Something has been bothering me about the way people talk about AI infrastructure. Not the compute part. Everyone talks about compute. Chips, inference costs, model size, speed. Fine. Those matter. But markets get obsessed with what is easy to measure and ignore what becomes econonically painful later.
I saw this before in crypto. Blockspace. Everyone loved throughput charts. Few asked who would actually pay continuously for trust coordination. Then the conversation matured.
AI feels similar. But the strange part is how people still think about data like a one-time fuel source. Feed model. Train. Reward contributor. Move on. Very internet-brain logic.
Except useful AI is not behaving like disposable software anymore.
If an enterprise model learns internal compliance workflows, proprietary research methods, negotiation logic, customer decision trees – what exactly happened economically? Did the company buy information? License capability? Or are they effectively leasing economically useful memory?
That distinction sounds semantic until money gets involved.
Take a hospital. They license structured clinical protocols into an AI workflow assistant. Not public medical facts. Their internal decision logic. Escalation patterns. Edge-case judgement rules developed over years. Six months later that assistant is deeply integrated into operations. Was that knowledge sold once? Or is the hospital paying for persistent behavior?
This is where the conversation gets uncomfortable.
Because AI does not behave like a PDF archive. Once knowledge becomes embedded into machine behavior, clean ownership language breaks. The system is not accessing a file. It is expressing learned behavior shaped by prior information exposure. That is messier. Law gets weird here too. Copyright works reasonably well when copying is visible. Licensing works when access boundaries are clear. AI breaks those assumptions in annoying ways.
And if autonomous agents become real economic participants – honestly, things get even stranger. A trading agent remembers execution preferences. A legal agent remembers contract review heuristics. That memory is producing value repeatedly.
So here is the question that keeps pulling me back: why would recurring economic output be priced as a one-time event?
That logic feels broken.
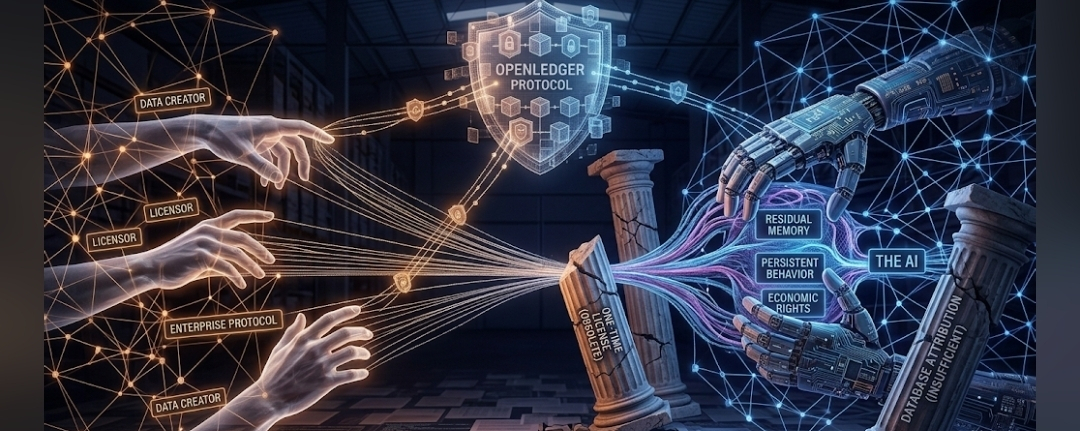
Now, a lot of commentary around OpenLedger focuses on attribution. Provenance. Data contribution. Those are fair but surface-level to me. Attribution alone is not a business model. A database can record who contributed something. Paperwork can do that. The harder question is whether attribution changes economic behavior.
Because if attribution becomes part of permission enforcement, then something more interesting happens. Now the issue is not simply "who helped train this model?" It becomes "what economic rights remain active because that contribution still matters?"
Different question. Much bigger.
But let me be honest about the technical reality, because I see too much elegant infrastructure marketing ignoring the ugly parts.
Here is the first problem. Can you actually isolate machine memory cleanly enough to lease it? Human language makes this sound easier than it is. Models do not store knowledge in neat folders labeled "licensed protocol" and "unlicensed behavior." Learned patterns blur together. Weight changes compound. Attribution becomes probabilistic, not deterministic. You cannot run a SQL query on a transformer and ask for every inference that used a specific hospital's escalation logic. That does not exist.
Then there is enforcement without breaking inference. If you verify permission on every single forward pass, latency explodes. If you batch-check, you leak usage. Zero-knowledge proofs for model provenance are still experimental. And fine-tuning or continual learning will shift weight distributions. Does the leased memory persist after a model update? Does the license need renegotiation every time you retrain? Nobody has a clean answer.
These are not theoretical concerns. Markets route around friction all the time. If OpenLedger's attribution rails add cost or slow down inference while competitors move faster – even if legally riskier – developers will simply ignore them. That is not cynicism. That is how software gets built.
But here is where the enterprise perspective makes this even more painful, and also more urgent.
I have talked to legal teams at mid-size companies who are quietly panicking. They signed standard data licensing agreements – one-time payment, sometimes annual access. They fed internal compliance workflows, research methods, decision trees into a model. Six months later, that assistant is handling real operational logic. And now they realize: did we just sell our knowledge?
One logistics company found that a vendor's model retained their routing logic after training, then used it for a competitor. The contract had "no residual retention" language. But how do you prove deletion inside a black-box weight matrix? You cant. Courts have no precedent for this.
What enterprises actually need is recurring permissions infrastructure for machine memory. If a compliance agent relies on our escalation triggers in every audit, that should generate continuous economic rights. Not a one-time data purchase. We would happily pay for clean attribution rails if they came with enforceable terms. But right now, no standard clause covers "persistent behavioral embedding."
That is the real dividing line between a database and a protocol. A database records history. A protocol enforces ongoing economic relationships.
OpenLedger's direction – verifiable lineage plus permission enforcement – is exactly the kind of primitive that could solve this. But I am not fully convinced yet. The gap between the vision and what is actually deployable is still wide. Can they deliver probabilistic attribution with legal-grade certainty? Will courts recognize on-chain memory records as evidence of persistent use? And if integration costs 15% more in compute, will procurement accept that?
Still, even with all that uncertainty, I cannot shake the feeling that people are looking slightly in the wrong direction.
Maybe AI infrastructure is not ultimately about compute efficiency at all. Maybe the harder economic problem is retained permission. Who gets remembered. For how long. Under what economic terms. And whether that memory can be leased rather than sold once.
That sounds abstract now. Then again, so did blockspace economics before markets figured out recurring settlement was the actual business model.OpenLedger may fail completely at solving this. Very possible. The technical problems – isolability, enforcement, model drift – are legitimately hard. But the question it points toward feels real. And sometimes the better investment thesis is not the answer a project gives. It is the problem the market has not learned to price yet.
Enterprises are already leaking value because their contracts don't cover residual memory rights. Developers are ignoring attribution because it adds friction. That tension is where something has to break – either someone builds infrastructure that makes permission enforcement cheap enough, or we all keep pretending AI memory is free.
I know which side I am watching.