Hace unos años, si un modelo de IA alcanzaba la cima de un ranking de benchmarks, probablemente lo habría aceptado al pie de la letra. La mayoría de la gente lo hizo. Una puntuación más alta significaba un mejor modelo. Lógica simple.
Ahora estoy mucho menos convencido.
Lo extraño de los sistemas de puntuación es que, una vez que suficiente dinero empieza a reaccionar a ellos, las puntuaciones en sí mismas dejan de ser mediciones neutras. Se convierten en incentivos. Y una vez que aparecen los incentivos, el comportamiento cambia a su alrededor.
Puedes ver este patrón en todas partes.
Las escuelas optimizan para los exámenes en lugar de la comprensión.
Las empresas optimizan la óptica trimestral en lugar de la salud a largo plazo.
Los mercados se agrupan alrededor de la liquidez visible porque los traders saben que todos los demás están observando los mismos niveles.
La IA parece estar alejándose lentamente hacia la misma trampa.
Los puntos de referencia parecen objetivos desde afuera. Gráficos limpios, porcentajes, clasificaciones, tableros de líderes. A los inversionistas les encantan porque comprimen la complejidad en algo fácil de entender. Las narrativas de los medios también se simplifican. Una captura de pantalla puede definir de repente qué modelo parece 'el mejor'.
Pero los números también pueden crear una falsa confianza.
Porque el verdadero problema no es que exista la optimización de puntos de referencia. Por supuesto que existe. Si los desarrolladores entienden exactamente cómo funcionan los sistemas de evaluación, ¿por qué no optimizarían hacia esas superficies? En muchos casos, eso es simplemente competencia racional.
El problema comienza cuando la optimización y la fiabilidad se separan silenciosamente entre sí.
Y, honestamente, esa brecha importa mucho más de lo que la mayoría de la gente se da cuenta.
Un modelo puede tener un rendimiento extremadamente bueno dentro de entornos de referencia controlados mientras crea fracasos costosos en flujos de trabajo del mundo real. Sistemas legales, entornos de salud, automatización empresarial, análisis financiero — estas son áreas donde las salidas poco confiables generan costos a posteriori que alguien eventualmente tiene que absorber.
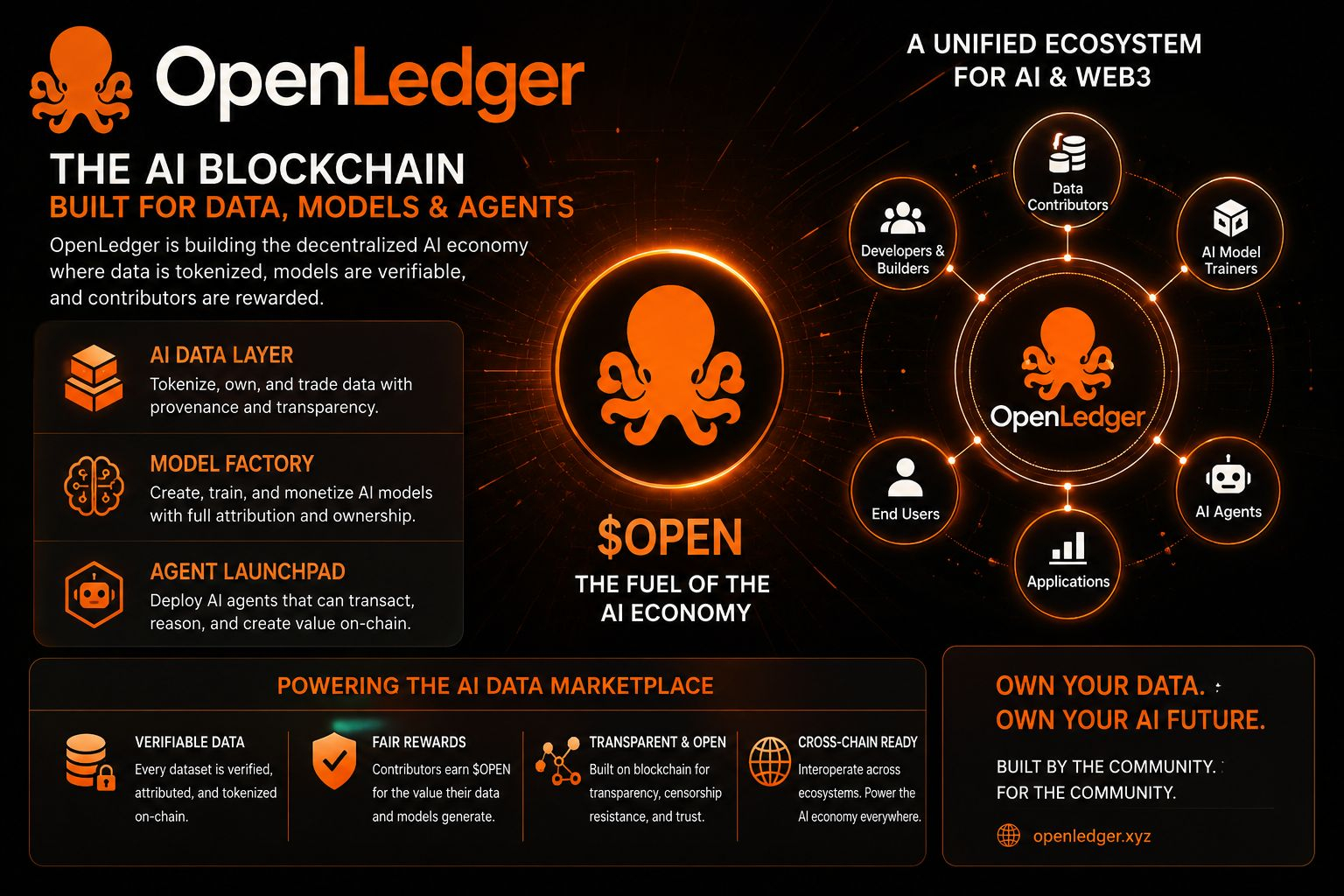
Ahí es donde @OpenLedger se vuelve mucho más interesante para mí que las narrativas típicas de IA flotando alrededor de cripto.
La mayoría de la gente enmarca OpenLedger alrededor de infraestructuras de IA descentralizadas, datanets, sistemas de atribución o coordinación de agentes. Pero creo que la idea más profunda puede girar en torno a la responsabilidad bajo presión económica.
Porque el juego de referencias no es realmente solo un problema de medición.
Es un problema de incentivos.
En este momento, si las empresas optimizan agresivamente las narrativas de rendimiento y se comercializan a través de la superioridad de referencias, ¿qué sucede estructuralmente cuando esas afirmaciones fallan bajo condiciones de uso en el mundo real?
Generalmente… no mucho.
Quizás sea el daño a la reputación.
Quizás algunos conflictos legales.
Quizás los usuarios se muevan silenciosamente a otro lado.
Pero rara vez hay una capa económica explícita que conecte la credibilidad del rendimiento directamente con la responsabilidad.
Ahí es donde la arquitectura de atribución de OpenLedger comienza a verse mucho más importante.
Si la línea de modelo, la procedencia de contribuciones, la historia de validación, o la calidad de salida se vuelven trazables económicamente, entonces la credibilidad comienza a tener peso medible. En ese punto, las afirmaciones de referencia dejan de funcionar puramente como activos de marketing y comienzan a interactuar con la infraestructura de reputación.
Y eso cambia el comportamiento.
Quizás el verdadero valor no sea crear 'mejor IA'.
Quizás se trate de crear sistemas donde la optimización deshonesta se vuelva económicamente costosa.
Esa es una tesis muy diferente.
Porque una vez que la responsabilidad se vuelve persistente, los incentivos cambian. Las afirmaciones de rendimiento se vuelven más pesadas. La verificación importa más. Los compradores confían menos en capturas de pantalla pulidas de tableros de líderes y más en la fiabilidad operativa demostrable.
Y, honestamente, eso se siente más cerca de hacia dónde se mueven eventualmente los mercados de IA maduros.
Especialmente una vez que los sistemas de IA se integran profundamente en industrias reguladas donde la confianza ya no es filosófica. Salud, finanzas, cumplimiento, gobernanza empresarial — estos entornos se preocupan menos por demostraciones llamativas y mucho más por consistencia, trazabilidad y responsabilidad.
Por supuesto, todavía hay grandes desafíos.
¿Quién define puntos de referencia confiables?
¿Cómo verificas la calidad sin exponer sistemas sensibles?
¿Puede la infraestructura de atribución escalar sin crear una complejidad operativa masiva?
Y lo más importante: ¿se convierte $OPEN en una infraestructura económicamente necesaria o simplemente en una infraestructura simbólica a la que la gente hace referencia sin depender de ella?
Esa distinción importa mucho.
Aún así, sigo regresando a un pensamiento:
El mercado aún se comporta como si la competencia de IA se tratara principalmente de la inteligencia misma — razonamiento más inteligente, modelos más grandes, mejores demostraciones.
Pero quizás lo que sea más escaso a largo plazo no sea la inteligencia.
Quizás sea una responsabilidad creíble.
Y si los sistemas de referencia se comportan cada vez más como herramientas de persuasión en lugar de herramientas de medición honestas, entonces una infraestructura que haga que la credibilidad tenga sentido económico podría importar mucho más que otra actualización incremental de modelo.
Esa posibilidad me parece mucho más interesante que otra captura de pantalla de un tablero de líderes.#OpenLedger #openledger $OPEN @OpenLedger $BTC