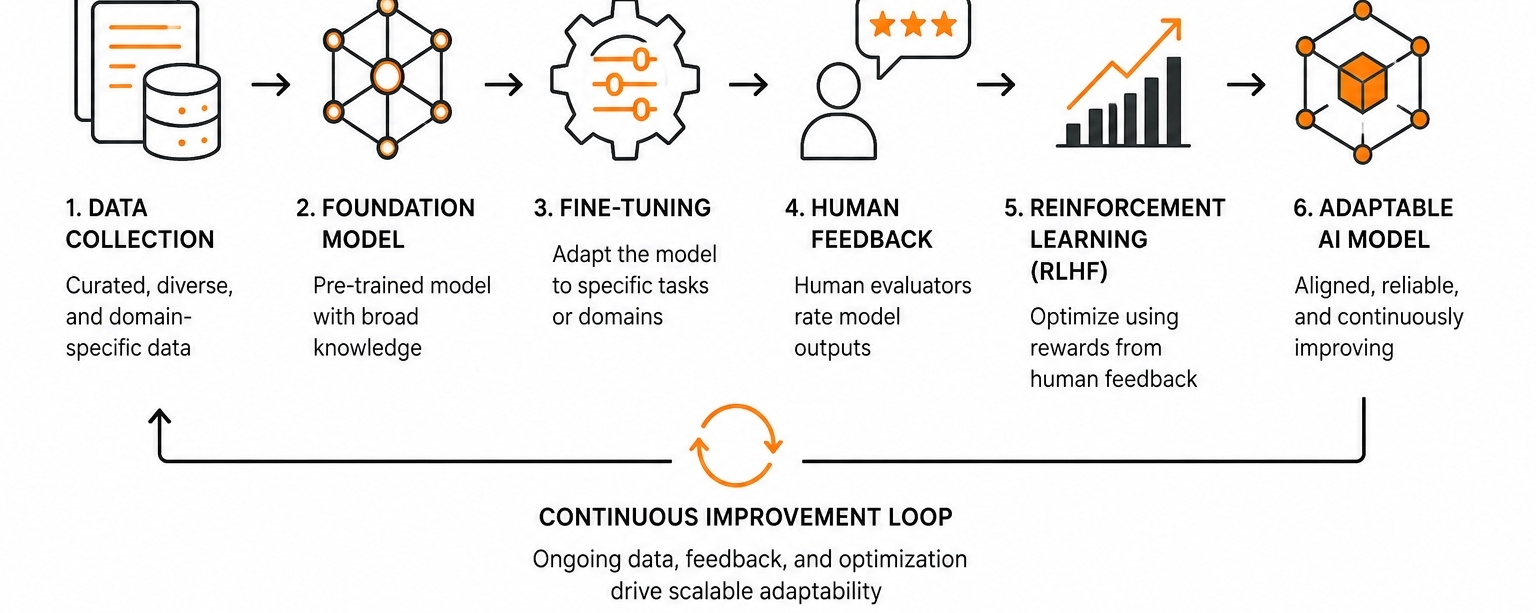
Escalar la adaptabilidad de la IA dentro de OpenLedger no se siente realmente como entrenar un modelo. Se siente más como negociar con un sistema que sigue exponiendo dónde la fiabilidad se quiebra silenciosamente bajo presión. La parte extraña es que la mayor parte de la fricción no es visible desde afuera. La gente suele hablar sobre el ajuste fino y RLHF como si fueran capas de optimización limpias que se sientan ordenadamente sobre la infraestructura, pero dentro de OpenLedger la parte difícil es decidir cuáles salidas merecen refuerzo en primer lugar, especialmente cuando múltiples agentes, conjuntos de datos y validadores están involucrados al mismo tiempo.
Lo que cambió mi perspectiva sobre todo esto fue observar cómo el comportamiento de reintentos lentamente se convirtió en parte del proceso de aprendizaje en sí.
No intencionalmente al principio.
Un modelo podría fallar en una tarea. El enrutamiento redirigiría la solicitud a otro camino de inferencia. Una capa de validadores puntuará las salidas de manera diferente dependiendo de la tolerancia a la latencia, los umbrales de confianza y la precisión histórica previa. Luego, un pase de refuerzo posterior absorbería partes de esa interacción como si la salida final exitosa representara inteligencia limpia en lugar de presión de corrección acumulada. Suena menor hasta que te das cuenta de lo rápido que los sistemas adaptativos comienzan a aprender patrones de supervivencia operativa en lugar de calidad de tarea.
OpenLedger parece consciente de este problema de una manera que la mayoría de los sistemas de coordinación de IA no lo están.
El sistema sigue tratando de separar “salida correcta” de “salida recuperable”. Esas no son la misma cosa una vez que las capas de enrutamiento se vuelven dinámicas.
Un pequeño ejemplo se quedó conmigo porque parecía trivial sobre el papel pero producía un comportamiento muy diferente bajo carga. Durante un flujo de trabajo de clasificación de múltiples pasos, se permitió a un modelo de menor costo un reintento antes de la escalación a un camino de razonamiento más caro. El presupuesto de reintentos redujo sustancialmente el desperdicio de infraestructura porque no cada inferencia fallida activaba inmediatamente un cálculo más pesado. Bueno en teoría. Pero con el tiempo, los validadores comenzaron a recompensar salidas que eran simplemente lo suficientemente estables como para evitar la escalación en lugar de salidas con la mayor profundidad de razonamiento. El sistema estaba optimizando indirectamente para la eficiencia de enrutamiento.
Eso es un peligroso ciclo de retroalimentación.
No catastrófico. Solo sutil.
La capa de refuerzo eventualmente necesitaba lógica de ponderación adicional para distinguir entre “éxito de alta confianza” y “aceptación de baja fricción.” Sin ese ajuste, RLHF comenzó a heredar sesgo de infraestructura. El proceso de aprendizaje ya no estaba moldeado solo por humanos clasificando salidas. Estaba moldeado por economías operativas invisibles dentro de la red.
Esa distinción importa más de lo que la mayoría de las discusiones sobre el ajuste fino de IA admiten.
Mucha gente todavía imagina RLHF como humanos sentados sobre modelos proporcionando alineación de preferencias. En la práctica, una vez que los sistemas se distribuyen a través de capas de enrutamiento, validadores, puntuación de consenso y reintentos adaptativos, el refuerzo comienza a reflejar también los incentivos de infraestructura. OpenLedger expone esto de manera más transparente porque la coordinación en sí misma se convierte en parte de la arquitectura en lugar de estar oculta dentro de la pila interna de una empresa.
Y, sinceramente, no estoy completamente convencido de que alguien sepa cuán estable se vuelve eso a gran escala.
Hay otro problema mecánico que sigue surgiendo. La fiabilidad de múltiples pases suena reconfortante hasta que te das cuenta de que cada capa de validación adicional introduce silenciosamente asimetría temporal. Un camino de inferencia puede producir una respuesta utilizable en 400 milisegundos mientras que otro tarda 2.3 segundos pero puntúa significativamente más alto bajo la revisión del evaluador. Si la capa de enrutamiento sigue priorizando la capacidad de respuesta percibida, el camino de razonamiento más lento gradualmente recibe menos tráfico de refuerzo. No porque sea peor. Porque la paciencia del usuario se convierte en una variable de optimización.
Eso cambia los flujos de trabajo de maneras que la gente rara vez describe claramente.
Comienzas a notar que los operadores diseñan indicaciones de manera diferente simplemente para evitar activar caminos de escalación. Ventanas de contexto más cortas. Formato más limpio. Menos ambigüedad. No porque el modelo fundamentalmente no pueda razonar a través de la complejidad, sino porque la infraestructura circundante castiga la incertidumbre costosa. Después de suficientes ciclos, la adaptabilidad se convierte también en un acondicionamiento conductual parcial para los usuarios.
Esa línea me molestó cuando la escribí por primera vez.
Pero aún creo que es cierto.
Una de las pruebas de estrés más interesantes dentro de OpenLedger involucró desacuerdos de validadores en capas durante el ajuste de adaptación de dominio. Dos validadores clasificaron las salidas de manera diferente porque uno ponderó la densidad fáctica mientras que otro ponderó más la adherencia a las instrucciones. El bucle de adaptación del modelo seguía oscilando entre verbosidad y compresión dependiendo de qué evaluador obtenía influencia temporal durante las ventanas de puntuación de consenso. Podías literalmente ver cómo surgía la deriva de tono a partir de la coordinación de infraestructura en lugar de la intención del modelo.
La solución no fue elegante.
En lugar de intentar crear un evaluador universal, el sistema introdujo rangos de especialización limitados donde ciertos validadores solo influían en el refuerzo bajo contextos de tarea predefinidos. Eso redujo significativamente la contaminación entre dominios. También introdujo un nuevo costo: la complejidad de gobernanza.
Ahora alguien tiene que definir los límites de la autoridad contextual.
Y una vez que eso existe, los sistemas 'abiertos' se vuelven silenciosamente más cerrados de lo que inicialmente parecen.
No gateado políticamente. Gateado operativamente.
Las personas que entienden el comportamiento de enrutamiento, la ponderación de validadores y el derrame de refuerzo comienzan a acumular una influencia desproporcionada sobre los resultados del modelo, incluso si la infraestructura base sigue siendo accesible públicamente. Creo que aquí es donde OpenLedger se vuelve más interesante que su lenguaje de marca. La verdadera historia no es la IA descentralizada. La verdadera historia es cómo las capas de coordinación crean lentamente jerarquías de experiencia ocultas.
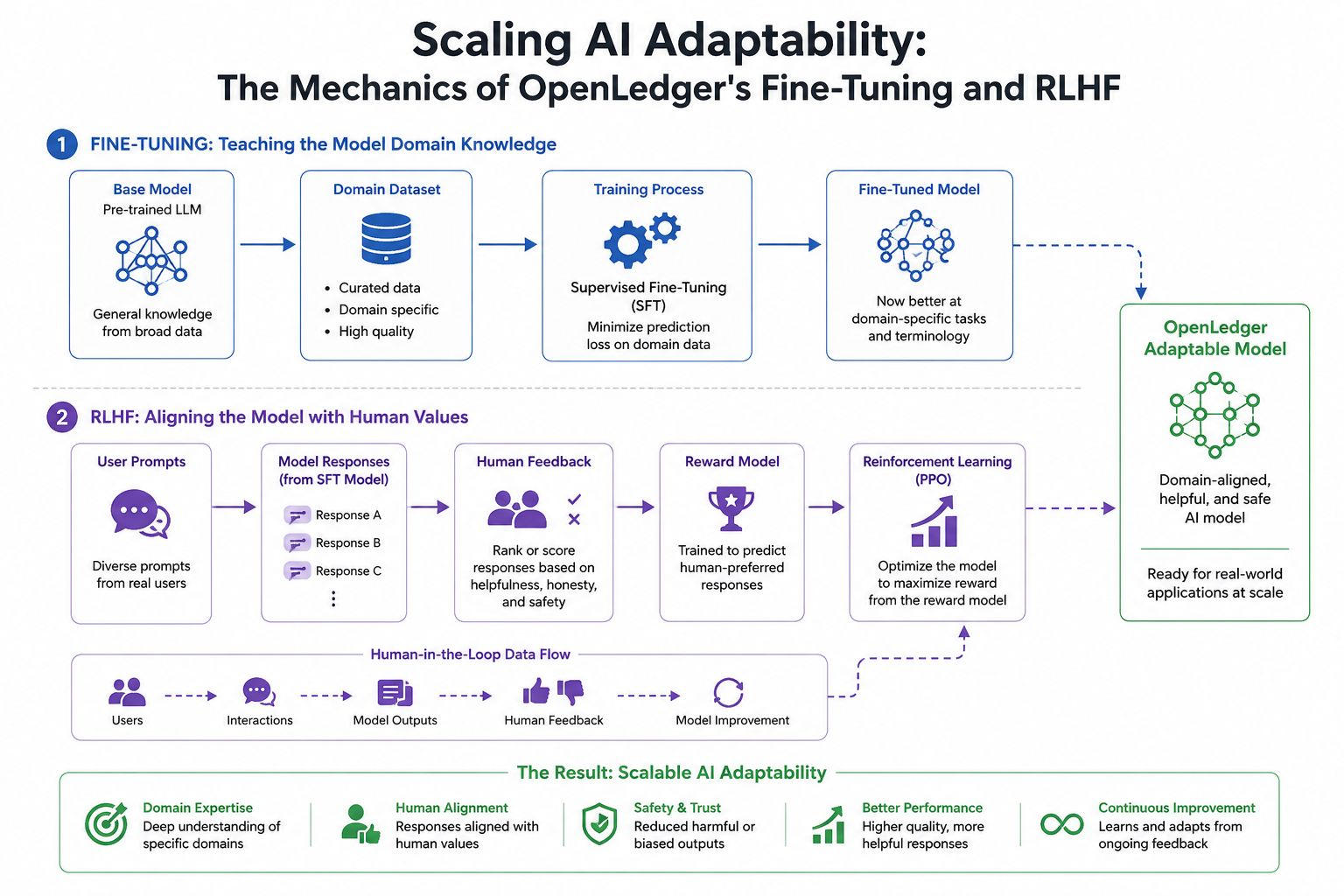
Puedes probar esto tú mismo de maneras más pequeñas.
Intenta alimentar indicaciones estructuralmente similares a través de diferentes niveles de complejidad mientras aumentas ligeramente la ambigüedad en cada ronda. Observa dónde comienzan a aparecer los reintentos. Observa qué salidas se comprimen en lugar de expandirse. Luego repite el mismo flujo de trabajo después de que los cambios en la sintonización del evaluador ocurran. Si la adaptabilidad fuera puramente inteligencia del modelo, esos cambios de comportamiento serían más pequeños de lo que realmente son.
No son pequeños.
Otra prueba útil es observar cómo se comportan los modelos después de una exposición prolongada a entornos con mucha corrección. Los sistemas que reciben constantemente desacuerdos de validadores a menudo se vuelven más conservadores con el tiempo, incluso cuando la creatividad se recompensa nominalmente. La arquitectura de OpenLedger parece resistir eso de alguna manera al distribuir las fuentes de refuerzo, pero la tensión aún existe por debajo. Los modelos adaptativos eventualmente aprenden dónde se concentra la probabilidad de castigo.
Eso crea una extraña compensación en el diseño de RLHF.
Más capas de validación mejoran la fiabilidad contra alucinaciones y salidas de baja calidad. Al mismo tiempo, una evaluación excesiva en capas puede aplanar el razonamiento exploratorio porque las salidas inciertas se vuelven costosas operativamente. En algún lugar en el medio, la adaptabilidad comienza a competir contra la eficiencia de cumplimiento.
Me inclino ligeramente a creer que la industria subestima este problema.
Quizás porque las métricas de infraestructura son más fáciles de cuantificar que la flexibilidad cognitiva.
El token solo comienza a tener sentido una vez que pasas suficiente tiempo mirando estas presiones de coordinación directamente. Sin alguna estructura económica que vincule a evaluadores, validadores, proveedores de enrutamiento y contribuyentes al ajuste fino, la capa de refuerzo eventualmente colapsa en arbitraje centralizado de todos modos. El modelo de token de OpenLedger se siente menos como un truco de incentivos y más como un intento de evitar que el trabajo de coordinación invisible se convierta en infraestructura extractiva propiedad de una clase operadora estrecha.
Si eso realmente funciona a largo plazo es más difícil de responder.
Especialmente una vez que la optimización adaptativa comience a recompensar a los participantes que entienden mejor la mecánica del sistema que la calidad del modelo en sí.
Sigo pensando en eso porque se extiende más allá de OpenLedger. Cualquier red de IA con enrutamiento en capas y refuerzo eventualmente desarrolla comportamientos de supervivencia internos. Algunos se vuelven eficientes. Algunos se vuelven frágiles. Algunos entrenan silenciosamente a los usuarios para pensar en formatos compatibles con máquinas mientras comercializan el proceso como adaptabilidad.
Y tal vez esa sea la parte incómoda.
El ajuste fino ya no se trata solo de cambiar el modelo.
El sistema circundante también sigue siendo entrenado.
