás de ella.
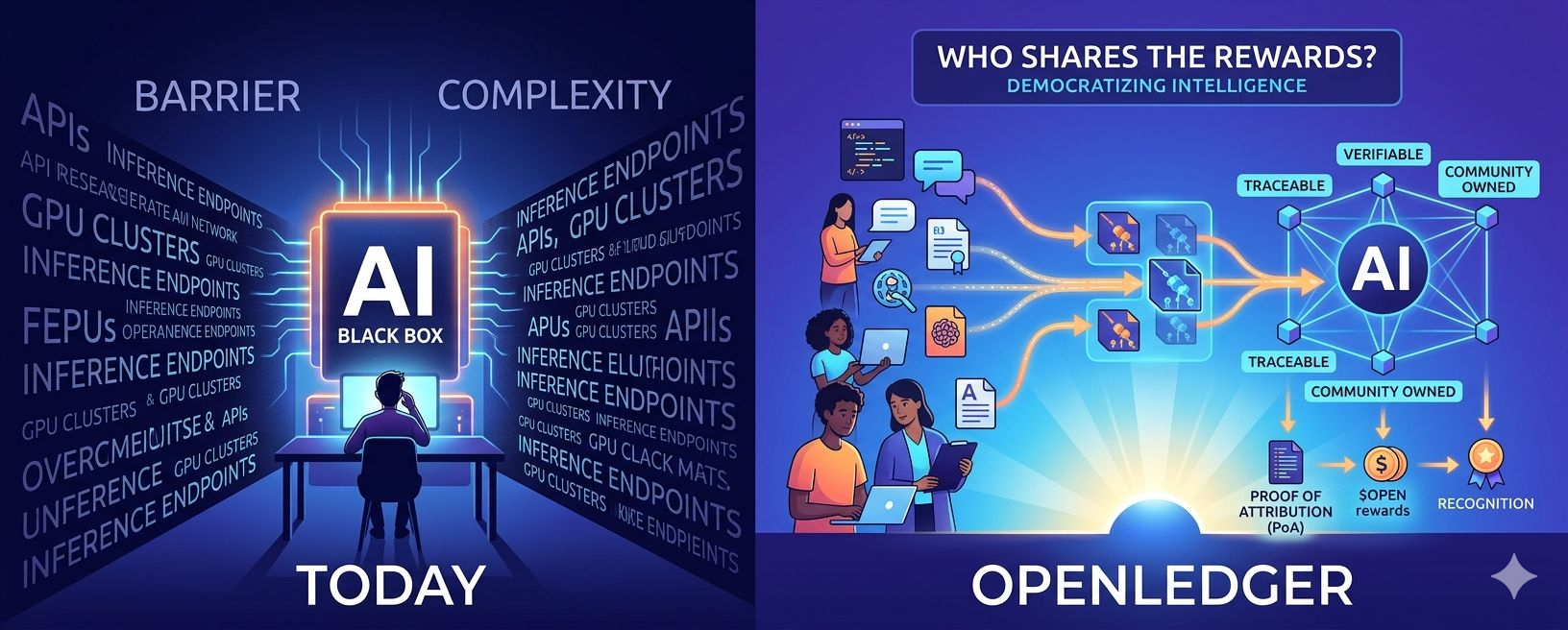
La mayoría de los sistemas de IA hoy operan como cajas negras.
Usas un modelo.
Recibes un resultado.
Pero rara vez sabes de dónde provino la inteligencia, quién la influyó, qué datos la moldearon o cómo se miden las contribuciones.
OpenLedger parece estar abordando este problema de manera diferente.
Su infraestructura de OpenLoRA gira en torno a adaptadores LoRA, que, en términos simples, son capas livianas añadidas a modelos de IA más grandes para especializarlos en tareas específicas sin tener que reentrenar todo el modelo desde cero. Piensa en ello como enseñar a un enorme cerebro de propósito general una habilidad especializada a través de pequeñas actualizaciones modulares.
Lo que importa es que OpenLedger quiere que estas contribuciones se vuelvan verificables y rastreables en la cadena.
Esa idea puede sonar de nicho hoy, pero sospecho que se vuelve cada vez más importante a medida que los sistemas de IA crecen más poderosos e integrados en la vida cotidiana.
Porque eventualmente, la confianza se vuelve ineludible.
Si los sistemas de IA influyen en la educación, la salud, los mercados financieros, los gobiernos, los medios de comunicación, los sistemas legales o las decisiones comerciales, la gente comenzará a hacer preguntas más difíciles:
¿De dónde provino este modelo?
¿Quién lo entrenó?
¿Qué datos moldearon su comportamiento?
¿Quién contribuyó con conocimiento a ello?
¿Se puede verificar realmente todo esto?
Esas preguntas conducen directamente a lo que podría ser el concepto más importante dentro del ecosistema de OpenLedger: Proof of Attribution, o PoA.
Y, honestamente, este fue el momento en que el proyecto comenzó a sentirse menos como otro experimento de cripto-IA y más como una respuesta filosófica temprana a un problema futuro masivo.
Los sistemas de IA modernos se construyen sobre la producción colectiva de la humanidad.
Cada día, miles de millones de personas generan enormes cantidades de conocimiento en línea: conversaciones, artículos, investigaciones, código, opiniones, creatividad, tutoriales, conjuntos de datos, traducciones, reseñas, experiencias emocionales, perspectivas culturales y material educativo.
En muchos sentidos, la IA se entrena sobre la civilización misma.
Sin embargo, una vez que estos sistemas se vuelven rentables, la mayoría de los contribuyentes desaparecen completamente de la ecuación.
Los datos se absorben en sistemas centralizados.
La inteligencia se monetiza.
El valor se concentra hacia arriba.
Y las personas cuyo conocimiento ayudó a dar forma a los modelos a menudo no reciben visibilidad, propiedad ni recompensa.
Ese desequilibrio se siente cada vez más difícil de ignorar.
El Proof of Attribution de OpenLedger intenta abordar esto rastreando cómo las contribuciones de datos influyen en los resultados del modelo y creando mecanismos donde los contribuyentes podrían recibir reconocimiento y recompensas económicas a través del $OPEN ecosistema.
Para ser claros, esto sigue siendo infraestructura en etapa temprana. No es una solución perfecta que resuelva la atribución de la noche a la mañana. Medir la influencia dentro de los sistemas de IA es extraordinariamente difícil. Existen preguntas legítimas sobre la precisión de la verificación, escalabilidad, riesgos de manipulación, marcos regulatorios y desafíos de adopción.
Pero la dirección en sí se siente importante.
Porque la atribución puede convertirse en una de las conversaciones definitorias de toda la economía de IA.
Ahora mismo, la mayoría de las discusiones se centran en construir modelos más grandes. Modelos más rápidos. Modelos más autónomos.
Pero en la próxima década, demostrar de dónde provino la inteligencia puede volverse igualmente valioso.
Y ahí es donde el ecosistema más amplio de OpenLedger comienza a tener más sentido.
Toma Datanets, por ejemplo.
La mayoría de la gente obsesiona con los modelos, pero los datos son la verdadera base debajo de cada sistema inteligente. Incluso la arquitectura más avanzada se vuelve inútil si los datos subyacentes son débiles, sesgados, fragmentados o inaccesibles.
Datanets tiene como objetivo permitir que las comunidades recojan, organicen, limpien y transformen información en conjuntos de datos de alta calidad listos para IA de manera colaborativa.
Eso abre posibilidades fascinantes.
Imagina comunidades de investigación en salud construyendo conjuntos de datos médicos transparentes juntos.
Profesionales legales organizando sistemas de inteligencia legal abiertos.
Analistas financieros curando conjuntos de datos económicos especializados.
Educadores desarrollando archivos educativos multilingües.
Comunidades culturales preservando lenguas y conocimientos regionales para futuros sistemas de IA.
La importancia aquí no es solo técnica.
Es filosófico.
Hoy, muchos sistemas de IA poderosos dependen de conjuntos de datos cerrados controlados por un puñado de corporaciones. Esa concentración crea cuellos de botella en torno al acceso, incentivos, representación y propiedad.
Los conjuntos de datos de propiedad comunitaria podrían eventualmente crear sistemas de IA que se sientan más representativos a nivel global, transparentes y colaborativos.
Y luego está AI Studio, probablemente la parte de OpenLedger con la que los usuarios cotidianos puedan conectar más naturalmente.
AI Studio parece estar diseñado en torno a una idea mucho más simple: bajar la barrera de intimidación.
En lugar de obligar a los usuarios a comprender completamente la infraestructura desde el primer día, proporciona a creadores, emprendedores y desarrolladores un entorno para construir, personalizar, desplegar y potencialmente monetizar agentes de IA con mayor comodidad.
Esa accesibilidad importa más de lo que la mayoría de la gente se da cuenta.
Porque la adopción masiva nunca llega a través de la complejidad.
Cada revolución tecnológica importante eventualmente tiene éxito cuando las personas comunes dejan de tener miedo de participar.
Internet mismo alguna vez se sintió profundamente técnico. Los primeros sitios web requerían configuración manual, conocimiento de línea de comandos y entornos de alojamiento complicados. La mayoría de las personas no podían imaginar usarlo de manera casual.
Entonces, la experiencia del usuario evolucionó.
Las plataformas se volvieron intuitivas.
Las interfaces se volvieron simples.
La complejidad se trasladó al fondo.
Y de repente, miles de millones de personas podían participar sin entender la infraestructura subyacente.
La IA puede seguir un camino similar.
Proyectos como OpenLedger no determinarán el futuro de la inteligencia artificial por sí solos. Habrá fracasos, rediseños, batallas regulatorias, presiones económicas y numerosos experimentos que nunca funcionarán completamente.
Pero la dirección más amplia aún se siente significativa.
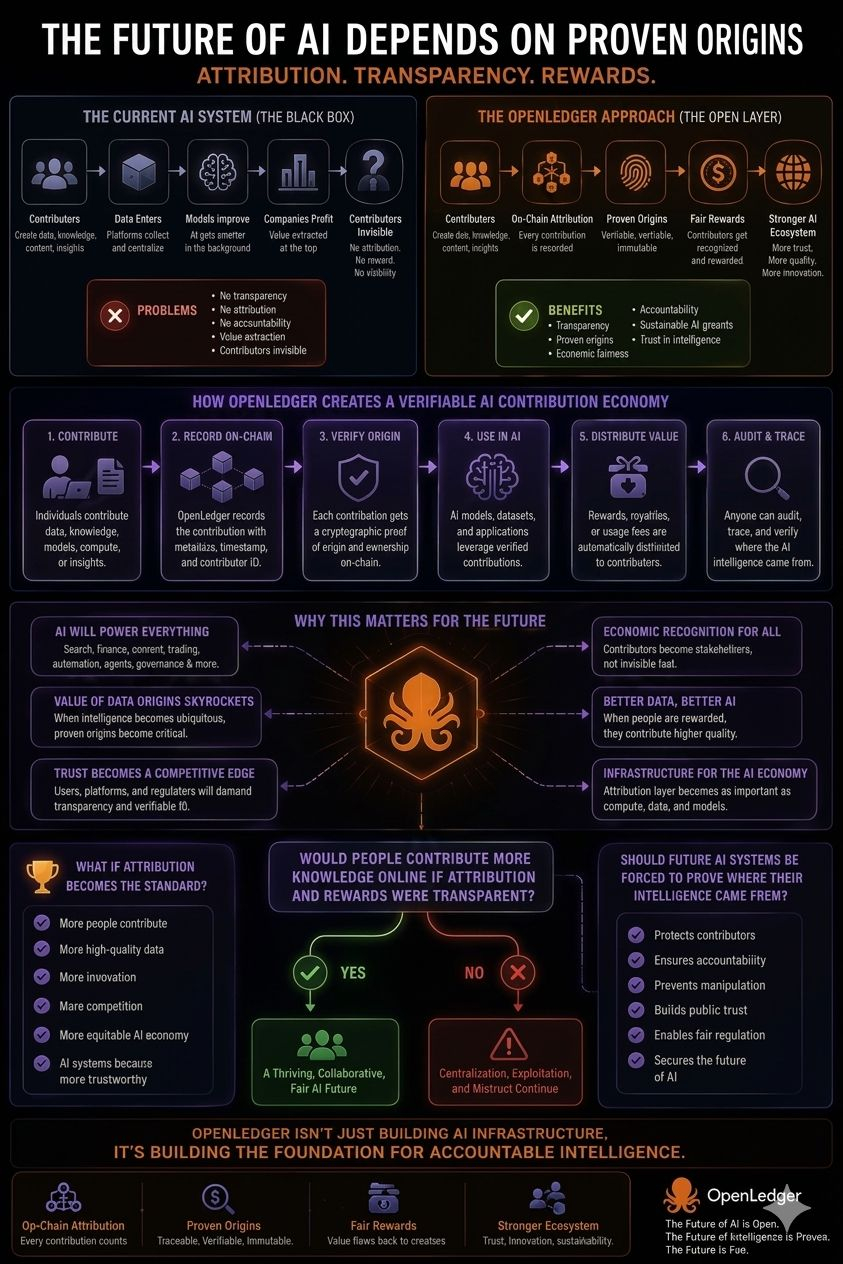
Porque la conversación se está alejando lentamente del rendimiento puro del modelo y hacia preguntas más profundas sobre propiedad, transparencia, atribución, accesibilidad y contribución colectiva.
Y quizás ese cambio es necesario.
La inteligencia artificial podría eventualmente convertirse en uno de los sistemas económicos más grandes que la humanidad haya creado. Si eso sucede, la estructura subyacente importará enormemente.
¿Quién posee la inteligencia?
¿Quién se beneficia de ello?
¿Quién recibe reconocimiento?
¿Quién queda excluido?
Esas preguntas ya no son teóricas.
Si la IA se entrena en el conocimiento, creatividad, trabajo y cultura colectiva de la humanidad, entonces quizás las recompensas no deberían permanecer centralizadas de forma permanente dentro de un pequeño grupo de corporaciones o instituciones.
Quizás la economía de IA del futuro necesite una infraestructura que recuerde de dónde provino la inteligencia.
No perfectamente.
No inmediatamente.
Pero al menos intencionalmente.
Por eso OpenLedger se siente interesante de observar.
No porque afirme haber resuelto la IA.
Pero porque está preguntando una de las preguntas más importantes que la industria podría enfrentar eventualmente:
Si la inteligencia se construye colectivamente, ¿debería la propiedad seguir siendo colectiva también?
