
He estado pensando en esto últimamente. En el mundo cripto, hablamos sin parar sobre la liquidez — para el dinero, para los tokens, para los NFTs, incluso para el cómputo a veces. Pero, ¿qué pasa con la materia prima que impulsa todo en la IA en este momento? Los datos. Se siente como si todavía los estuviéramos tratando como un recurso infinito y gratuito que realmente nadie posee o por el que se paga adecuadamente.
Me detengo y pienso aquí... la mayor parte del valor en la IA moderna no está en los modelos llamativos que todos promocionan. Está en los datasets que los entrenan. Sin embargo, esos datasets están encerrados en silos corporativos, recopilados sin compensación, o acaparados. Las personas y comunidades que crean lo bueno rara vez ven un beneficio significativo. Eso se siente roto.
El problema oculto
Aquí está la cosa que me sigue molestando. Desbloqueamos liquidez para el dinero con Bitcoin. Desbloqueamos liquidez programable para aplicaciones con Ethereum. Pero la inteligencia — el conocimiento real y los patrones codificados en los datos — sigue siendo mayormente ilíquida. Es difícil de comerciar, difícil de atribuir, y casi imposible recibir un pago justo cuando alguien más construye sobre ello.
Esto crea distorsiones extrañas. Las grandes empresas tecnológicas se enriquecen con la producción colectiva humana mientras que los contribuyentes reciben migajas o nada. Los datos de calidad se vuelven escasos porque, ¿por qué molestarse en compartir si no capturas el valor? Y a medida que los agentes y modelos de IA se multiplican, este problema solo escala.
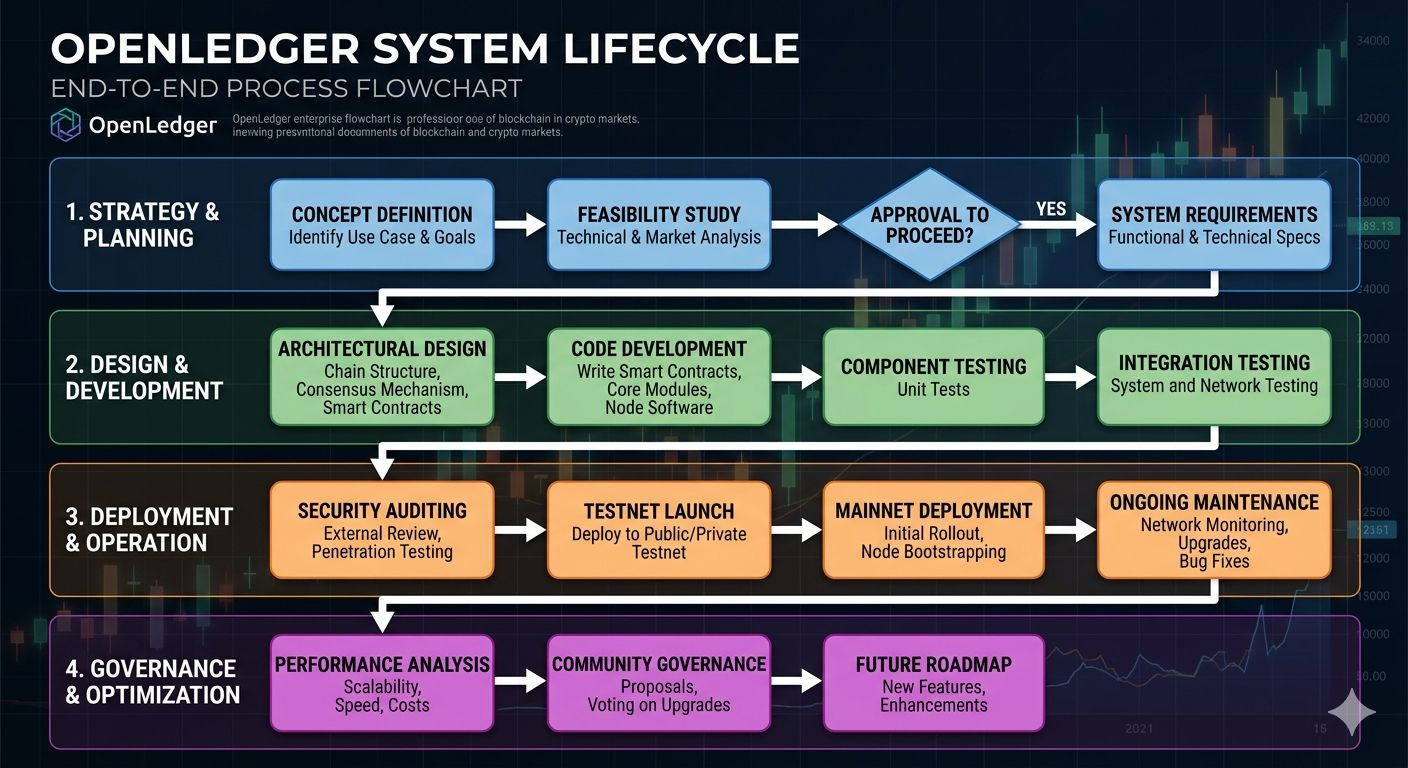
No estoy completamente convencido aún de que la blockchain lo solucione todo mágicamente, pero la magnitud del problema es real. Las estimaciones que he visto flotando ponen el “problema de datos” en IA en el rango de cientos de miles de millones. Eso no es pequeño.
Desglosándolo
Hagámoslo más simple. Los datos hoy son como la tierra antes de tener derechos de propiedad claros. La gente los usa, pelea por ellos, pero la propiedad es difusa y la aplicación es desordenada. Tienes:
Contribución sin recompensa: Alguien sube datos especializados de alta calidad. Un modelo se entrena con ellos. La persona original no ve ningún beneficio continuo.
Caja negra de procedencia: Cuando un modelo genera algo útil (o dañino), buena suerte rastreando quién proporcionó qué.
Problemas de composabilidad: ¿Quieres combinar conjuntos de datos o afinar modelos creativamente? Buena suerte con los dolores de cabeza legales, técnicos y de pago.
Los humanos y los sistemas manuales fallan aquí porque la confianza es cara, el seguimiento es tedioso y los incentivos no se alinean a escala de internet. No puedes pagar de manera realista a cada contribuyente manualmente a través de miles de usos. Las plataformas centrales lo intentan, pero se llevan grandes cortes y las decisiones se vuelven políticas.

Aquí es donde las cosas se ponen interesantes.
OpenLedger como un intento
OpenLedger (el proyecto de token OPEN) está tratando de tratar los conjuntos de datos como activos productivos y monetizables en cadena. Lo llaman la “Blockchain de IA.” La idea central: hacer que los datos sean líquidos como otros primitivos de crypto.
En lugar de archivos estáticos, obtienes conjuntos de datos tokenizados a través de cosas como Datanets — colecciones de propiedad comunitaria donde la gente contribuye, valida y curates datos juntos. Cuando esos datos se utilizan en entrenamiento o inferencia, los contribuyentes pueden ganar regalías o recompensas a través de su sistema de Prueba de Atribución. Staking de datos, mercados de conjuntos de datos, rendimiento continuo por uso — esa es la visión.
Datos como capital generador de rendimiento. No solo una venta única, sino algo que sigue produciendo valor para sus creadores a medida que los modelos y agentes los usan. El $OPEN token está en el medio: gas para transacciones, staking para seguridad y agentes, pagos entre datos/modelos/agentes.
Me recuerda a esa comparación que la gente hace:
Bitcoin → liquidez para almacenamiento de dinero/valor
Ethereum → liquidez para aplicaciones/contratos inteligentes
OpenLedger → liquidez para inteligencia/datos
Me gusta la narrativa. Se siente como un próximo primitivo natural si funciona.
Pero, ¿es realista?
Aquí está mi escepticismo. Convertir datos en activos realmente líquidos que generen regalías suena limpio en papel, pero la ejecución es desordenada. ¿Cómo previenes que datos basura inunden por recompensas? ¿Cómo verificas la calidad a gran escala sin crear nuevos puntos centrales de control? ¿Y pagará suficiente gente por datos en cadena cuando existen alternativas más baratas (o gratuitas) en otros lugares?
Los desbloqueos de tokens están llegando — las porciones del equipo e inversores comenzarán a liberarse más tarde en 2026. Eso podría crear presión de venta si la adopción no supera eso. La capitalización de mercado está relativamente baja en este momento (alrededor de $40M con un precio cerca de $0.18), lo que da margen para crecer pero también señala que el mercado aún no está completamente comprometido.
Por el lado positivo, si logran una atribución verificable y mercados reales para conjuntos de datos, podría cambiar la forma en que funciona el desarrollo de IA. Imagina expertos de nicho en medicina o ingeniería recibiendo pagos continuos por su conocimiento en el dominio alimentando modelos especializados. O comunidades que posean sus propias economías de datos en lugar de alimentar a las grandes tecnológicas gratis. Eso sería un cambio filosófico — de una IA extractiva a una más participativa.
La imagen más grande
Si tiene éxito, este tipo de infraestructura podría empujar a toda la industria hacia una inteligencia más responsable y composable. Agentes intercambiando datos y acceso a modelos en cadena. Regalías fluyendo automáticamente. Liquidez haciendo que conjuntos de datos oscuros pero valiosos se conviertan de repente en capital productivo.
Pero crypto ha visto muchos “primitivos siguientes” que sonaron revolucionarios y se desvanecieron. La tecnología tiene que ser utilizable, los incentivos sostenibles, y el momento correcto con hacia dónde va la IA.
No sé cómo se desarrollará esto. Parte de mí tiene suficiente curiosidad para seguir observando — el problema se siente importante, y el experimento vale la pena. Parte de mí se pregunta si los verdaderos avances vendrán de algún lugar más tranquilo, o si los problemas de coordinación en cadena resultan demasiado obstinados.
¿Qué opinas — es la liquidez de datos la pieza que falta, o estamos complicando lo que debería quedarse fuera de la cadena? La conversación se siente temprana.

#DeAI #TradingTales #TradingCommunity #cryptouniverseofficial