
Por qué los sistemas de agentes confiables dependen de datos estructurados, memoria controlada y ejecución verificable
Por Maheen Sajjad, Jefa de Tecnología en Inflectiv
La mayoría de las demos de agentes de IA siguen el mismo patrón.
Conecta un modelo a algunas herramientas. Agrega recuperación. Dale acceso a documentos o a una base de datos. Escribe un buen prompt de sistema. Pídele que complete una tarea. El agente llama a una herramienta, encuentra algo de contexto, genera una respuesta y la demo se ve impresionante.
Ahí es donde muchos equipos reciben la señal equivocada.
Una demo que funciona no significa que el sistema esté listo para producción. Solo significa que el camino feliz funcionó una vez.
La producción es diferente. En producción, el agente debe funcionar incluso cuando los datos están incompletos, duplicados, desactualizados, son privados, tienen un formato deficiente o están distribuidos en múltiples sistemas. Debe saber cuándo no responder. Debe preservar el contexto de origen. Debe respetar los permisos. Debe evitar la filtración de credenciales. Debe actualizar el conocimiento sin corromper el conjunto de datos subyacente. Debe crear registros que los equipos de ingeniería puedan consultar cuando algo falla.
Eso no es un problema de indicaciones.
Ese es un problema de infraestructura.
La siguiente fase importante del desarrollo de agentes no se definirá por quién pueda conectar más herramientas, sino por quién pueda crear agentes lo suficientemente fiables como para operar con datos reales, permisos reales y flujos de trabajo reales.
MCP es una capa de transporte, no una capa de confiabilidad.
El Protocolo de Contexto de Modelo (MCP) es uno de los cambios más importantes en la infraestructura de agentes, ya que estandariza la forma en que los sistemas de IA se conectan a herramientas y fuentes de datos externas. En lugar de que cada equipo desarrolle integraciones personalizadas para cada modelo, base de datos, sistema de archivos, aplicación y flujo de trabajo, el MCP proporciona a los desarrolladores una interfaz común.
Eso importa.
Google MCP Toolbox para bases de datos es un buen ejemplo de hacia dónde se dirige el ecosistema. Proporciona a los desarrolladores un servidor MCP de código abierto para conectar agentes, IDE y aplicaciones a bases de datos empresariales. Este es el camino correcto, ya que los agentes necesitan una forma estandarizada de acceder a los sistemas donde se realiza el trabajo.
Pero desde el punto de vista de la ingeniería, es importante ser preciso.

https://www.anthropic.com/news/model-context-protocol
MCP otorga acceso a los agentes. No garantiza la corrección. No estructura datos desordenados. No resuelve el problema de la procedencia. No aplica el principio de mínimo privilegio por defecto. No hace que los resultados de las herramientas sean confiables. No decide si se debe permitir que un agente realice una acción.
MCP es un límite de protocolo. No es un límite de confianza.
Esa distinción es importante porque, una vez que una herramienta está disponible para un agente, este puede canalizar decisiones a través de ella. Si la herramienta tiene permisos amplios, el agente podría extralimitarse. Si la herramienta oculta efectos secundarios, el sistema se vuelve más difícil de depurar. Si el contexto está mal estructurado, el modelo aún puede generar una respuesta fiable a partir de evidencia débil.
Las revelaciones de diciembre de 2025 sobre más de 30 vulnerabilidades en herramientas de codificación de IA hicieron que ignorar esa distinción resultara muy costoso. La exfiltración de credenciales mediante inyección directa, el acceso no controlado a herramientas y los efectos secundarios silenciosos comenzaron en la capa de transporte y terminaron en un punto aún peor.
Un agente conectado no es automáticamente un agente fiable.
Los modos de fallo reales se encuentran debajo de la indicación.
Cuando los sistemas de agentes fallan en producción, el fallo suele aparecer en la respuesta. Pero la causa a menudo se encuentra mucho más abajo en la pila.
El documento se fragmentó incorrectamente. Se perdieron los metadatos de origen. La misma entidad apareció con tres nombres diferentes. El índice de incrustación estaba obsoleto. El modelo de permisos se aplanó. El agente recuperó un texto similar en lugar del registro correcto. La herramienta devolvió un resultado parcial sin indicarlo. La capa de memoria almacenó una conclusión sin la evidencia que la respalda. El flujo de trabajo permitió una operación de escritura sin validación.
Estos no son casos excepcionales. Son condiciones normales de producción.
El método RAG tradicional suele tratar el conocimiento como estático. Se cargan archivos, se dividen en fragmentos, se crean incrustaciones, se recuperan los pasajes más similares y se incorporan al modelo. Esto puede funcionar para preguntas y respuestas sencillas, pero se vuelve frágil cuando los agentes necesitan realizar tareas complejas, actualizar el conocimiento, citar fuentes, gestionar permisos y operar en contextos empresariales cambiantes.
La similitud no es lo mismo que la exactitud.
Un fragmento de alto rango puede estar desactualizado. Un pasaje semánticamente similar puede referirse a un cliente, contrato, política, versión de producto, región o período de tiempo incorrecto. Un documento puede contener la respuesta correcta, pero carecer de los metadatos necesarios para determinar si el agente tiene autorización para utilizarla.
Por eso, los agentes de producción necesitan datos estructurados, no solo texto recuperado.
Los datos estructurados no son solo un almacenamiento más limpio.
Cuando hablamos de conjuntos de datos estructurados en Inflectiv, no nos referimos a forzar que cada documento se ajuste a una tabla rígida.
Los datos estructurados implican que el agente puede trabajar con información que tiene una forma utilizable.
Esto incluye referencias de origen, metadatos de documentos, entidades extraídas, marcas de tiempo, permisos, relaciones, índices semánticos, historial de actualizaciones y suficiente contexto para saber de dónde proviene la respuesta. Significa que el conjunto de datos admite tanto la recuperación semántica como el filtrado determinista. Significa que un sistema puede distinguir entre «este texto parece relevante» y «este registro es el correcto para este usuario, esta tarea y este ámbito de permisos».
Esa es la diferencia entre un volcado de conocimiento y un conjunto de datos listo para ser utilizado por un agente.
Una capa de datos de producción debería responder a preguntas como:
¿De qué fuente proviene esta respuesta?
¿Cuándo se actualizó por última vez?
¿Quién puede acceder a él?
¿Qué agente lo utilizó?
¿Se recuperó esta información mediante similitud semántica, filtro de metadatos o referencia directa?
¿Puede otro agente reutilizar el mismo contexto de forma segura?
¿Es posible añadir nueva información sin alterar el conocimiento existente?
Si el sistema no puede responder a esas preguntas, el agente está operando en un contexto frágil.
Por eso, la capa de datos cobra mayor importancia a medida que los agentes se vuelven más capaces. Cuanto más puede hacer un agente, más importante resulta saber con exactitud sobre qué está actuando.
La recuperación de datos requiere más que incrustaciones.
Muchos equipos aún tratan la recuperación como un problema de incrustación. Mejores fragmentos, mejores vectores, mejor búsqueda de similitud.
Esas cosas importan, pero no son suficientes.
La recuperación fiable suele requerir un enfoque por capas. Los filtros de metadatos deben acotar el espacio de búsqueda antes de la clasificación semántica. Los permisos de origen deben aplicarse antes de que el contexto llegue al modelo. La resolución de entidades debe reducir la ambigüedad. El control de versiones debe evitar que los registros obsoletos se traten como actuales. Los umbrales de confianza deben determinar cuándo el agente debe responder, escalar el problema o solicitar más contexto.
En otras palabras, la recuperación necesita un flujo de control.
Por ejemplo, un agente que responde a una pregunta de cumplimiento no debería simplemente recuperar el párrafo de política más similar. Debería conocer la jurisdicción, la fecha de entrada en vigor, la versión del documento, el nivel de acceso y si la política ha sido reemplazada. Un agente de soporte no debería recuperar una solución alternativa de un ticket antiguo a menos que sepa que la versión del producto aún coincide. Un agente de investigación no debería combinar dos fuentes a menos que pueda preservar la atribución y detectar conflictos.
Aquí es donde fallan muchos productos basados en agentes. Optimizan para que "el modelo haya producido una respuesta", no para que "el sistema haya recuperado la evidencia correcta bajo las restricciones correctas".
Para los agentes de producción, la recuperación debería comportarse menos como una búsqueda y más como una canalización de acceso a datos controlada.
La escritura diferida es un problema de mutación.
El cambio más importante en la arquitectura de los agentes no es solo que los agentes puedan leer más contexto.
Es que los agentes pueden crear nuevos conocimientos.
Cada interacción útil entre agentes genera información. Un agente de soporte descubre que una solución alternativa resolvió un problema recurrente. Un agente de investigación encuentra una nueva fuente que modifica la conclusión. Un agente de ventas se entera de que un cliente potencial tiene una nueva prioridad. Un agente de seguridad identifica un patrón de vulnerabilidad recurrente. Un agente técnico descubre que una suposición anterior era errónea.
Si esa información desaparece después de la ejecución, el sistema no aprende.
Pero escribir de nuevo en un conjunto de datos no es tan sencillo como permitir que el agente edite la memoria.
La escritura diferida es un problema de mutación.
Una capa de escritura diferida en producción necesita reglas. ¿Qué puede escribir el agente? ¿Dónde se guarda la nueva información? ¿Se añade, se fusiona o se reemplaza alguna? ¿Requiere revisión humana? ¿Qué fuente la respalda? ¿Qué campos puede actualizar el agente? ¿Qué sucede si otro agente escribe información contradictoria? ¿Se puede revertir el cambio?
Sin esos controles, la memoria del agente se convierte en otra fuente de ruido.
El patrón más seguro no es "dejar que el agente actualice la verdad". El patrón más seguro es tratar la escritura diferida como una canalización controlada: proponer, validar, atribuir, almacenar y auditar.
Así es como la memoria se convierte en una infraestructura útil en lugar de una transcripción desordenada.
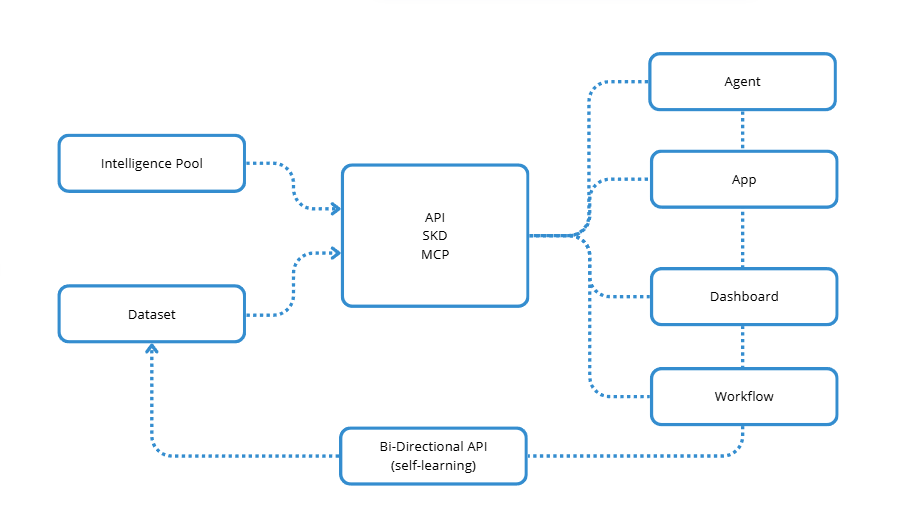
La API de autoaprendizaje de Inflectiv trata la escritura diferida como una canalización controlada: proponer, validar, atribuir, almacenar, auditar.
La memoria debe estar estructurada, no solo ser extensa.
Las ventanas de contexto más largas son útiles, pero no solucionan el problema de la memoria.
Una ventana de contexto amplia permite que un modelo examine más información durante una sola ejecución. No crea conocimiento persistente automáticamente. No organiza lo aprendido. No aplica permisos. No registra el historial de origen. No decide qué se debe recordar, actualizar u olvidar.
La memoria de producción necesita estructura.
Los agentes no deberían reiniciarse desde cero cada vez. Pero tampoco deberían llevar memoria ilimitada y no verificada a cada flujo de trabajo.
La capa intermedia útil es la memoria estructurada: persistente, consultable, con atributos, con ámbito definido y auditable.
Ahí es donde los agentes comienzan a combinarse.
El acceso a las herramientas crea una superficie de ataque.
Cuanto más útil se vuelve un agente, más peligroso resulta un acceso descuidado.
Cuando un agente puede leer archivos, llamar a API, consultar bases de datos, usar credenciales, escribir en sistemas o activar flujos de trabajo, ya no se limita a generar texto. Está operando con autoridad delegada.
Eso requiere un modelo de seguridad diferente.
Una aplicación tradicional suele tener usuarios, roles, rutas y permisos definidos. Los agentes son diferentes porque deciden qué herramienta usar según el contexto. Pueden combinar herramientas de formas que el desarrollador no previó explícitamente. Pueden recibir instrucciones maliciosas a través de datos. Pueden exponer información confidencial mediante registros o salidas. Pueden heredar permisos locales amplios del entorno en el que se ejecutan.
Esto genera varios riesgos:
Herramientas con permisos excesivos
Credenciales filtradas
Memoria sin ámbito
Inyección inmediata a través de los datos recuperados
Llamadas a herramientas no registradas
Propiedad poco clara de las acciones
Escrituras inseguras en sistemas posteriores
Por eso, el acceso de los agentes no puede considerarse algo secundario.
La pregunta correcta no es solo "¿puede el agente llamar a esta herramienta?".
La pregunta más pertinente es: "¿bajo qué política, con qué credenciales, para qué sesión, con qué registro de auditoría y con qué vía de revocación?"
AVP hace que el acceso sea exigible
Este es el motivo por el que lanzamos el Protocolo de Bóveda de Agentes (AVP).
AVP está diseñado en torno a un principio básico: los agentes deben poder utilizar funcionalidades sensibles sin poseerlas ni exponerlas libremente.
AgentVault es la implementación de referencia de AVP. Proporciona a los desarrolladores una bóveda cifrada local, perfiles de acceso con ámbito definido, enmascaramiento de credenciales, registros de auditoría, controles de sesión, revocación, caducidad TTL y un servidor MCP para secretos y memoria.
Desde el punto de vista de la ingeniería, lo importante no es la lista de características, sino el modelo de control.
El agente no necesita ver el secreto en bruto para usar una herramienta. Una sesión debe caducar. Una credencial debe tener un alcance definido. Una acción denegada debe registrarse. Una operación en memoria debe tener límites. Un equipo debe poder revocar el acceso sin rediseñar todo el flujo de trabajo.
Así es como los sistemas de agentes pasan de "el modelo puede hacer cosas" a "el sistema puede permitir de forma segura que el modelo haga cosas".
Para la producción, esa diferencia lo es todo.
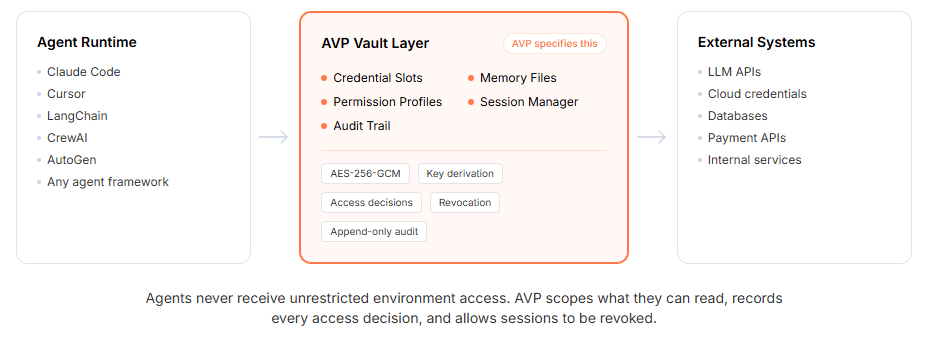
Fuente: https://agentvaultprotocol.org/
El almacenamiento verificable pasa a formar parte del plano de datos.
Existe otro problema que cobra mayor importancia a medida que los agentes dependen de los conjuntos de datos: dónde se almacenan los datos y cómo sabemos que no han cambiado inesperadamente.
Si un agente utiliza un conjunto de datos para tomar decisiones, el sistema debe poder rastrear esos datos. Debe saber dónde se almacenó la fuente, si el contenido cambió y si otro flujo de trabajo puede verificarlo posteriormente. Esto es fundamental para la auditabilidad, la reproducibilidad y la confianza entre sistemas.
Por eso, el almacenamiento verificable forma parte de la arquitectura.
Inflectiv utiliza Walrus como capa de almacenamiento verificable para los datos de los agentes. El estudio de caso de Walrus reporta más de 7000 conjuntos de datos almacenados en Walrus y una reducción de costos del 60 % en comparación con AWS S3. Más importante aún para el equipo de ingeniería, Walrus proporciona a la capa de datos una relación más sólida entre almacenamiento, trazabilidad y verificación.
Esto es importante porque los sistemas de agentes no deberían depender de objetos invisibles.
Si la respuesta de un agente cita un conjunto de datos, este debe ser rastreable. Si un flujo de trabajo depende de una fuente, esta debe ser verificable. Si un conjunto de datos alimenta a varios agentes, la capa de almacenamiento debe garantizar que los datos subyacentes no se hayan modificado silenciosamente.
En los sistemas de producción, la procedencia no es un lujo, sino una necesidad.
Forma parte del plano de datos.
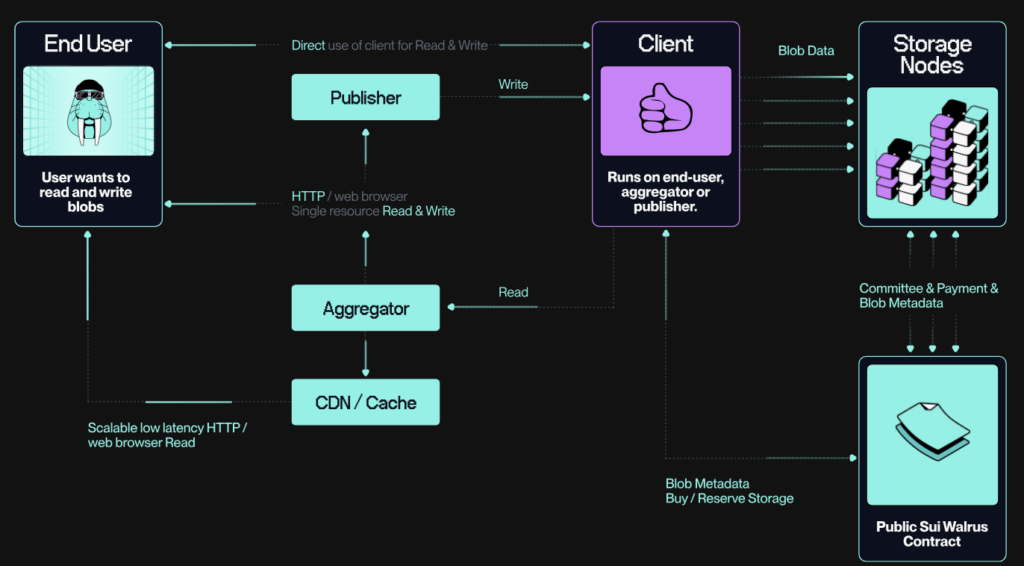
Fuente: Protocolo de la Morsa
La observabilidad es lo que hace que los agentes sean depurables.
Una de las partes más difíciles de la ingeniería de agentes es la depuración.
Cuando una aplicación normal falla, los ingenieros suelen poder inspeccionar los registros, los rastros, las consultas a la base de datos, las respuestas de la API y los cambios de estado. Los sistemas de agentes añaden mayor incertidumbre. El modelo puede elegir rutas diferentes. La recuperación puede devolver un contexto distinto. Las llamadas a las herramientas pueden depender del razonamiento generado. La memoria puede afectar a los resultados futuros. Los datos externos pueden cambiar entre ejecuciones.
Sin capacidad de observación, los equipos terminan depurando capturas de pantalla.
Eso no es aceptable para la producción.
Los sistemas de agentes necesitan registros que muestren qué se recuperó, qué herramienta se llamó, qué credencial se usó, qué política permitió la acción, qué memoria se leyó o escribió, qué fuente respaldó la respuesta y qué cambió después de la ejecución.
Esto no es solo por seguridad. Es por fiabilidad.
Si un agente da una respuesta incorrecta, el equipo necesita saber si el fallo se debió a la recuperación de datos, los datos de origen, la salida de la herramienta, los permisos, la lógica de las indicaciones, la memoria o el propio modelo. Sin esa distinción, cada fallo parecerá un error de la IA.
Una buena arquitectura permite diagnosticar los fallos.
Eso es lo que requiere la producción.
La pila de agentes necesita invariantes claras.
Cuanto más desarrollamos en Inflectiv, más evidente se vuelve un principio: los agentes fiables necesitan invariantes del sistema.
Un modelo puede ser probabilístico. La infraestructura que lo rodea no puede ser vaga.
Un conjunto de datos debe conocer sus fuentes.
Una capa de recuperación debe aplicar permisos.
Se debe atribuir una reescritura.
Se debe definir el alcance de una credencial.
Una sesión debería expirar.
Se debe registrar la llamada a la herramienta.
Una actualización de memoria debería ser auditable.
La fuente debe ser verificable.
Estas son las reglas que hacen que los sistemas de agentes sean fiables.
Aquí es donde la arquitectura de Inflectiv cobra sentido. Los conjuntos de datos estructurados hacen que el conocimiento sea útil. MCP hace que esa información sea accesible dentro de los flujos de trabajo de los desarrolladores. AVP y AgentVault permiten controlar el acceso. Walrus hace que el almacenamiento sea más verificable. La escritura diferida hace que la información se acumule en lugar de desaparecer después de cada ejecución.
Ninguna de esas capas reemplaza al modelo.
Hacen que el modelo sea útil en la producción.
Los agentes confiables comienzan con la capa de datos.
La primera oleada de agentes premió a los equipos que lograron realizar demostraciones impresionantes.
La próxima oleada premiará a los equipos que sean capaces de crear sistemas fiables.
Eso significa centrarse menos en trucos para generar indicaciones y centrarse más en la arquitectura de datos, el diseño de la memoria, los permisos, la procedencia, la observabilidad y la ejecución controlada.
Seguirán apareciendo mejores modelos. Las ventanas de contexto más grandes serán de ayuda. Se expondrán más herramientas a través de MCP. Pero nada de eso elimina la necesidad de una capa de datos estructurados debajo del agente.
Los agentes de producción necesitan algo más que acceso a herramientas.
Necesitan una infraestructura que haga que su trabajo sea fiable, inspeccionable y seguro.
Eso comienza con la capa de datos.
Empiece a estructurar su primer conjunto de datos en app.inflectiv.ai, o conecte Inflectiv directamente dentro de su IDE con el servidor Inflectiv MCP.
Lecturas adicionales
Antrópico: Presentación del Protocolo de Contexto Modelo
Google: MCP Toolbox para bases de datos
AgentVault
Estudio de caso de Walrus × Inflectiv
Aplicación inflectiva
Acerca del autor
Maheen Sajjad es la Directora de Tecnología de Inflectiv, donde supervisa la ingeniería, los sistemas de backend, la IA/RAG y la entrega de la plataforma. Cuenta con más de cuatro años de experiencia en la creación y escalado de plataformas en ecosistemas Web3, de IA y de software. Maheen se especializa en transformar ideas iniciales en productos técnicos estructurados, lanzar MVPs multifuncionales y alinear equipos técnicos, de diseño y de negocio para cumplir con plazos ajustados. Su trabajo abarca economías de tokens, integraciones de IA, implementaciones multiplataforma y sistemas de productos diseñados para una adopción real.