
La Conferencia de Dartmouth: Donde Nació la “IA”
En el verano de 1956, John McCarthy, Marvin Minsky, Claude Shannon y Nathaniel Rochester se reunieron en el Dartmouth College para el Proyecto de Investigación de Verano sobre IA de Dartmouth.
Fue aquí donde se acuñó por primera vez el término “Inteligencia Artificial”. La propuesta decía:
“Cada aspecto del aprendizaje o cualquier otra característica de la inteligencia puede describirse tan precisamente que se puede hacer una máquina para simularlo.”
No era un hackathon de codificación. Era un plan para un campo, señalando redes neuronales, búsqueda, razonamiento simbólico y lenguaje. El sueño estaba trazado.
Para aprender más:
Conferencia de Dartmouth
De Reglas a Aprendizaje: El Perceptrón
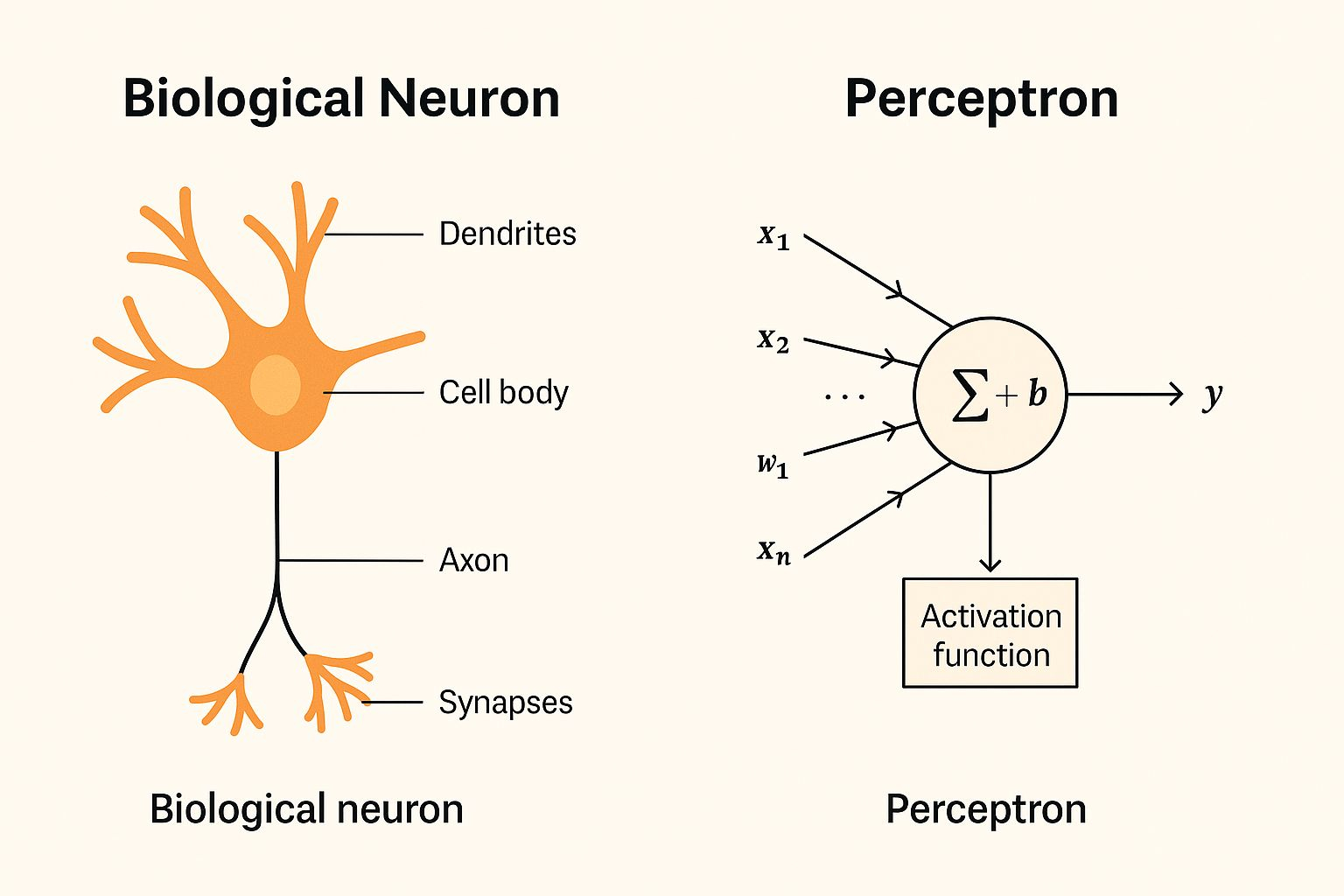
En 1957, Frank Rosenblatt preguntó: ¿y si las máquinas pudieran aprender como las neuronas? Introdujo el perceptrón, el primer modelo matemático de una neurona.
El perceptrón toma entradas, las multiplica por pesos, añade un sesgo y las pasa a través de una función escalón:
f(x) = h(w ⋅ x + b)
Entradas (xi) = características, como valores de píxeles
Pesos (wi) = importancia de cada característica
Sesgo (b) = ajusta el límite de decisión
Función escalón (h) = salida binaria (1 o 0)
Esto convirtió al perceptrón en un clasificador lineal, capaz de trazar un límite en línea recta entre clases.
Rosenblatt también construyó hardware: el Perceptrón Mark I (1960). Tenía una cuadrícula de fotocélulas 20×20 actuando como una retina, conectadas aleatoriamente a unidades de asociación, con pesos ajustables implementados por potenciómetros. Motores actualizaban estos pesos durante el aprendizaje.
Fue capaz de clasificar patrones simples y creó una gran emoción. El New York Times incluso afirmó que podría un día caminar, hablar y ser consciente (
Archivo de NYT, 1958).

Pero tenía límites: no podía resolver problemas como XOR, que no son linealmente separables.
📖 Aprende más:
Perceptrón (Wikipedia),
Artículo de Rosenblatt de 1958 (PDF).
Modelos de Lenguaje y Predicción de la Siguiente Palabra
En paralelo, una idea muy diferente estaba surgiendo. ¿Podrían las máquinas predecir texto en lugar de razonar con lógica?
Claude Shannon (1948–1951): Midió la entropía del inglés pidiendo a humanos que adivinaran la siguiente letra. Esto demostró que el lenguaje es estadísticamente predecible.
N-grams (décadas de 1960-1970): En lugar de razonamiento completo, aproximar mirando las últimas palabras. Un modelo de trigram predice P(wt | wt−2, wt−1).
Corpora: El Brown Corpus (1961) proporcionó 1M de palabras de texto, permitiendo que los modelos estadísticos fueran probados.
Aplicaciones: Los primeros experimentos de reconocimiento de voz en IBM y Bell Labs en la década de 1970 usaron modelos n-gram con métodos de suavizado como Good-Turing y más tarde Kneser-Ney.
Esto es importante porque los LLMs modernos todavía utilizan el mismo objetivo: predecir el siguiente token. La diferencia es la escala y las arquitecturas neuronales, no el objetivo.
Aprende más:
¡Haz clic aquí!
IA Simbólica y Sistemas Expertos
Después de Dartmouth y el Perceptrón, los primeros años estuvieron dominados por la IA simbólica. Los investigadores construyeron sistemas expertos: programas que codificaban conocimiento específico del dominio como reglas lógicas.
Ejemplo: MYCIN (1972) en Stanford. Usó ~600 reglas para recomendar antibióticos para infecciones. En casos restringidos, funcionó tan bien como los médicos.
Pero la IA simbólica enfrentó el cuello de botella de adquisición de conocimiento. Escribir y mantener reglas para dominios del mundo real desordenados se volvió imposible. Esto inició la búsqueda de una alternativa de diferentes maneras.
Prolog: Programación en Lógica
En 1972, Alain Colmerauer y Philippe Roussel introdujeron Prolog (“Programación en Lógica”). A diferencia de la programación imperativa, Prolog era declarativa. Escribías hechos y reglas, y el sistema infería respuestas.
Ejemplo:
cat(tom).
mouse(jerry).
hunts(X, Y) :- cat(X), mouse(Y).
Consulta: ?- hunts(tom, jerry). → true
Prolog alimentó la IA simbólica y fue central en el Proyecto de Computadora de Quinta Generación de Japón (1982–1992), que invirtió $400M en la construcción de máquinas de razonamiento inteligente.
Aprendizaje Automático: Los Datos se Convierten en el Maestro
📖 Lectura adicional: Teoría del Aprendizaje Estadístico – Vapnik, Fundamentos del Aprendizaje Automático – Mohri, Rostamizadeh, Talwalkar
Para la década de 1980, la IA simbólica estaba estancada. Las reglas no podían capturar el desorden interminable del mundo real. La nueva idea era radical: en lugar de escribir reglas a mano, alimentar al sistema con datos y dejar que el algoritmo descubriera las reglas por sí mismo.
Esto marcó el nacimiento del aprendizaje automático. La transición no fue solo filosófica sino profundamente matemática. Vladimir Vapnik y Alexey Chervonenkis formalizaron la idea a través de la Teoría del Aprendizaje Estadístico.
El problema central era la generalización: dado un conjunto finito de datos de entrenamiento, ¿cómo puede un modelo hacer predicciones precisas sobre casos no vistos? Vapnik y Chervonenkis introdujeron ideas clave:
Dimensión VC: una medida de la capacidad de una clase de modelo
Minimización del Riesgo Empírico (ERM): minimizar el error de entrenamiento
Minimización del Riesgo Estructural (SRM): equilibrar el error de entrenamiento con la complejidad del modelo para evitar el sobreajuste
Esto hizo que el aprendizaje automático se convirtiera en una ciencia en lugar de un trabajo de conjeturas.
Primeras Algoritmos: Árboles, Bayes y Márgenes
Una vez que la teoría estuvo en su lugar, los algoritmos prácticos comenzaron a dar forma a las industrias.
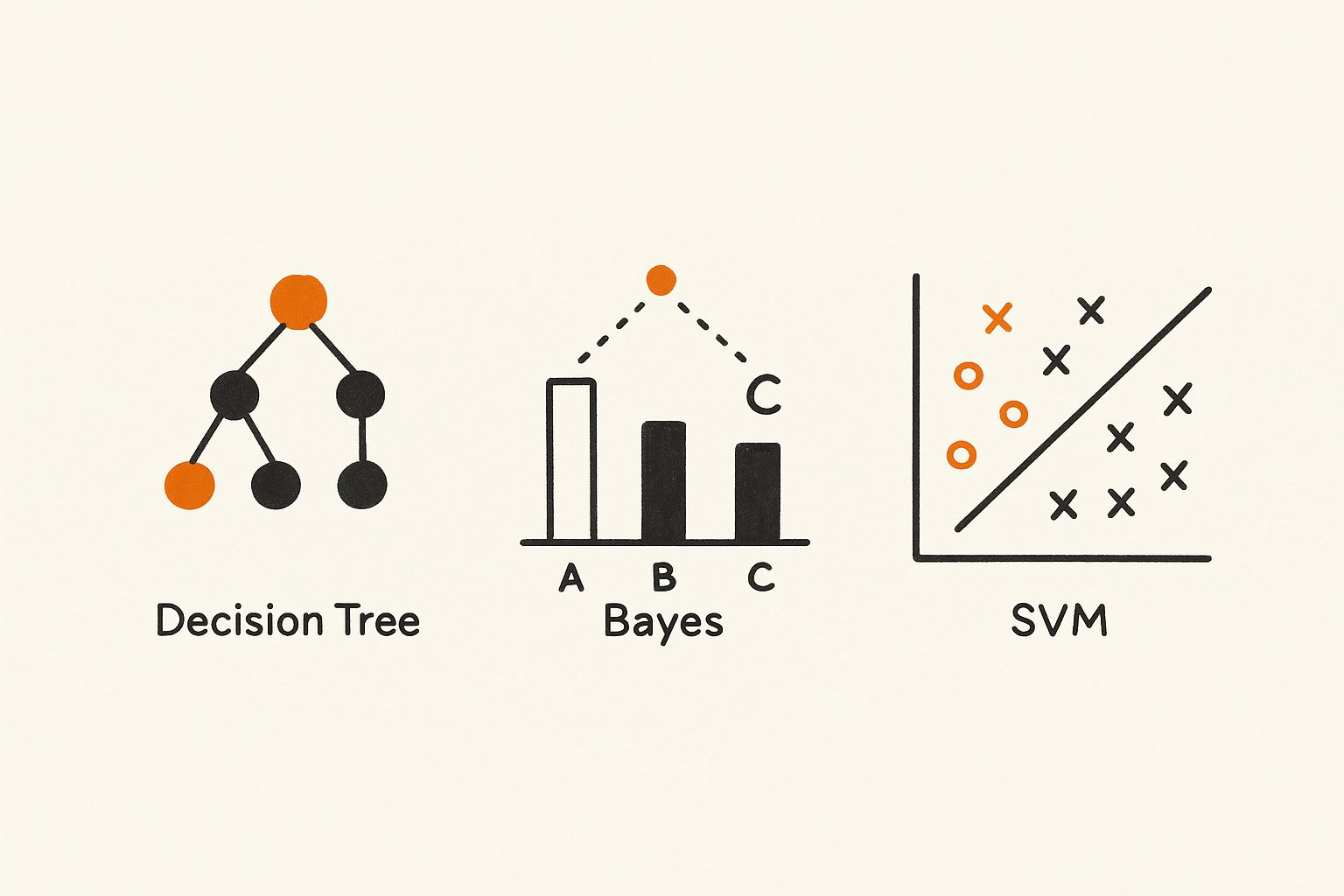
Árboles de Decisión
Ross Quinlan presentó ID3 en 1986. Los árboles de decisión dividen los datos paso a paso, creando reglas de si-entonces directamente de ejemplos. Eran interpretables y útiles en la detección de fraudes, diagnóstico médico y segmentación de clientes.
Bayes Ingenuo
Basado en el teorema de Bayes, Bayes Ingenuo asume que las características son independientes. A pesar de esta simplificación, funcionó bien para la clasificación de texto. En los años 90, impulsó filtros de spam y clasificación de documentos a gran escala.
Máquinas de Vectores de Soporte (SVMs)
Introducidas por Vapnik en los años 90, las SVMs buscaban encontrar el hiperplano que mejor separara las clases maximizando el margen. Sobresalieron en el reconocimiento de escritura a mano, detección de rostros y bioinformática, mostrando un fuerte poder de generalización en espacios de alta dimensión.
📖 Aprende más:
Aprendizaje de Árboles de Decisión (Wikipedia),
Bayes Ingenuo (Wikipedia),
Máquinas de Vectores de Soporte (Wikipedia).
Redes y el avance de la Retropropagación
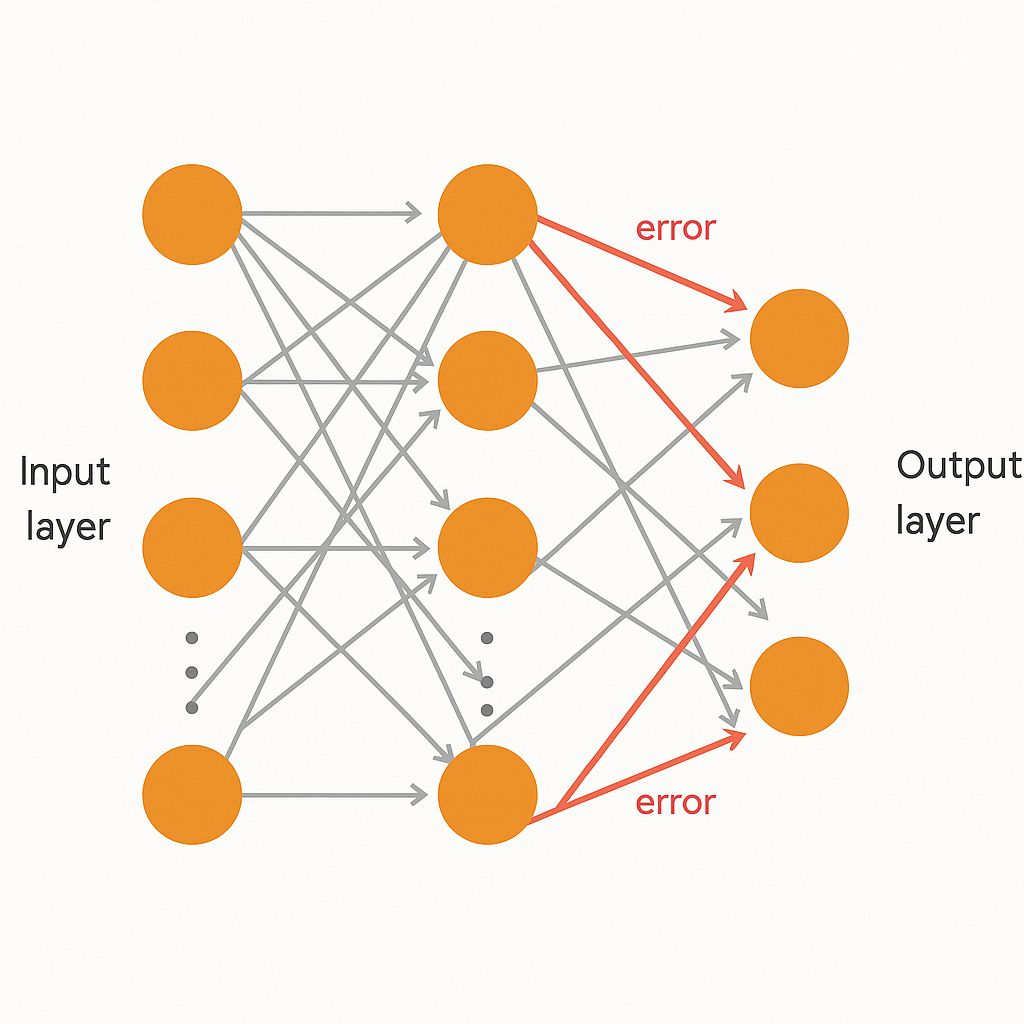
El cerebro humano construye comprensión en capas: de bordes a formas a objetos. Un solo perceptrón no podía hacer eso, pero los perceptrones multicapa (MLPs) sí podían.
En 1986, Rumelhart, Hinton y Williams popularizaron la retropropagación, un método para entrenar estas redes multicapa. Los errores de la capa de salida se propagaron hacia atrás, ajustando los pesos en las capas anteriores paso a paso.
La retropropagación utilizó el descenso de gradiente, empujando los pesos hacia valores que redujeran el error. Esto hizo que los MLPs fueran lo suficientemente poderosos como para aproximar casi cualquier función, un hecho que se demostró más tarde por el Teorema de Aproximación Universal.
Aunque limitado por el poder computacional y los pequeños conjuntos de datos de la época, la retropropagación sentó las bases para las redes neuronales que más tarde dominarían la IA.
Aprende más:
Retropropagación (Wikipedia)
Conclusión: El escenario para la IA moderna
Para la década de 1990, la IA se sostenía sobre dos patas fuertes. Por un lado, algoritmos de aprendizaje automático como árboles de decisión, Bayes Ingenuo y SVMs estaban impulsando aplicaciones en finanzas, atención médica y telecomunicaciones. Por el otro lado, las redes neuronales con retropropagación tenían el poder teórico de aproximar casi cualquier cosa, pero estaban limitadas por los datos y el poder computacional.
Paralelamente a esto, había un hilo más silencioso pero igualmente importante en la modelización del lenguaje. Desde los primeros experimentos de Claude Shannon con la predictibilidad en el texto en inglés hasta los modelos n-gram y la investigación en reconocimiento de voz, la idea de predecir la siguiente palabra se convirtió en una forma práctica de capturar patrones en el lenguaje.
Cuando aparecieron grandes conjuntos de datos en los años 2000 y las GPU desbloquearon la escala, estas tres corrientes comenzaron a converger. Algoritmos impulsados por datos, redes neuronales con retropropagación y la tradición de la predicción de la siguiente palabra se fusionaron en lo que ahora llamamos aprendizaje profundo.
Los humildes comienzos del perceptrón, el rigor de la teoría del aprendizaje estadístico, el avance de la retropropagación y la persistencia de la modelización del lenguaje se unieron para crear los fundamentos de la IA moderna.

En el próximo blog, exploraremos cómo las redes neuronales evolucionaron hacia las CNN, RNN y el aprendizaje profundo, y cómo la necesidad de poder computacional y los cuellos de botella de datos prepararon el terreno para el nacimiento de los transformers.
OPENLEDGER
