
i was reading about memorisation in large language models a few weeks ago and honestly the thing that kept nagging at me was not that models memorise training data 😂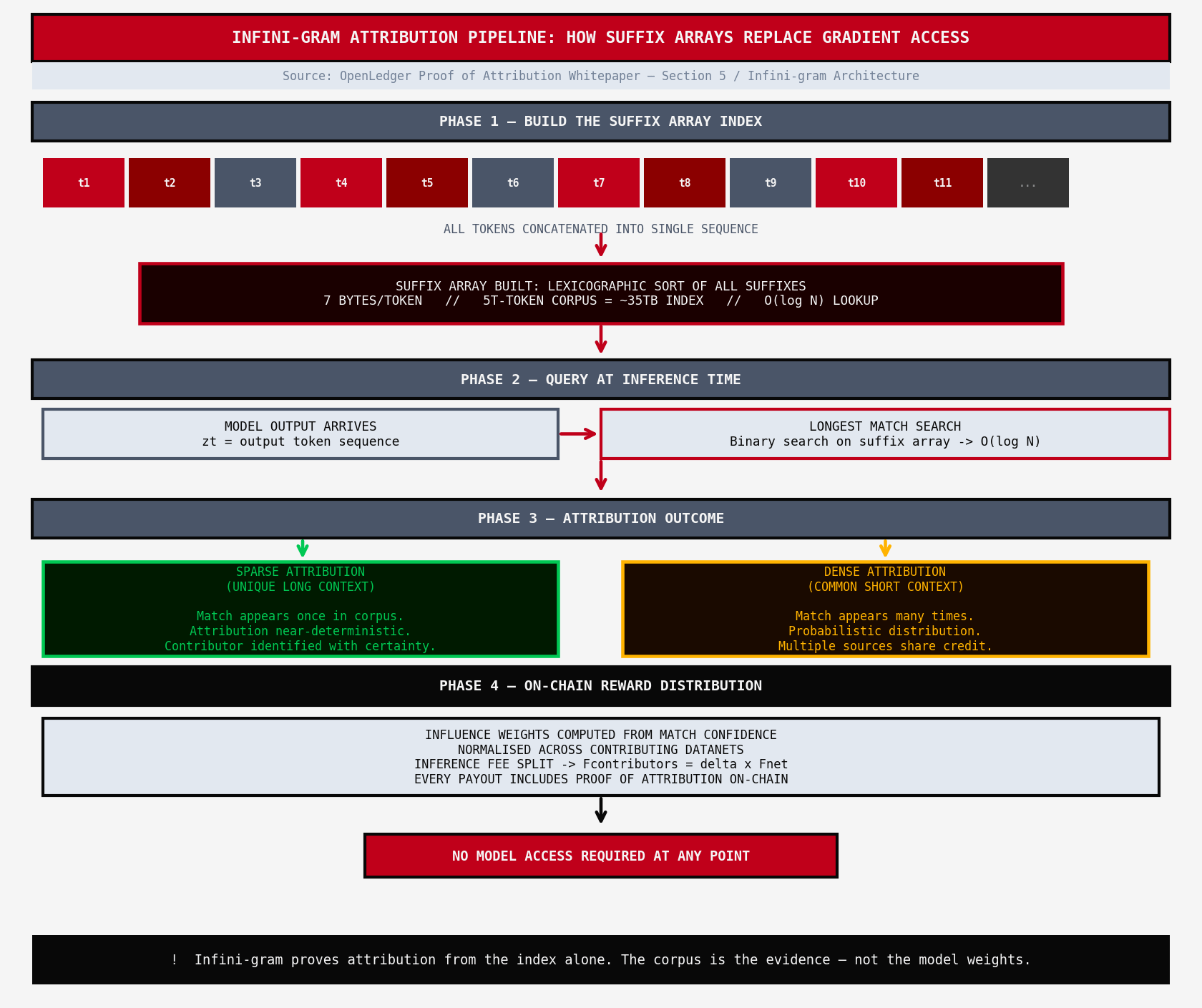
everyone knows they do.
the thing that nagged was that there was no clean way to prove it on demand
you could run experiments.you could probe the model.you could get a probabilistic answer about whether a specific piece of content influenced a specific output.but the answer was never deterministic.it was alwAys aproximate.always expensive to compute.always dependent on having access to model internals that most people simply dont have
and then i spent yesterday going through the Infini-gram section of the OpenLedger whitepaper.
the problem it solves is specific.gradient-based attribution -the influence function approach that works for smaller LoRA m0dels-completely breaks down at scale. when your training corpus hits trillions of tokens,,you cant store gradient vectors for every datapoint. you cant compute Hessian approximations in any reasonable time.you cant even do the math without access to model internals that black-box inference APIs will never give you.
so OpenLedger built a different method for large models entirely
Infini-gram uses suffix arrays.the entire training corpus gets concatenated into one sequence and then lexicographicaly sorted into a suffix array.that index costs roughly 7 bytes per token.for a five trillion token corpus that is about 35 terabytes of index.large but queryable.and once built, any ♾️-gram probability query runs in around 135 milliseconds
And the core idea is clean.
instead of asking"how did this data influence the gradient"-a question that requires model access -Infini-gram asks "does this output span appear in the training data,."it finds the longest matching context between the output and the indexed corpus.if the match is unique and specific,attribution is nearly deterministic.if the context is common and generic, ,it falls back to probabilistic distribution across sources.
i genuinely like the elegance of that.you dont need the model.you need the index.the proof lives in the corpus,.not in the weights
i was reading the OpenledgerHQ account this morning.OPEN is up 14.3% over the last seven days. Story Protocol partnership confirmed in January for legal AI training data -real domain-specific data flowing into DataNets. $13.43M in 24-hour volume last recorded.the ecosystem is not sitting still
what i cant resolve is the paraphrase problem. Infini-gram finds exact or near-exact span matches. a model that learned fromtrainingdata but outputs a paraphrase of it
diferent words
same meaning
same source
leaves no trace in the suffix array
the attribution is clean when the model reproduces. it goes silent when the model generalises.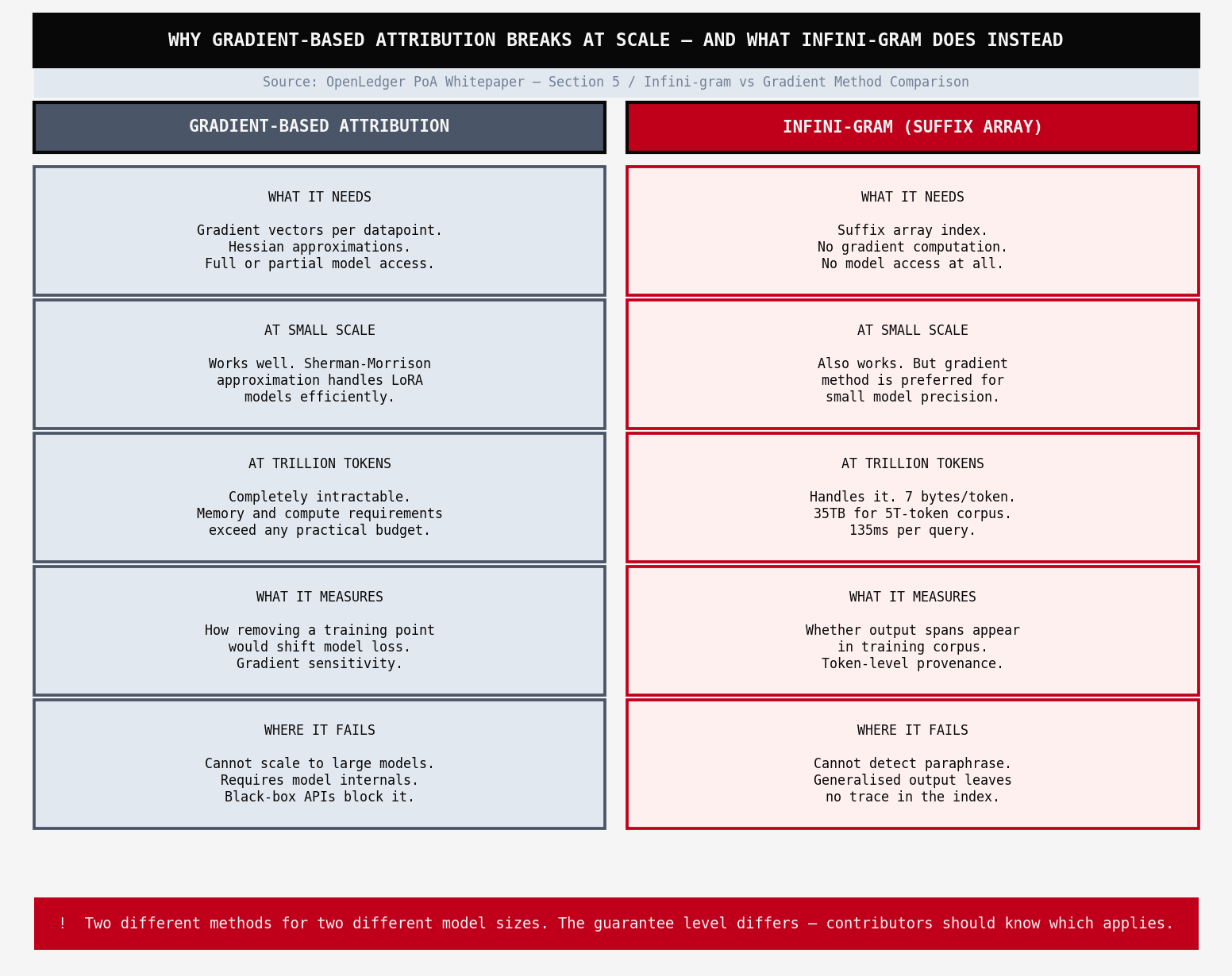
honestly dont know if Infini-gram is the cleanest large-scale attribution system ever built for AI or a method that works perfectly on the cases that matter least and goes quiet on the cases that matter most?? 🤔
