He estado revisando la arquitectura de openledger en los últimos días, tratando principalmente de entender si el sistema realmente está resolviendo un problema de coordinación en torno a los datos de IA, o si todavía está operando en la fase de “tokenizar la participación primero, averiguar la demanda después” en la que muchos proyectos de infraestructura cripto tienden a desviarse.
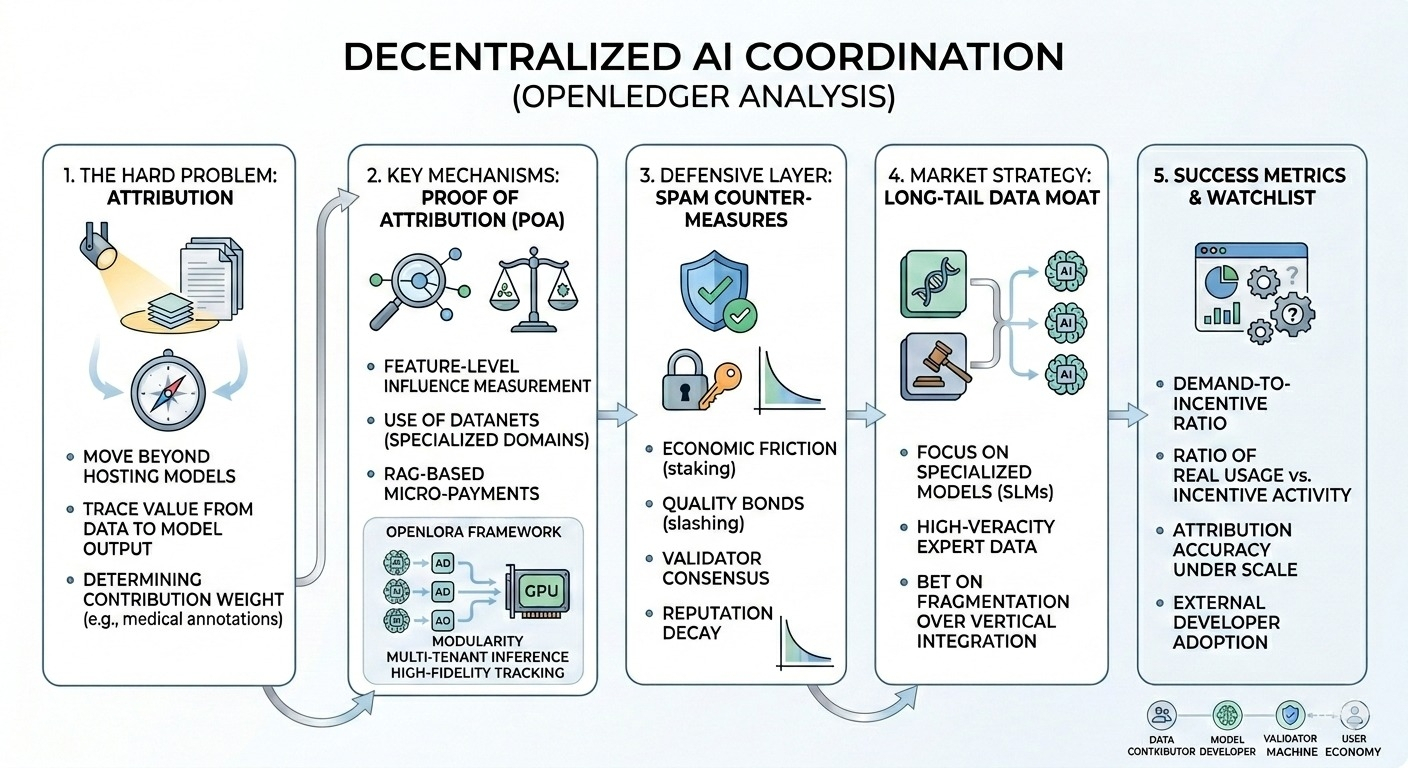
La mayoría de la gente parece ver openledger como solo otro token de IA + cripto, pero honestamente eso se siente demasiado superficial. Lo que realmente captó mi atención no fue tanto la capa del token en sí. Fue el intento de construir un sistema de atribución alrededor de la contribución de datos descentralizada, y luego conectar esa atribución con la creación de valor en los modelos secundarios.
ese es un problema de sistemas mucho más difícil que simplemente alojar modelos en la cadena.
la idea central, al menos desde cómo lo entiendo, es que los contribuyentes proporcionan datasets, interacciones de modelo o entradas relacionadas con inferencias en la red, y el protocolo intenta rastrear la procedencia y el uso a lo largo del tiempo. si un modelo se beneficia de un dataset, los contribuyentes originales son teóricamente recompensados a través de incentivos conscientes de atribución.
y esta es la parte en la que sigo pensando: toda la arquitectura depende de que la atribución siga siendo confiable a gran escala.
porque una vez que te mueves más allá de pequeños datasets curados, la línea entre 'contribución valiosa' y 'ruido de fondo' se vuelve muy difusa muy rápido. especialmente en sistemas de IA donde las salidas son probabilísticas y los modelos absorben información de manera difusa. rastrear la creación de valor a través de miles o millones de puntos de datos suena limpio en teoría, pero operativamente se siente desordenado.
por ejemplo, imagina a los contribuyentes alimentando anotaciones de imágenes médicas especializadas en una capa de dataset descentralizada. si un modelo de IA entrenado con esos datos se vuelve comercialmente útil, ¿cómo determina exactamente el protocolo el peso de la contribución? ¿frecuencia de uso? ¿unicidad? ¿impacto en el rendimiento posterior? hay un riesgo real de que la atribución se vuelva demasiado simplificada o computacionalmente costosa de mantener.
aún así, creo que openledger al menos está apuntando a la capa correcta del stack.
en lugar de competir directamente en calidad de modelo, parecen más enfocados en la infraestructura alrededor de la coordinación de IA — datasets, incentivos, procedencia, verificación y enrutamiento económico entre participantes. de una manera extraña, me recuerda menos a una red blockchain tradicional y más a un intento de construir infraestructura contable para sistemas de inteligencia distribuidos.
las dinámicas del marketplace también son interesantes. el protocolo asume implícitamente que habrá una demanda sostenida de datos de IA obtenidos externamente y acceso modular a modelos. tal vez eso suceda. tal vez modelos más pequeños y especializados terminen necesitando datasets de larga cola descentralizados que las plataformas centralizadas no pueden adquirir o verificar fácilmente.
pero la suposición subyacente a todo esto es que el desarrollo futuro de la IA se vuelve más fragmentado en lugar de más verticalmente integrado.
no estoy completamente convencido todavía.
porque si los grandes proveedores de modelos siguen absorbiendo la mayor parte del valor económico internamente — entrenamientos, inferencias, distribución y bucles de retroalimentación — entonces los mercados de contribución descentralizados pueden tener dificultades para atraer una demanda significativa fuera de casos de uso de nicho.
la capa de incentivos también se siente frágil en las primeras etapas. las emisiones de tokens pueden impulsar la participación por un tiempo, pero eventualmente los contribuyentes necesitan creer que las recompensas están vinculadas a la utilidad real de la red en lugar de a la circulación especulativa. de lo contrario, el sistema corre el riesgo de optimizarse por volumen en lugar de por señal.
y los sistemas de datos descentralizados son extremadamente vulnerables a los incentivos de spam.
si los contribuyentes son recompensados por cargas o interacciones, los datos sintéticos de baja calidad se vuelven inevitables a menos que las capas de verificación sean inusualmente fuertes. openledger parece estar consciente de este problema por la forma en que estructuran la lógica de atribución y validación, pero aún me pregunto si esos filtros se mantienen una vez que los incentivos se vuelven económicamente significativos.
otra cosa a la que sigo volviendo: ¿quién realmente crea valor aquí?
¿es el contribuyente que suministra datos en bruto? ¿el validador verificando la procedencia? ¿el desarrollador del modelo que integra datasets en sistemas utilizables? ¿la capa de inferencia generando demanda recurrente?
el protocolo intenta coordinar a todos ellos simultáneamente, lo cual es ambicioso, pero también crea una superposición de incentivos que podría volverse inestable con el tiempo.
no creo que la respuesta sea obvia todavía. y tal vez eso esté bien.
ahora mismo, la arquitectura se siente más como un experimento de coordinación económica en evolución que como una capa de infraestructura finalizada. lo que, honestamente, lo hace más interesante de observar.
observando:
* si la precisión de la atribución mejora bajo escala
* ratio de uso real del modelo vs actividad impulsada por incentivos
* mecanismos de control de calidad para datasets contribuidos
* si los desarrolladores externos realmente construyen demanda recurrente sobre la red
supongo que la pregunta abierta es si la infraestructura de IA descentralizada realmente necesita coordinación nativa de blockchain — o si los incentivos de tokens son solo un relleno temporal antes de que exista una demanda real del mercado.