
Recuerdo cuando todos llamaban a esto "Solo una jugada de eficiencia"
Recuerdo haber visto la primera ola de hype sobre la infraestructura de servicio de modelos y pensando que esto era solo computación en la nube con mejor branding. GPUs compartidas, conmutación más rápida, costos más bajos. Una victoria clara. No había nada más profundo en juego. Estaba equivocado, y me tomó más tiempo del que me gustaría admitir darme cuenta de por qué.
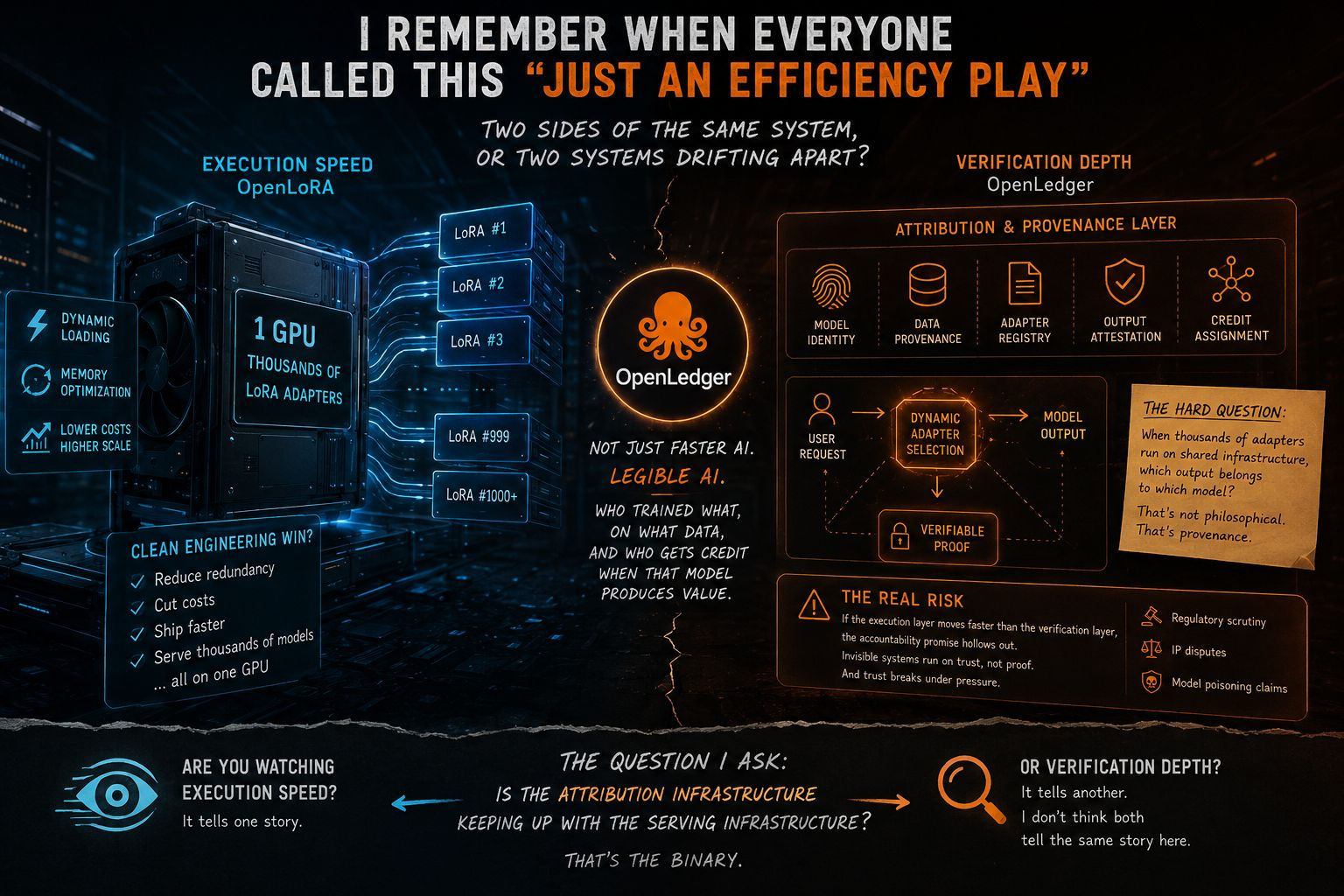
Pero con el tiempo, noté algo que cambió mi perspectiva sobre todo este stack. No se trata de computación. Se trata de propiedad. OpenLedger no está tratando de hacer que la IA sea más rápida; está tratando de hacer que la IA sea comprensible. ¿Quién entrenó qué, con qué datos, y quién recibe crédito cuando ese modelo genera valor? Ese es un problema completamente diferente, y honestamente uno al que nadie le estaba prestando atención mientras todos estaban ocupados comparando la velocidad de inferencia.
El reencuadre importa porque OpenLoRA es realmente impresionante en su superficie. Una GPU, miles de adaptadores LoRA afinados, carga dinámica, optimización de memoria. Cuando lees por primera vez la arquitectura, parece una victoria de ingeniería limpia: reducir redundancias, recortar costos, enviar más rápido. Y probablemente sea todo eso. Pero aquí es donde me quedé estancado: cuando cambias dinámicamente entre miles de adaptadores en una infraestructura compartida, ¿qué salida pertenece a qué modelo? Esa no es una pregunta filosófica. Es una pregunta de procedencia, y en un mundo donde las salidas de IA tienen un peso comercial y legal real, importa mucho.
Desde una perspectiva de mercado, aquí es donde$OPEN lleva una fragilidad real. Si la capa de ejecución se vuelve lo suficientemente abstracta y OpenLoRA está empujando duro en esa dirección, la atribución se vuelve genuinamente difícil. No políticamente difícil. Técnicamente difícil. Cambios en el contexto del adaptador, estados de memoria compartida, ciclos de carga dinámica... cuanto más rápido funciona el sistema, menos visible se vuelve la contribución de cada modelo individual. Los sistemas invisibles funcionan con confianza, no con pruebas. Y la confianza se rompe bajo la presión de un escrutinio regulatorio, disputas de propiedad intelectual, reclamos de envenenamiento de modelos. Si la capa de verificación de OpenLedger no puede mantener el ritmo con cuán abstracta se vuelve la capa de ejecución, la promesa de responsabilidad comienza a vaciarse. Ese es el verdadero riesgo. No la competencia. No los desbloqueos de tokens. La coherencia interna entre lo que el sistema hace y lo que realmente puede verificar.

Así que aquí está lo que realmente observo con$OPEN no el precio, no los anuncios del ecosistema, no los tweets de asociaciones. Observo si la infraestructura de atribución está manteniendo el ritmo con la infraestructura de servicio. ¿Están los constructores enviando herramientas de verificación al mismo ritmo que las herramientas de eficiencia? ¿Está la capa de coordinación volviéndose más legible con el tiempo, o más abstracta? Esa es la binaria para mí. O OpenLedger está construyendo la capa de responsabilidad que hace que OpenLoRA sea confiable a gran escala, o está construyendo una historia de verificación sobre un sistema que ya se ha movido demasiado rápido para verificar completamente.
¿Dos lados del mismo sistema, o dos sistemas separados que se separan? Realmente no lo sé todavía. Pero esa es la pregunta que le haría a cualquier desarrollador que esté construyendo sobre este stack ahora mismo.
¿Estás observando la velocidad de ejecución o la profundidad de verificación? Porque no creo que ambos cuenten la misma historia aquí 👇
