La mayor parte del tiempo, se habla de la IA desde el lado del usuario.
¿Qué puede escribir?
¿Qué puede responder?
¿Qué tan rápido es?
¿Cuánto más barato hace una tarea?
Eso es comprensible. El usuario ve el resultado primero. Una respuesta clara, una imagen generada, un informe terminado, un agente en funcionamiento. Todo se siente como la puerta principal de la IA.
Pero hay otro lado que se siente menos visible.
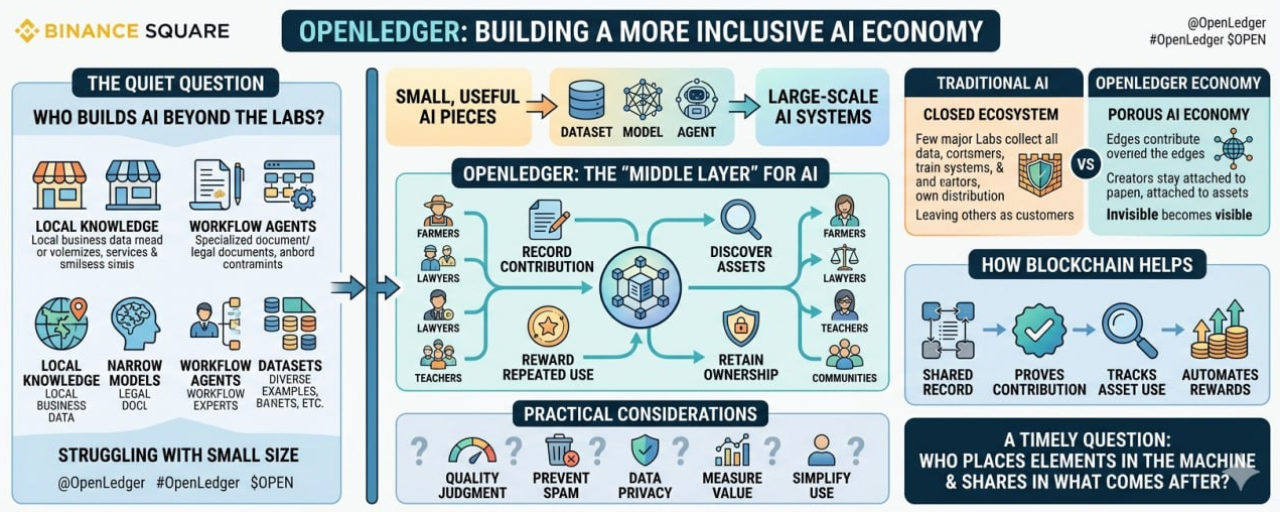
¿Quién se encarga de suministrar las piezas detrás de esto?
Esa pregunta importa más de lo que parece a simple vista.
OpenLedger se puede ver desde este ángulo. No solo como una blockchain de IA, y no solo como un sistema para monetizar datos, modelos y agentes. Más bien como una posible apertura para personas que no están dentro de las compañías de IA más grandes, pero que aún tienen algo útil que aportar.
Porque la IA útil no siempre comienza en grandes laboratorios.
A veces comienza con un pequeño conjunto de datos que solo un negocio local entiende. A veces es un modelo estrecho entrenado en torno a un tipo de documento. A veces es un agente construido por alguien que conoce un flujo de trabajo profundamente porque ha hecho ese trabajo durante años. A veces es una colección de ejemplos, etiquetas, correcciones o patrones que parecerían ordinarios para los forasteros, pero que se vuelven valiosos en el contexto adecuado.
El problema es que estas piezas a menudo no tienen un camino claro hacia la economía de IA más amplia.
Son demasiado pequeños para convertirse en plataformas.
Demasiado específico para atraer la atención general.
Demasiado valioso para regalar.
Demasiado difícil de valorar.
Demasiado difícil de rastrear una vez que alguien más los utiliza.
Así que se sientan en medio.
No es inútil. Tampoco está completamente activo.
Ese espacio intermedio es donde OpenLedger comienza a sentirse relevante.
Parece que se está preguntando si los datos, modelos y agentes pueden comportarse más como activos utilizables sin necesidad de ser absorbidos por una gran empresa. ¿Puede un pequeño equipo hacer que un conjunto de datos esté disponible sin perder el control sobre él? ¿Puede un creador de modelos ganar dinero por el uso repetido en lugar de vender el modelo una sola vez? ¿Puede un agente convertirse en parte de una red de trabajo más grande, en lugar de quedarse atrapado dentro de un producto?
Estas no son preguntas estruendosas, pero son importantes.
Porque la IA podría fácilmente convertirse en otra economía cerrada.
Unas pocas empresas recopilan la mayor cantidad de datos, entrenan los sistemas más fuertes, poseen la distribución y deciden qué herramientas se utilizan. Todos los demás se convierten en clientes o proveedores con poco poder de negociación. Ese camino es familiar. Lo hemos visto con la búsqueda, plataformas sociales, tiendas de aplicaciones, servicios en la nube y plataformas para creadores.
El patrón no siempre es intencional. Simplemente sucede cuando falta la capa intermedia.
OpenLedger parece estar trabajando en esa capa intermedia.
Un lugar donde se pueden registrar, descubrir y recompensar los insumos de IA. Un lugar donde la propiedad no tiene que desaparecer en el momento en que un activo se vuelve útil. Un lugar donde los contribuyentes más pequeños podrían tener alguna forma de mantenerse conectados a lo que crearon.
Eso no significa que todo se vuelva igual. No significa que los pequeños contribuyentes de repente compitan con grandes laboratorios. Eso sería demasiado ordenado y probablemente no cierto.
Pero puede que cambie un poco las condiciones.
En lugar de necesitar construir una empresa de IA completa, alguien podría contribuir con una capa útil. En lugar de necesitar poseer toda la aplicación, podrían proporcionar el conjunto de datos o el modelo que la mejora. En lugar de ser invisibles en el fondo, su activo podría tener un registro de uso.
Esa es una forma de participación más silenciosa.
Y tal vez eso es lo que lo hace interesante.
La IA se está volviendo demasiado amplia para un solo tipo de constructor. Los mejores sistemas pueden necesitar expertos en dominios, propietarios de datos, creadores de modelos, desarrolladores de agentes, evaluadores y constructores de aplicaciones. No todos se parecerán a los fundadores de software tradicionales. Algunos pueden simplemente tener conocimientos que aún no se han convertido en un producto.
El papel de OpenLedger, si funciona, es facilitar la activación de ese conocimiento.
La palabra “monetizar” puede sonar fría, pero debajo de eso hay un tema más humano. La gente quiere saber que si su trabajo mejora algo, no son completamente borrados de la cadena de valor. El conjunto de datos de cultivos de un agricultor, los patrones documentales de un abogado, el material de aprendizaje de un profesor, los ejemplos de una comunidad de lengua local: estas cosas pueden entrenar y mejorar los sistemas de IA. Pero sin estructura, también pueden desaparecer en ellos.
Esa es la parte incómoda.
La IA necesita insumos. Siempre los ha necesitado. La pregunta es si esos insumos se tratan como combustible desechable o como activos con una identidad continua.
OpenLedger parece inclinarse hacia la segunda visión.
La blockchain ayuda porque puede mantener un registro compartido. No cada registro resuelve un problema. No cada token crea valor. Pero en una red donde participan muchos contribuyentes independientes, un registro común puede reducir la confusión. Puede mostrar quién contribuyó con qué, cómo se utilizó y hacia dónde deberían fluir las recompensas.
Aun así, esto no será fácil.
Hay preguntas prácticas en todas partes. ¿Cómo juzgas la calidad de un conjunto de datos? ¿Cómo evitas que activos de bajo esfuerzo inunden la red? ¿Cómo proteges la información privada? ¿Cómo mides si un modelo o agente realmente agregó valor? ¿Cómo haces que el sistema sea lo suficientemente simple para que los contribuyentes no técnicos puedan usarlo?
Esas preguntas pueden decidir más que la idea misma.
Porque la participación solo se expande cuando el proceso se siente comprensible. Si OpenLedger es demasiado complejo, corre el riesgo de volverse útil solo para el mismo grupo técnico que ya sabe cómo navegar estos sistemas. Pero si se vuelve lo suficientemente simple, podría abrir la puerta a un grupo más amplio de contribuyentes.
Esa es la perspectiva que vale la pena explorar.
OpenLedger no se trata solo de que la IA se vuelva más poderosa. Se trata de si la economía de IA puede volverse más porosa. Si piezas útiles pueden entrar desde los bordes. Si los creadores más pequeños de datos, modelos y agentes pueden tener un lugar antes de que todo se reúna en unos pocos grandes sistemas.
Nadie sabe aún hasta dónde puede llegar eso.
Pero la pregunta en sí se siente oportuna.
A medida que la IA sigue creciendo, no solo importará lo que las máquinas puedan hacer. También importará quién logra colocar algo dentro de la máquina, mantener un rastro de ello y compartir lo que venga después.