Me quedé un buen rato leyendo cómo OpenLedger habla sobre transformar la categorización de transacciones en una capa de razonamiento para las máquinas.
Al principio, esta idea suena bastante lógica.
Los datos en la cadena son demasiado confusos para los humanos. Un wallet transfiriendo fondos. Un contrato llamando a otro contrato. Un vault moviendo activos. Un agente ejecutando varios pasos consecutivos. Todo pasa como un hash frío, denso, casi imposible de leer a simple vista.
Si hubiera una capa de contexto en medio, agrupando ese comportamiento en categorías más comprensibles como asignación de capital, enrutamiento de tesorería o movimiento de riesgo, el agente parecería entender el mundo financiero más rápido.
Pero cuanto más pienso, más veo que el punto peligroso está en la palabra 'entender'.
Si la categorización de transacciones solo ayuda a los humanos a releer los datos, es muy útil. Si solo ayuda al agente a reducir la carga de acceso, tiene razón de existir. Pero si se convierte en la capa de razonamiento principal, donde el agente mira el mundo a través de etiquetas contables predefinidas por humanos, entonces ya no es un trampolín.
Puede convertirse en una jaula cognitiva.
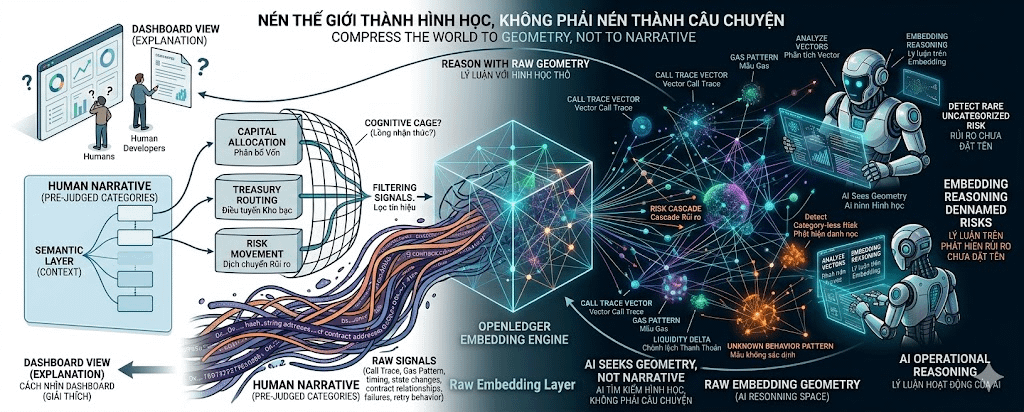
El problema no es que la blockchain sea demasiado ruidosa. El problema es ruidosa para quién.
Con los humanos, una cadena de trazas de llamadas, cambios de estado, patrones de gas, tiempos y relaciones de direcciones son difíciles de leer. Pero con un modelo de aprendizaje automático, esas cosas no necesariamente son basura. Pueden ser señales. Incluso, lo que los humanos ven como caótico puede contener el estado más reciente del riesgo.
Un agente financiero fuerte no solo necesita saber a qué categoría pertenece esa transacción. Necesita detectar estados que aún no tienen categoría. Patrones que aún no han sido nombrados. Formas en que el flujo de dinero se disfraza antes de que los humanos puedan escribir una etiqueta para ello.
Si forzamos todo a unas pocas etiquetas como enrutamiento de tesorería o asignación de capital demasiado pronto, estamos filtrando información antes de que la IA pueda ver la verdadera estructura.
Pero decir 'deja que la IA lea los datos en crudo directamente' tampoco es práctico.
Las trazas de llamadas en crudo son muy costosas. Los cambios de estado son muy pesados. Un agente que opera en tiempo real no puede decidir cada vez parseando millones de bloques, reconstruyendo gráficas de billetera, creando embeddings desde cero y luego actuando. Si lo hiciera, el sistema se congestionaría por la latencia y el costo computacional antes de que pudiera volverse inteligente.
Por lo tanto, el problema no es si se debe comprimir o no los datos.
El problema es en qué forma comprimir.
Si comprimimos el comportamiento en cadena en etiquetas legibles para humanos, obtenemos un dashboard más bonito. Pero si el agente usa esas mismas etiquetas como entrada para decisiones, quedará atrapado en la forma en que los humanos entendían las finanzas de ayer.
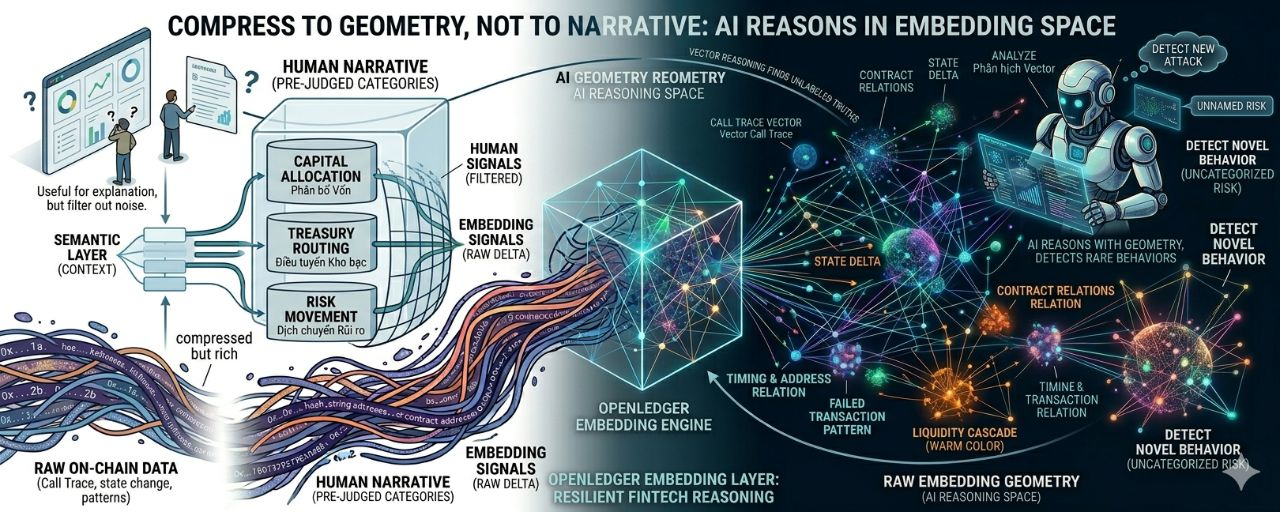
Lo que OpenLedger debería priorizar no es una capa de etiquetas contables para máquinas.
Sino que es una capa de embedding cruda.
Es decir, los datos en crudo aún se comprimen, pero no se traducen demasiado pronto en categorías pobres en información. Las trazas de llamadas, patrones de gas, movimientos de liquidez, delta de estado, ruta de contrato, transacción fallida, comportamiento de reintentos y relaciones de direcciones pueden convertirse en un espacio de embedding rico en estructura. Lo que los humanos miran puede que no entiendan inmediatamente, pero el agente puede ver distancias, clústeres, anomalías, correlaciones y riesgos que las etiquetas textuales no pueden contener.
En otras palabras: no comprimas el mundo en una historia para los humanos y luego hagas que la IA crea en esa historia.
Comprime el mundo en geometría para las máquinas.
Esta es la frontera importante con OpenLedger.
No creo que OpenLedger esté equivocado al querer hacer que los datos en cadena sean más utilizables para la IA. Por el contrario, si OpenLedger con MCP y la capa de contexto puede reducir el costo de acceso, normalizar el flujo de datos y llevar al agente a la región de información correcta más rápido, eso es un rompecabezas muy valioso. Nadie quiere que un agente financiero tenga que excavar desde el bloque génesis cada vez que toma una decisión.
Pero la capa de contexto no debería convertirse en los ojos del agente.
Debería ser un enrutador y un traductor.
Ayuda al agente a encontrar la región de datos correcta más rápido. Ayuda a los humanos a releer decisiones en un lenguaje más comprensible. Pero la parte central del razonamiento del agente no debería estar atrapada en categorías contables estáticas.
Porque en DeFi, las etiquetas siempre envejecen más rápido que el comportamiento.
Una transacción que carga activos en una bóveda puede ser optimización de rendimiento. También puede ser riesgo de apalancamiento. También puede ser exposición de gobernanza. También puede ser la semilla de un cascada que aún no ha ocurrido. Si el sistema lo empuja a una categoría demasiado pronto, el razonamiento anterior se desviará. No porque la etiqueta sea completamente incorrecta. Sino porque la etiqueta es correcta muy pocas veces.
Este también es el lugar donde la capa semántica puede convertirse en una superficie de ataque.
Cuando las etiquetas se convierten en señales de enrutamiento para el agente, el atacante no solo atacará el contrato. Pueden atacar el significado. Pueden hacer que el comportamiento malicioso se vea como enrutamiento de tesorería, reducción de riesgos u optimización de liquidez. Si el agente confía más en las etiquetas que en la estructura cruda subyacente, ha perdido lo más importante en las finanzas en cadena: el escepticismo matemático.
Por lo tanto, el proceso correcto debería ir al revés.
El agente ve a través de embeddings en crudo y señales crudas que han sido comprimidas correctamente. Luego, cuando necesita auditar, informar o solicitar confirmación, la capa semántica traduce esa decisión a un lenguaje que los humanos pueden entender.
La IA ve a través de vectores.
Los humanos leen a través de etiquetas.
No inviertas ese orden.
La pregunta final no es si OpenLedger puede hacer las transacciones más comprensibles. La verdadera pregunta es: ¿la capa de contexto de OpenLedger ayudará a la IA a ver las finanzas en cadena más claramente, o hará que la IA use las gafas contables de los humanos y llame a eso razonamiento?