
今天我继续避开大词,聊一个更容易被忽略的细节:
AI 每次给出重要答案时,有没有版本酒标?
这里说的不是品牌包装,而是一个很实际的问题:当模型、数据和调用环境都在变化时,我们以后还能不能知道,当时那个答案到底是怎么来的。#ETH
现在很多 AI 产品最让人不踏实的地方,不是它会变。
变是好事。
模型更新,能力提升;数据补充,认知变新;工具升级,执行更顺。这些都应该发生。问题在于,很多变化发生得太安静了。
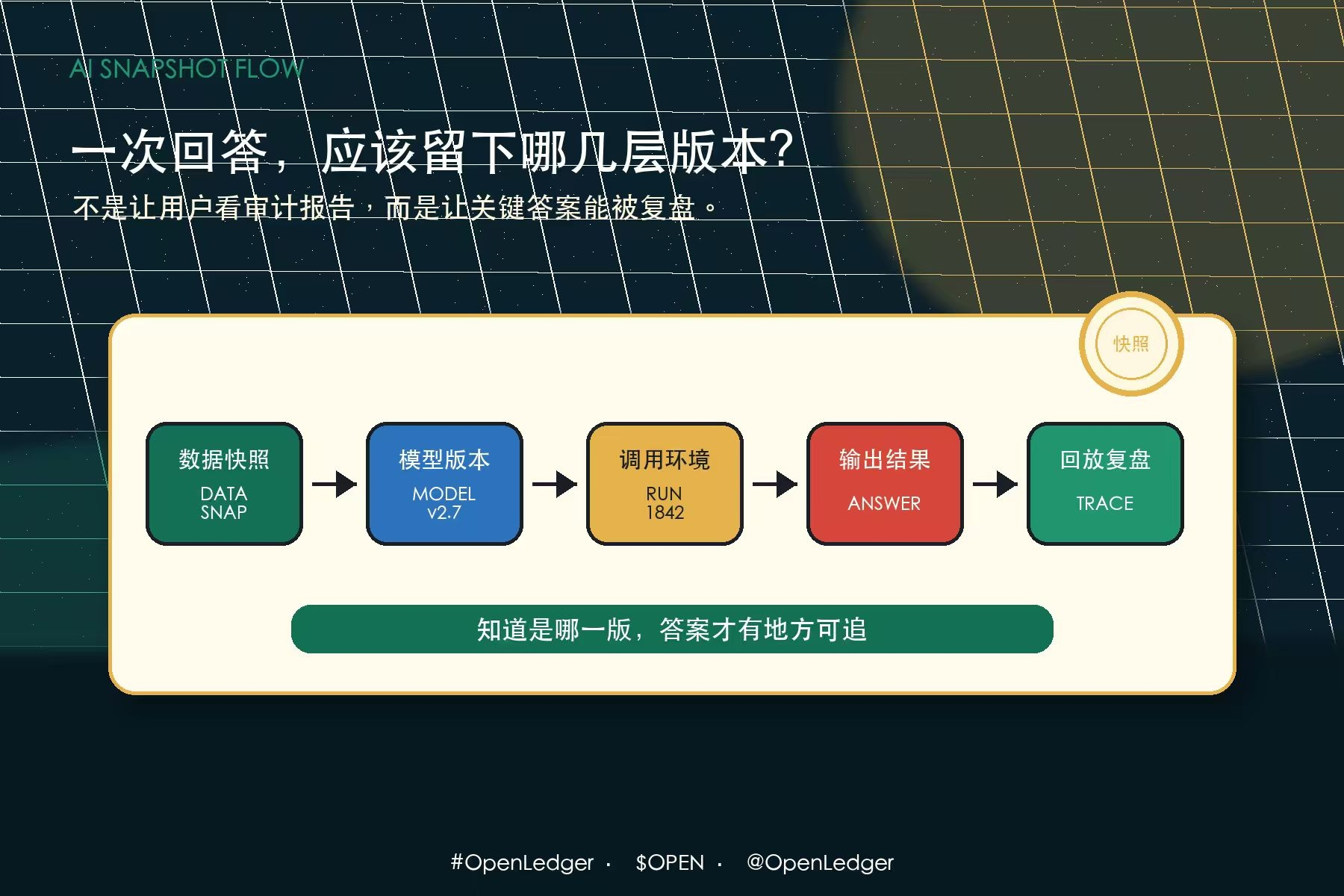
用户只看到今天的答案,却看不到昨天那版系统和今天有什么不同。
比如你让 AI 分析一个 DeFi 项目。
上周它说风险主要在流动性;这周再问,它说风险主要在合约权限。两次回答可能都不是乱说,因为中间数据更新了,模型版本变了,或者调用了不同来源。但如果没有记录,你很难判断这是合理修正,还是回答漂移。
再比如一个 Agent 帮你做链上监控。
同样的地址行为,昨天它判定为正常资金流,今天却打成高风险。你当然可以相信它“更新后更聪明”,但如果你真的要把它接进交易、风控、研究流程,就不能只靠相信。
你需要知道它用了哪版规则、哪批数据、哪次模型调用。
这就是我今天看 @OpenLedger 时想到的地方。
很多人写 OpenLedger,会自然写数据归因、贡献分配、Datanets、Agent 执行。这些方向都重要,但今天我更关心一个偏冷的问题:AI 输出能不能被版本化。#BTC
因为 AI 世界不是静态的。
数据会过期,模型会换版,调用方式会调整,甚至同一个问题在不同时间点也会有不同答案。如果每次变化都没有痕迹,后面就很难复盘。
这对普通用户也有关系。
你不是只想知道 AI 现在怎么说,你还想知道它为什么和之前不一样。
是新数据进入了?
是模型能力升级了?
是之前的来源被替换了?
是某个 Agent 的调用策略改了?
还是只是输出风格变了,看起来更自信,实际依据没变?
这些问题如果没有版本记录,用户只能凭感觉判断。
而凭感觉用 AI,是很危险的。
尤其在 Crypto 这种场景里,信息变化太快。一个项目今天发公告,明天改参数,后天社区又出争议。AI 如果只给你一个当下答案,却不给你看它背后的版本状态,你很难判断这个答案到底有多新、多稳、多可复盘。
所以我觉得 OpenLedger 未来如果要走深,不只是要记录数据从哪里来,也要记录“当时是哪一版世界”。
这个说法听起来有点绕,但其实很好理解。
一瓶酒为什么要有批次?
因为同一个品牌,不同批次也可能有差别。年份、原料、工艺、储存环境,都会影响最后口感。你不能只说“这是茅台”,还得知道是哪一批、什么状态、怎么来的。
AI 也一样。
不能只说“这是模型回答的”。
还要知道是哪版模型,基于哪批数据,调用了什么工具,经过了什么上下文,输出后有没有被反馈修正。
这不是形式主义。
这是未来 AI 真要进入严肃场景时,必须面对的复盘基础。
如果一个 AI 策略建议最后出了问题,用户不可能只接受一句“模型当时判断如此”。如果一个研究结论被反复引用,后面也需要知道它当时依赖的是旧数据还是新数据。如果一个 Agent 持续执行任务,版本变化更应该被记录下来,否则出了偏差根本不知道从哪里查。
我觉得这也是 #OpenLedger 可以和普通 AI 工具拉开距离的地方。
普通 AI 工具更像当场回答。
OpenLedger 如果做得更深,就应该让关键调用留下版本痕迹。数据、模型、调用、反馈、更新,都不是漂在空中的东西,而是可以被回头看的过程。
这样 $OPEN 的意义才不只是挂在文章结尾的标签。
它应该和真实 AI 调用里的可追踪、可复盘、可验证关系绑定。否则数据归因讲得再漂亮,最后用户还是不知道某个答案是在什么版本下生成的。
当然,这件事也不好做。
记录太粗,没用。
记录太细,成本高。
普通用户也不可能每天看一堆技术日志。所以真正难的是,把关键版本信息留下来,但不要把使用体验做得像查审计报告。
这就像酒标。
你不用把整套酿造流程写满瓶身,但关键批次、年份、来源、标准要清楚。懂的人能追,普通人也知道这不是随便贴的标签。
我现在看 OpenLedger,就希望它未来能给 AI 调用留下这种“版本酒标”。
模型可以升级,数据可以变新,Agent 可以换策略。
但每一次关键输出,都应该知道自己来自哪一版。
否则 AI 越聪明,反而越像一张会自己改字的纸。
今天写下的结论,明天它说变就变,后天你再想追,已经找不到当时那一版了。
这不是小问题。
AI 真要进入链上金融、研究、合约、安全这些场景,最终拼的不只是会不会回答,而是回答以后能不能被追溯。
酒可以换批次。
但批次要写清楚。
AI 可以升级。
但升级前后说过什么,也该有人记得。