OpenLedger es uno de esos proyectos que te hace pausar un segundo, no porque la presentación sea completamente nueva, sino porque el problema subyacente es lo suficientemente real como para que no lo puedas descartar de inmediato.
Y honestamente, eso es raro en el crypto ahora.
Después de unos ciclos, empiezas a desarrollar una especie de alergia a las grandes narrativas. DeFi iba a reconstruir las finanzas. GameFi iba a incorporar a mil millones de usuarios. La tierra del Metaverso iba a reemplazar de alguna manera el sector inmobiliario. Las cadenas modulares iban a solucionar la escalabilidad. El crypto de IA es ahora la última etapa donde cada proyecto de repente descubre que siempre se trató de inteligencia artificial.
Así que cuando algo se llama a sí mismo una “blockchain de IA”, el primer instinto no es la emoción. Es la sospecha.
Lees la frase una vez y tu cerebro se prepara inmediatamente para el habitual montón de palabras de moda: inteligencia descentralizada, agentes abiertos, soberanía de datos, infraestructura escalable, propiedad comunitaria, alineación de incentivos. Todos los ingredientes familiares. Todas las palabras que suenan importantes hasta que preguntas qué está realmente sucediendo debajo.
Pero OpenLedger al menos está señalando hacia un problema que sí importa.
La IA tiene un problema de contribución.
No es un problema de marca. No es un problema de token. Es un problema de contribución.
Cada sistema de IA útil se construye sobre los datos, conocimientos, ejemplos, retroalimentaciones, documentos, flujos de trabajo, etiquetas, correcciones y experiencia en el dominio de otra persona. Esa es la parte que a la gente le gusta omitir. El modelo se presenta como el producto, pero el modelo es realmente el resultado final de una larga cadena de entradas invisibles.
Alguien creó los datos. Alguien los limpió. Alguien los organizó. Alguien sabía lo suficiente sobre el tema para hacer que la información fuera útil. Luego, todo eso se absorbe en un modelo, y una vez que está dentro, la contribución original se vuelve casi imposible de ver.
Esa es la extraña negociación de la IA moderna. Todos contribuyen a la capa de inteligencia, pero solo unas pocas plataformas capturan la mayor parte del valor.
OpenLedger está tratando de construir en torno a esa brecha.
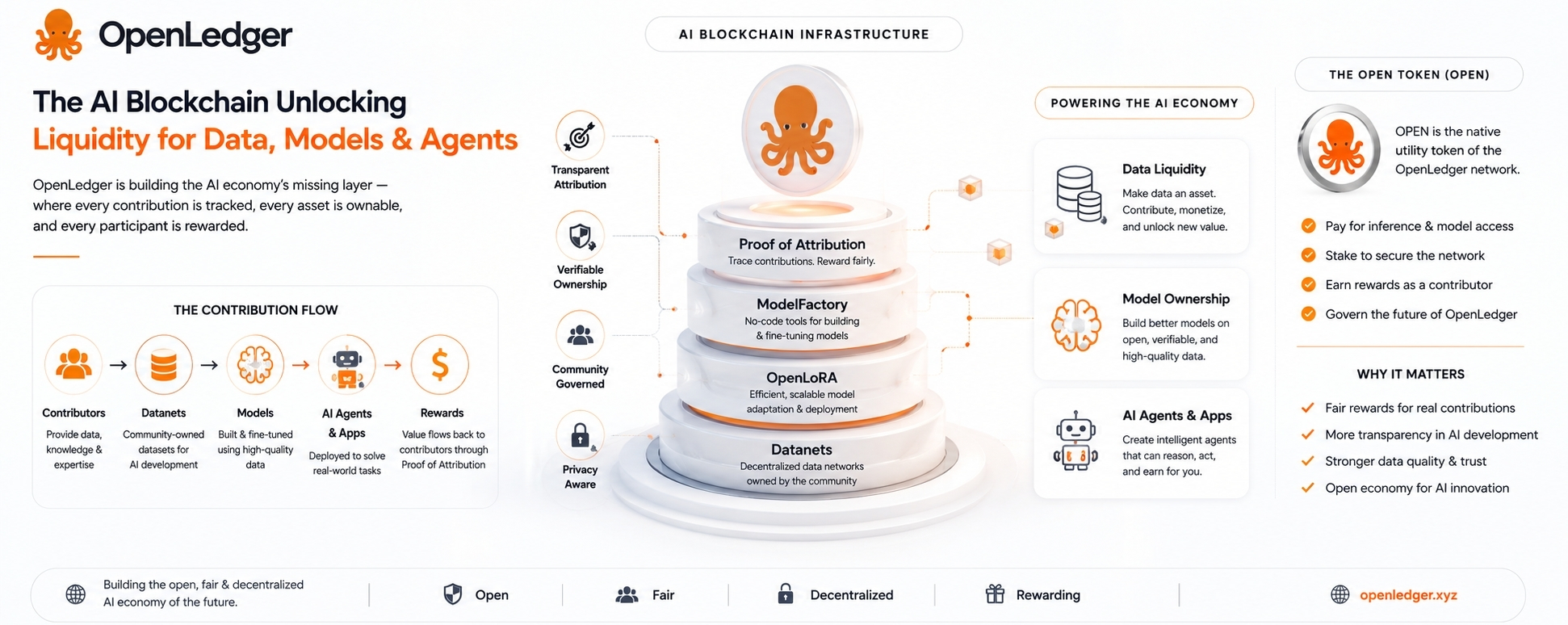
La idea básica es que los datos, modelos y agentes de IA no deberían flotar solo como objetos digitales vagos. Deberían ser trazables. Deberían tener procedencia. Deberían estar conectados a las personas o comunidades que los crearon. Y si generan valor más tarde, debería haber algún mecanismo para recompensar a los contribuyentes detrás de ellos.
Eso suena obvio cuando lo dices lentamente. También suena extremadamente difícil cuando piensas en cómo funciona realmente la IA.
Porque la atribución de IA es un lío.
Un modelo no responde a una pregunta simplemente sacando un archivo de una estantería. No dice: “Esta respuesta provino del 12% del conjunto de datos de Ali, del 8% de este informe de auditoría y del 3% de esa publicación en el foro.” Al menos no de forma natural. Las salidas están moldeadas por datos de entrenamiento, ajuste fino, pesos, prompts, sistemas de recuperación, adaptadores y todo lo que se haya añadido a la pila.
Así que cuando OpenLedger habla de Prueba de Atribución, esa es la parte que vale la pena prestar atención, pero también la parte que merece el mayor escepticismo.
La idea es identificar qué datos influyeron en una salida de IA y recompensar a los contribuyentes en función de esa influencia. Si funciona, es significativo. Si se vuelve una vagueza, es solo otro sistema de puntos tokenizados con un mejor lenguaje.
Esa es la línea que OpenLedger tiene que seguir.
Aún así, el marco no es vacío. La IA necesita una mejor capa contable. Ahora mismo, Internet está lleno de valor que los sistemas de IA consumen, comprimen y monetizan. La salida parece limpia, pero la historia de entrada es borrosa. Y a medida que los agentes de IA se vuelven más comunes, esa borrosidad se convierte en un problema mayor.
Si un agente de IA ayuda a auditar un contrato inteligente, ¿de dónde vino su conocimiento de seguridad?
Si un asistente de trading de IA reconoce un patrón, ¿de quién fueron los datos que ayudaron a enseñarle?
Si una herramienta de IA legal revisa un contrato, ¿qué documentos moldearon su razonamiento?
Si un asistente médico da una sugerencia, ¿qué conocimiento estaba bajo esa respuesta?
Ya no son preguntas filosóficas. Se convierten en preguntas económicas en el momento en que la gente comienza a pagar por la salida.
Por eso son interesantes las Datanets de OpenLedger.
Una Datanet es básicamente una red de datos de propiedad comunitaria construida en torno a un tema o caso de uso específico. En lugar de que los datos sean recogidos silenciosamente por una empresa centralizada, los contribuyentes pueden añadir información útil a una capa de datos compartida. Esos datos pueden ser utilizados para entrenar o ajustar modelos.
En teoría, podrías tener una Datanet para exploits de contratos inteligentes, otra para documentos legales, otra para flujos de trabajo de atención médica, otra para mapeo de datos, otra para análisis de riesgos en DeFi, y así sucesivamente.
La idea no es solo recopilar datos. Todo el mundo recopila datos. La idea es mantener un registro de quién contribuyó con qué, y luego conectar esa contribución al uso futuro del modelo.
Esa es la parte que se siente más seria que el habitual argumento de “IA más token”.
Porque si la IA especializada es realmente hacia donde va el mercado, entonces los datos especializados se vuelven extremadamente valiosos. Los modelos generales ya son lo suficientemente buenos para tareas amplias. La próxima pelea no es sobre quién puede hacer que un chatbot diga cosas agradables. Se trata de quién puede construir modelos que entiendan dominios específicos en profundidad.
Una IA general puede explicar el riesgo de contratos inteligentes. Un modelo especializado entrenado con datos de exploits reales podría ayudar realmente a detectarlo.
Una IA general puede hablar de finanzas. Un modelo especializado entrenado en comportamiento estructurado del mercado y datos de riesgo puede volverse más útil.
Una IA general puede resumir contenido de atención médica. Un modelo clínico especializado, asumiendo que la privacidad y el cumplimiento se manejan adecuadamente, podría hacer algo mucho más valioso.
Así que OpenLedger está apuntando a una tendencia real: el movimiento de la IA general a la inteligencia específica de dominio.
Pero de nuevo, la ejecución importa.
La cripto tiene la costumbre de convertir cada problema válido en una economía de tokens sobrediseñada. A veces el token es esencial. A veces es solo cinta adhesiva sobre un mercado que podría haber funcionado sin uno.
OPEN, el token nativo, se supone que debe estar dentro de la economía de OpenLedger. Puede usarse para tarifas de red, acceso a modelos, pagos de inferencia, staking, gobernanza y recompensas para contribuyentes. Eso tiene sentido estructuralmente. Si la red realmente está siendo utilizada, el token tiene un rol.
Pero la frase “si la red realmente está siendo utilizada” está haciendo mucho trabajo aquí.
Un token no crea demanda por existir. Un mercado no se vuelve valioso porque un panel dice que los contribuyentes pueden ganar. La parte difícil es hacer que la gente contribuya con datos de alta calidad, hacer que los desarrolladores construyan modelos a partir de esos datos, hacer que los usuarios paguen por esos modelos, y asegurarse de que las recompensas fluyan de una manera que se sienta justa en lugar de arbitraria.
Ahí es donde muchos proyectos cripto fracasan.
Pueden diseñar incentivos para la primera ola. Pueden atraer a los primeros contribuyentes. Pueden hacer que las velas se vean vivas. Pero el valor a largo plazo solo llega si el sistema produce algo que la gente fuera del bucle de incentivos realmente quiera.
El futuro de OpenLedger depende de si puede producir sistemas de IA útiles, no solo conjuntos de datos bien etiquetados.
ModelFactory es parte de ese intento. Está destinado a facilitar el ajuste fino, especialmente para personas que no quieren lidiar con infraestructura de aprendizaje automático pesada. Esa es una buena dirección porque la mayoría de los expertos en dominios no son ingenieros de ML.
La persona que entiende contratos legales puede no saber cómo ajustar un modelo.
El trader que entiende la estructura del mercado puede no saber cómo desplegar infraestructura de inferencia.
El investigador de seguridad que entiende exploits puede no querer gestionar adaptadores y GPUs.
Si OpenLedger puede facilitar que estas personas conviertan conocimiento en activos de IA utilizables, eso importa.
OpenLoRA es otro componente práctico. Los modelos especializados son útiles, pero ejecutarlos puede ser costoso. El ajuste fino basado en LoRA ya es uno de los caminos más realistas para crear muchas variaciones de modelos ligeros. Si OpenLedger puede apoyar el despliegue eficiente de muchos modelos ajustados, eso le da al ecosistema una base más práctica.
Aquí es donde el proyecto comienza a parecer menos un juego narrativo puro y más un intento de construir una pila de producción completa de IA.
Los datos entran a través de Datanets.
Los modelos se crean o ajustan a través de herramientas como ModelFactory.
OpenLoRA ayuda con el despliegue.
Los agentes y aplicaciones de IA se sitúan en la parte superior.
La cadena registra contribuciones, usos y recompensas.
Ese es el mapa, al menos.
Si el territorio se ve así es otra pregunta.
La parte más difícil sigue siendo la atribución. Es fácil escribir “Prueba de Atribución” en un whitepaper. Es mucho más difícil hacer que los contribuyentes confíen en que el sistema está midiendo con precisión la influencia. Si las recompensas son demasiado vagas, la gente perderá interés. Si el sistema puede ser manipulado, los datos de baja calidad inundarán. Si solo los grandes contribuyentes se benefician, el ángulo comunitario se debilita. Si la atribución es demasiado cara o demasiado lenta, los desarrolladores pueden evitarla.
También está el problema de la privacidad. Algunos de los datos de IA más valiosos son sensibles. Datos de atención médica, registros financieros, material legal, flujos de trabajo empresariales: estas no son cosas que la gente arroje casualmente en una red abierta. OpenLedger necesitará caminos fuertes de permisos, privacidad y cumplimiento si quiere una adopción seria más allá de los conjuntos de datos nativos de cripto.
Luego está el problema del mercado. La cripto IA está saturada. Cada semana hay otra plataforma de agentes, mercado de datos, red de inferencia, capa de computación descentralizada o protocolo de propiedad de modelos. Algunos son reflexivos. Muchos son solo envolturas narrativas. Los inversores y usuarios están cansados, incluso si aún persiguen la próxima rotación.
Así que OpenLedger necesita probar que su mecanismo central realmente importa.
No en teoría.
En uso.
¿Puede alguien construir un mejor modelo gracias a OpenLedger?
¿Puede un contribuyente ganar porque sus datos realmente mejoraron una salida?
¿Puede un desarrollador lanzar un agente de IA más rápido o más barato?
¿Puede un usuario confiar en la procedencia de lo que está interactuando?
¿Puede el sistema atraer datos que no habrían aparecido en ningún otro lugar?
Esas son las preguntas que importan.
Y tal vez por eso OpenLedger vale la pena seguir sin dejarse llevar.
No es automáticamente revolucionario. No está garantizado que se convierta en la capa base de la propiedad de IA. No es inmune a los problemas habituales de la cripto de especulación, actividad sobre-incentivada e inflación narrativa.
Pero está girando en torno a un problema real.
La IA está creando un valor enorme a partir de entradas invisibles. El sistema actual no tiene una forma justa o transparente de rastrear esas entradas. OpenLedger está tratando de construir esa capa faltante utilizando rieles de blockchain, lógica de atribución e incentivos de tokens.
Eso puede funcionar. Puede que no.
Pero el problema es lo suficientemente real como para que el intento merezca más que un rápido desdén.
La forma más clara de pensar sobre OpenLedger es esta: quiere darle a la IA una memoria económica.
No solo memoria en el sentido del modelo, sino memoria de contribución. ¿Quién añadió los datos? ¿Quién moldeó el modelo? ¿Quién construyó el agente? ¿Quién merece una parte cuando el sistema se vuelve útil?
Esa es una idea convincente, especialmente en un mundo donde la IA se vuelve más poderosa y más centralizada al mismo tiempo.
El escéptico en mí todavía quiere pruebas. Uso real. Contribuyentes reales. Modelos reales. Demanda real. No solo campañas, puntos, emisiones de tokens y capturas de pantalla de socios del ecosistema.
Pero el investigador en mí entiende por qué esta categoría importa.
Si la próxima fase de IA se construye sobre datos especializados y agentes autónomos, entonces la propiedad y la atribución no son características secundarias. Se convierten en infraestructura.
OpenLedger está apostando por eso.
Y después de leer suficientes whitepapers para saber con qué frecuencia estas cosas colapsan en ruido, al menos este deja atrás una pregunta que perdura: