Abrí el estudio de openledger para revisar un datanet, y un pequeño detalle se quedó en mi cabeza más tiempo del que esperaba.
No era un gráfico de precios.
No fue una afirmación escandalosa.
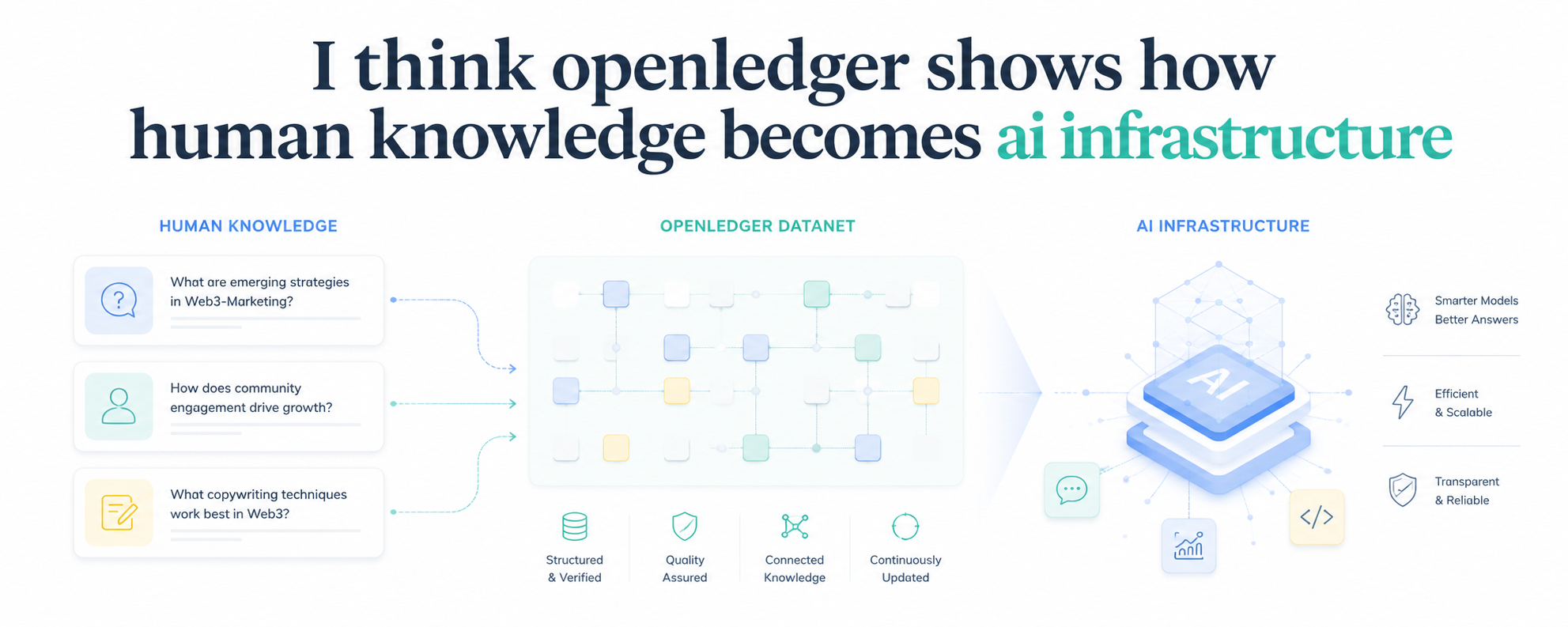
Era una página llamada web3-marketing, con alrededor de 10.7k filas de datos de preguntas y respuestas.
Al principio, parecía simple. Una lista de preguntas sobre el compromiso comunitario, la confianza, las redes de influencers, la redacción, la psicología crypto y las plataformas sociales descentralizadas. Nada demasiado dramático. Solo información estructurada.
Pero cuanto más lo miraba, más sentía que aquí es donde openledger se vuelve interesante.
Porque la IA no solo necesita más datos.
Necesita datos útiles.
Necesita datos con contexto.
Necesita datos que puedan ser rastreados hasta las personas y comunidades que los crearon.
Esa es la parte que muchas personas pasan por alto cuando hablan de IA y cripto. A menudo saltan directamente a tokens, modelos o hype. Pero la verdadera pregunta es mucho más profunda. ¿Quién enseña al modelo? ¿Quién posee el conocimiento? ¿Quién recibe crédito cuando ese conocimiento se vuelve útil?
Esta datanet de marketing web3 me dio una forma sencilla de pensarlo.
En las plataformas de contenido normales, una persona escribe algo, lo publica y tal vez recibe 'likes' durante unos días. Después de eso, el contenido desaparece lentamente del feed. El valor se vuelve temporal.
Dentro de una datanet, el mismo tipo de conocimiento puede convertirse en parte de una capa de datos de IA más grande. Una respuesta útil sobre la construcción de confianza en el marketing web3 ya no es solo una publicación. Una explicación clara sobre la psicología del usuario ya no es solo contenido educativo. Una buena pregunta sobre redes de influencers ya no es solo una discusión comunitaria.
Se convierte en conocimiento estructurado.
Eso importa.
Un futuro modelo de IA entrenado con este tipo de datos podría entender el marketing web3 de una manera más práctica. No solo leyendo publicaciones aleatorias de internet, sino aprendiendo de filas enfocadas de información sobre un tema.
Por eso veo openledger de manera diferente ahora.
Openledger no solo intenta recopilar datos. Está tratando de hacer que los datos sean utilizables, trazables y económicamente conectados a sistemas de IA.
Esa es una gran diferencia.
La idea de la prueba de atribución es importante aquí. En palabras simples, se trata de rastrear qué datos ayudaron a dar forma a la salida de un modelo. En el viejo mundo de la IA, los datos a menudo entran en una caja negra. El modelo aprende de ellos, pero el contribuyente original generalmente desaparece de la cadena de valor.
Openledger está tratando de cambiar ese patrón.
Si los datos pueden ser rastreados, entonces la contribución se vuelve visible. Si la contribución se vuelve visible, entonces el valor puede ser compartido de una manera más justa. Eso no significa que cada fila de datos se volverá automáticamente valiosa. Significa que el sistema está tratando de crear un enlace entre la contribución y el impacto.
Ese enlace es la verdadera historia.
Para mí, el impacto social también es importante. Hoy en día, la mayor parte del poder de los datos de IA se encuentra en manos de grandes plataformas y empresas cerradas. Los creadores normales, investigadores, educadores, comercializadores y miembros de la comunidad a menudo dan conocimiento a internet sin saber a dónde va.
Un modelo de datanet puede crear un camino diferente.
Un comercializador de cripto puede contribuir con conocimientos sobre campañas web3. Un profesor puede aportar conocimientos educativos. Un desarrollador puede contribuir con conocimientos de programación. Un investigador puede aportar conocimientos específicos del dominio. Con el tiempo, estos pequeños fragmentos pueden apoyar modelos de IA especializados.
No es solo una idea técnica. Es una idea económica.
Los datos se convierten en un activo.
El conocimiento se convierte en parte de la infraestructura.
La contribución se convierte en más que un trabajo de fondo no remunerado.
Por eso creo que la datanet de marketing web3 es un ejemplo útil. Muestra openledger de una manera fácil de entender. En lugar de hablar solo de grandes modelos de IA, muestra la materia prima detrás de ellos.
Filas de preguntas.
Filas de respuestas.
Filas de conocimiento comunitario.
Por supuesto, esto también viene con responsabilidad. Más datos no siempre significan mejor IA. Los datos malos pueden crear salidas malas. Los datos copiados pueden debilitar la confianza. Las respuestas sesgadas pueden hacer que un modelo sea menos útil. Así que el futuro de las datanets dependerá de la calidad, el filtrado, la revisión y la verdadera utilidad.
Ahí es donde creo que openledger tiene que demostrar su valía con el tiempo.
Pero la dirección tiene sentido para mí.
Si la IA va a dar forma al próximo internet, entonces la capa de datos no puede seguir siendo invisible. La gente necesita saber de dónde proviene el conocimiento. Los creadores necesitan conjuntos de datos confiables. Los contribuyentes necesitan un rol más claro. Y los usuarios necesitan más confianza en lo que produce la IA.
Aquí es donde la cripto se vuelve relevante, no como ruido, sino como una capa de coordinación.
El token abierto está conectado a esta economía de red más amplia, que incluye el uso de datos, acceso a modelos, incentivos y gobernanza. Pero no veo el punto más fuerte solo como la utilidad del token. Lo veo como el intento de construir una economía en torno a la contribución de IA en sí.
Esa es una idea más duradera.
Cuando miré esa datanet de marketing web3, no solo vi preguntas de marketing.
Vi un pequeño ejemplo de cómo el conocimiento humano puede volverse legible por máquina, trazable y económicamente activo.
Y quizás ese sea el verdadero mensaje de openledger.
El futuro de la IA no solo se construirá con modelos.
También se construirá por las personas que los enseñan.