
Al principio, honestamente pensé que la inteligencia artificial iba a ser algo simple.
Durante meses, mi timeline en Twitter de cripto había estado completamente inundado de conversaciones sobre agentes de IA, inteligencia descentralizada, sistemas autónomos, y la idea de que la IA eventualmente se convertiría en la próxima gran capa económica de internet. Dondequiera que mirara, la gente hablaba del futuro como si ya hubiera llegado.
“Los agentes de IA van a reemplazar flujos de trabajo.”
“Todos tendrán IA.”
“Despliega un agente y monetiza la inteligencia.”
La emoción era imposible de ignorar.
Y naturalmente, asumí que participar sería fácil.
Imaginé que la experiencia se sentiría similar a la mayoría de las aplicaciones de cripto modernas: abrir un sitio web, conectar una billetera, hacer clic en unos pocos botones, tal vez personalizar un asistente de IA y, de repente, formar parte de este masivo cambio tecnológico que todos parecían obsesionarse.
Esa ilusión desapareció sorprendentemente rápido.
Cuanto más profundizaba en el ecosistema de IA, más desconectado comenzaba a sentirme. De repente, cada conversación se llenó de términos como APIs, capas de inferencia, alojamiento de modelos, computación GPU, entornos en la nube, bases de datos vectoriales, pipelines de ajuste fino e infraestructura de implementación. Tutoriales que inicialmente parecían amigables para principiantes rápidamente se transformaron en guías de codificación llenas de comandos de terminal y suposiciones técnicas.
 En un momento pasé casi toda una noche tratando de entender cómo alojar y ajustar un modelo, solo para darme cuenta de que aún estaba confundido sobre la diferencia entre pesos de modelos, adaptadores y capas de infraestructura.
En un momento pasé casi toda una noche tratando de entender cómo alojar y ajustar un modelo, solo para darme cuenta de que aún estaba confundido sobre la diferencia entre pesos de modelos, adaptadores y capas de infraestructura.
Lo que más me sorprendió no fue que la tecnología fuera compleja. Por supuesto que lo era.
Lo que me sorprendió fue lo inaccesible que aún se sentía toda la experiencia para la gente normal.
A pesar de todo el ruido sobre la inteligencia artificial convirtiéndose en “el futuro”, la mayoría de la gente aún no puede participar de manera significativa en la construcción de sistemas de IA sin experiencia técnica. El ecosistema a menudo parece diseñado principalmente para desarrolladores, investigadores e ingenieros de infraestructura. Incluso muchos proyectos de IA supuestamente “impulsados por la comunidad” aún comunican en un lenguaje que, sin querer, aleja a los recién llegados.
Esa realización cambió completamente cómo empecé a ver los proyectos de infraestructura de IA.
En lugar de enfocarme solo en las narrativas más ruidosas, me interesé más en la pregunta más silenciosa debajo de todo:
¿Quién está realmente construyendo sistemas que hacen que la IA sea más transparente, colaborativa y accesible?
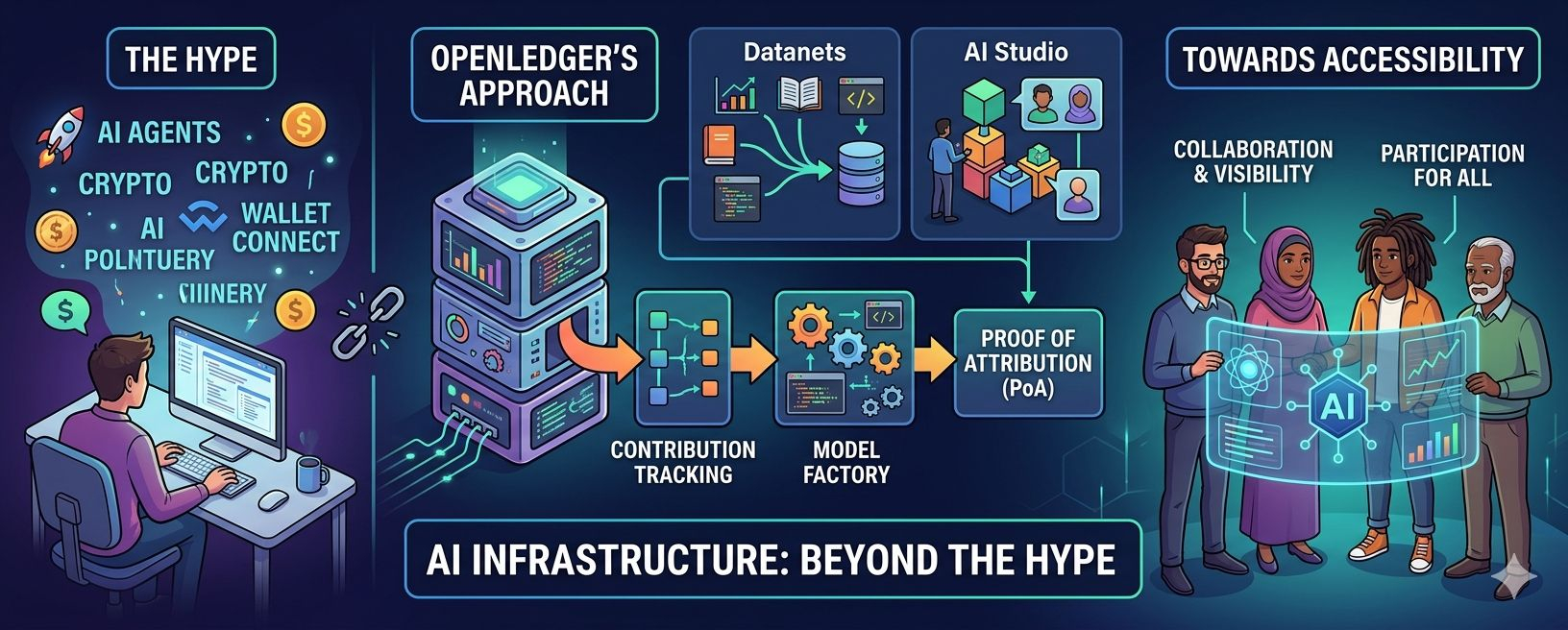
Esa curiosidad es lo que finalmente me llevó hacia [OpenLedger](https://www.openledger.xyz?utm_source=chatgpt.com), un proyecto que intenta abordar la IA desde un ángulo muy diferente.
Lo que inmediatamente me llamó la atención fue que OpenLedger no parecía obsesionado con comercializar la inteligencia artificial como magia. En cambio, el proyecto parecía centrarse en algo más profundo: la capa de infraestructura debajo de la IA misma.
Mientras que muchas narrativas de IA hoy giran en torno a salidas cada vez más poderosas, OpenLedger parece más interesada en resolver problemas estructurales en torno al seguimiento de contribuciones, atribución, transparencia y desarrollo colaborativo de IA.
Y sinceramente, eso puede volverse mucho más importante con el tiempo de lo que la gente actualmente se da cuenta.
Una de las partes más interesantes del ecosistema es el Modelo Factory de OpenLedger y la infraestructura de OpenLoRA.
Para la mayoría de las personas fuera del mundo de la IA, términos como “adaptadores LoRA” suenan intimidantes al principio, pero el concepto es en realidad bastante comprensible. En lugar de volver a entrenar enormes modelos de IA desde cero cada vez que alguien quiere un comportamiento especializado, los adaptadores LoRA permiten a los desarrolladores ajustar eficientemente modelos para tareas específicas utilizando modificaciones más pequeñas y ligeras.
Piensa en ello menos como reconstruir un cerebro entero y más como enseñar a un sistema existente nueva experiencia a través de capas especializadas.
Lo que OpenLedger está tratando de construir en torno a esta idea es particularmente interesante porque combina el entrenamiento de modelos, ajuste fino, implementación y alojamiento en un ecosistema más unificado mientras introduce verificación en cadena para componentes de IA.
Esa capa de verificación importa más de lo que suena inicialmente.
A medida que los sistemas de IA se vuelven más poderosos, la confianza se convertirá inevitablemente en una de las conversaciones más importantes de la industria. Si los modelos de IA eventualmente influyen en la educación, la salud, las finanzas, la gobernanza, la investigación, los medios o las decisiones empresariales, la gente comenzará a hacer preguntas difíciles.
¿De dónde vino este modelo?
¿Quién lo entrenó?
¿Qué conjuntos de datos lo influyeron?
¿Se pueden verificar sus salidas?
Sin transparencia, los sistemas de IA corren el riesgo de convertirse en cajas negras de las que la sociedad depende cada vez más, pero que no puede auditar o entender adecuadamente.
Aquí es donde la filosofía más amplia de OpenLedger en torno a la atribución se vuelve genuinamente atractiva.
Porque debajo de todos los sistemas modernos de IA hay algo que la gente a menudo olvida:
Contribución humana.
Cada día, los modelos de inteligencia artificial absorben enormes cantidades de información generada por humanos. Conversaciones. Escritura. Creatividad. Investigación. Opiniones. Conocimiento cultural. Código. Material educativo. Pensamiento analítico. Resolución de problemas.
La IA moderna no surge de la nada. Se construye colectivamente a partir de la producción digital de la humanidad.
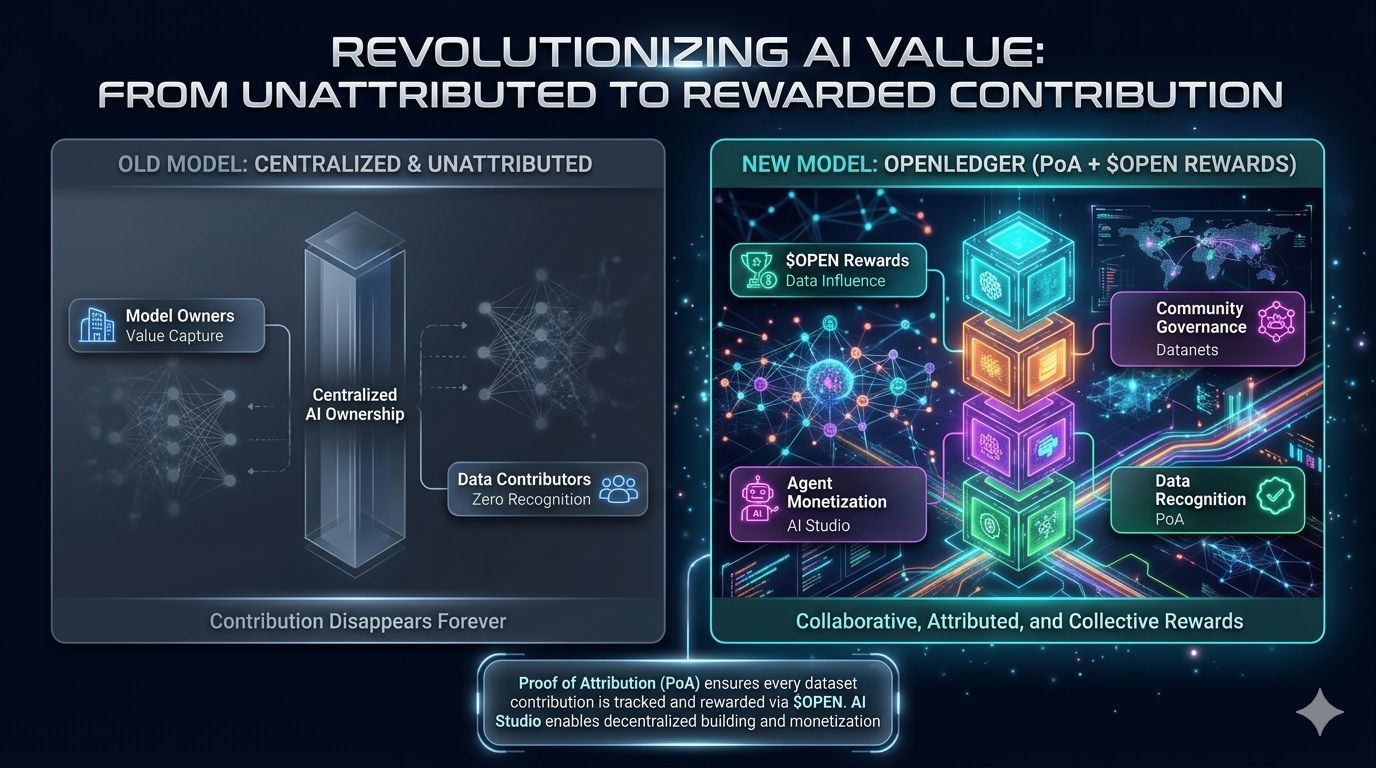
Sin embargo, la mayoría de los contribuyentes desaparecen por completo una vez que esos sistemas se vuelven comercialmente valiosos.
Miles de millones de contribuciones humanas fluyen hacia canalizaciones de IA centralizadas con casi ninguna visibilidad, reconocimiento, propiedad o participación financiera adjunta a ellas.
Ese desequilibrio podría convertirse eventualmente en una de las preguntas éticas y económicas definitorias de la era de la IA.
Y aquí es donde OpenLedger introduce lo que puede ser su concepto más importante: Prueba de Atribución, o PoA.
En su núcleo, la Prueba de Atribución intenta rastrear cómo las contribuciones de datos influyen en las salidas de IA y crear mecanismos donde los contribuyentes puedan potencialmente recibir reconocimiento y participación económica a través del $OPEN ecosistema.
La idea es ambiciosa, pero también sorprendentemente fundamentada.
OpenLedger no está pretendiendo que la atribución resolverá de repente todos los problemas en inteligencia artificial. En realidad, rastrear con precisión la influencia a través de enormes sistemas de IA es increíblemente difícil. Los sistemas de verificación pueden ser imperfectos. Los incentivos pueden ser manipulados. Escalar la atribución a través de modelos cada vez más avanzados introduce una enorme complejidad técnica.
Pero la dirección subyacente aún se siente importante.
Porque por primera vez, los proyectos están comenzando a preguntar seriamente si la creación de valor de la IA debería permanecer completamente centralizada mientras que las contribuciones humanas subyacentes permanecen invisibles.
Esa conversación puede volverse inevitable en la próxima década.
La futura economía de IA puede no solo depender de quién construya los modelos más poderosos. También puede depender de quién pueda probar de dónde se originó la inteligencia.
Otra parte de OpenLedger que merece atención es su enfoque hacia los datos mismos a través de Datanets.
La mayoría de la gente se enfoca en modelos de IA porque son visibles. Pero los modelos son solo tan buenos como la información que los alimenta. Los datos son la verdadera base debajo de cada sistema inteligente.
Datanets intenta hacer que la creación de conjuntos de datos sea colaborativa y liderada por la comunidad. En lugar de depender completamente de conjuntos de datos corporativos cerrados, las comunidades pueden reunir, limpiar, organizar y transformar información sin procesar en conjuntos de datos listos para la IA optimizados para modelos de lenguaje grandes.
Las implicaciones se vuelven interesantes muy rápido.
Imagina comunidades de investigación en salud construyendo conjuntos de datos médicos transparentes. Profesionales legales organizando colaborativamente archivos legales abiertos. Analistas financieros creando repositorios estructurados de inteligencia de mercado. Educadores construyendo bases de datos de aprendizaje multilingües. Comunidades culturales preservando lenguas regionales y registros históricos que de otro modo permanecerían subrepresentados en los sistemas de IA convencionales.
La colaboración de datos descentralizada podría potencialmente crear sistemas de IA que sean más representativos a nivel global en lugar de estar moldeados principalmente por un puñado de corporaciones que controlan ecosistemas de información cerrados.
Luego está AI Studio, que podría convertirse en la parte de OpenLedger con la que los usuarios normales se conectan más directamente.
Lo que hace que AI Studio sea interesante no es solo la herramienta en sí, sino la filosofía detrás de ella. La plataforma busca proporcionar a creadores, emprendedores y desarrolladores un entorno donde puedan construir, personalizar, implementar y potencialmente monetizar agentes de IA sin necesidad de entender completamente cada capa de infraestructura desde el principio.
Y sinceramente, esa accesibilidad importa enormemente.
La adopción masiva rara vez proviene solo de la superioridad tecnológica.
Sucede cuando las personas comunes finalmente se sienten lo suficientemente cómodas para participar sin miedo.
Internet mismo alguna vez se sintió abrumadoramente técnico. Los primeros sitios web, sistemas de alojamiento e infraestructura en línea eran intimidantes para la mayoría de la gente. Con el tiempo, la experiencia del usuario evolucionó. La complejidad se volvió abstracta. Las interfaces se simplificaron. La participación se expandió.

La IA eventualmente podría seguir el mismo camino.
Por supuesto, proyectos como OpenLedger aún están en una etapa temprana.
Hay preguntas legítimas sobre escalabilidad, precisión de atribución, incertidumbre regulatoria, diseño de incentivos y adopción a largo plazo. Construir una infraestructura de IA transparente y económicamente justa a escala global es un desafío increíblemente difícil.
Pero incluso reconociendo esos riesgos, la dirección más amplia aún se siente significativa.
Porque debajo de todas las discusiones técnicas, OpenLedger está realmente explorando algo filosófico:
Si la inteligencia artificial es finalmente entrenada colectivamente por la humanidad, ¿debería el valor generado por la IA permanecer concentrado entre un pequeño número de sistemas centralizados?
¿O deberían los contribuyentes eventualmente convertirse en participantes visibles dentro de la economía de inteligencia que ayudaron a crear?
No creo que la industria tenga una respuesta clara aún.
Pero creo cada vez más que la atribución, la propiedad, la transparencia y la infraestructura colaborativa se convertirán en algunas de las conversaciones más importantes en IA durante la próxima década.
No solo por la tecnología.
Pero porque la IA puede eventualmente convertirse en uno de los sistemas económicos más grandes que la humanidad haya construido jamás.
Y si eso sucede, la pregunta de quién recibe reconocimiento — y quién es recompensado — puede importar tanto como la inteligencia misma.
